- Detalles
- Categoría: Comsol
- Visto: 5225
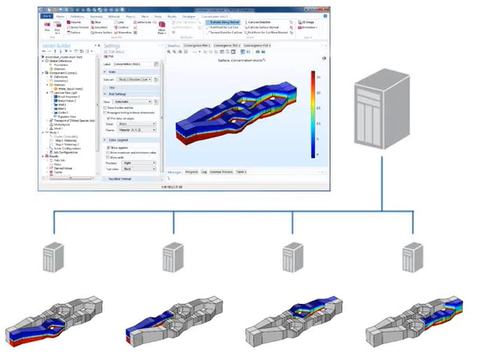
COMSOL soporta dos modos de cálculo en paralelo: operaciones paralelas de memoria compartida y operaciones paralelas de memoria distribuida, incluyendo el soporte para clústeres.
La posibilidad de paralelizar los cálculos en un clúster con el modo de memoria distribuida puede que sea una de las funcionalidades más potentes y a la vez desconocidas para una parte de los usuarios de COMSOL Multiphysics.
COMSOL puede distribuir cálculos en un clúster de computación utilizando MPI. De esta forma un problema grande puede ser distribuido en muchos nodos de computación. Existen multitud de tipos de análisis que por sus dimensiones pueden beneficiarse de correr la simulación de COMSOL Multiphysics® en un hardware de computación de alto rendimiento (HPC). Por eso en COMSOL Multiphysics® existe el nodo Cluster Computing, que ayuda a integrar fácilmente el software COMSOL con cualquier infraestructura HPC, a la vez que mantiene la conveniencia de una interfaz gráfica de usuario. En la entrada del Blog de COMSOL "How to Run on Clusters from the COMSOL Desktop® Environment", Lars Drögemüller nos enseña cómo correr grandes simulaciones de forma remota sobre un hardware HPC directamente desde el entorno gráfico COMSOL Desktop.
Por otro lado en la base de conocimiento de la zona de soporte técnico en la web de COMSOL está disponible un extenso artículo donde se explican los fundamentos para configurar COMSOL y lanzar simulaciones sobre clústeres.
Si está interesado en utilizar COMSOL para correr grandes simulaciones en ordenadores de alto rendimiento, visite las entradas del blog y la base de conocimiento de COMSOL para entender cómo se configura el entorno y se pueden aprovechar todas las funcionalidades pensadas para este fin en COMSOL Multiphysics.
- Detalles
- Categoría: Comsol
- Visto: 4746
Todos los productos de software COMSOL® han recibido mejoras de estabilidad que se han introducido como actualizaciones. La siguiente lista contiene las mejoras más importantes en la versión 5.5 update 2 de COMSOL® (incluyendo las de la "update 1").
COMSOL Multiphysics®
- Para el complemento del Controlador PID, los coeficientes de los términos proporcional e integral han cambiado los signos para adecuarse a las convenciones estándar, y ya no es necesario especificar unidades para los coeficientes o términos con el valor 0.1
- Los requisitos del sistema para el gestor de licencia han sido ampliados para ahora soportar también Debian® 6, Red Hat® Enterprise Linux®/CentOS 6, y SUSE® Enterprise Linux® 11.4 y más nuevos.1
- Solucionado un problema con la evaluación de las derivadas temporales de variables dependientes de una solución en el dominio de la frecuencia diferente utilizando el operador
withsol durante el montaje.2 - Mejora de la acción de refresco de la ventana de Bibliotecas de Aplicaciones.2 Deshabilitado el botón Ejecutar la aplicación en la ventana de Bibliotecas de Aplicación para la previsualización de la aplicación.2
- Actualizado el servidor Tomcat a la versión 7.0.99.2
- Reducido el relleno de la ventana para aplicaciones que corren en un navegador web.2
- Presionando la tecla X, Y, o Z para controlar la rotación en la ventana Gráficos ahora funciona en macOS.2
- La secuencia del resolvedor ahora muestra el formato de almacenamiento que será utilizada cuando se corra en un clúster.2
- Se ha solucionado un problema donde una instancia de COMSOL® corriendo podría perder contacto con el servidor de licencia si el archivo de licencia se cambiara en el servidor de licencias.2
- Mejoras de rendimiento.2
COMSOL Compiler™
- Para aplicaciones compiladas independientes con la opción Descargar, la descarga de COMSOL Runtime™ es más estable.2
COMSOL Server™
- Actualizado el servidor Tomcat server a la versión 7.0.99.2
AC/DC Module
- Mejora de estabilidad de la limpieza de divergencia para bobinas de contorno con cortes de simetría.2
- Corrección de un problema con el cálculo de flujo concatenado preciso para bobinas de contorno.2
Acoustics Module
- El cálculo del tiempo de llegada de rayos en el conjunto de datos Receptor ha sido mejorado para dar resultados más precisos para el sonido directo y para rayos que sufren reflexiones en un contorno cercano al receptor.2
Batteries and Fuel Cells Module
- Nuevo material de elctrodo (NMC 811) añadido a la biblioteca de materiales de Batteries & Fuel Cells.2
CAD Import Module, Design Module and LiveLink™ Modules para CAD
- The CAD file import functionality has been extended to support new versions for the following file formats:2
- ACIS® (.sat, .sab, .asat, .asab): 2020 1.0
- AutoCAD® (.dxf, .dwg): 2020
- Inventor® (.iam, .ipt): 2020
- NX™ (.prt): 1872
- SOLIDWORKS® (.sldprt, .sldasm): 2020
CFD Module
- Definición de velocidad de deslizamiento fija en el acoplamiento multifísico Mixture Model para Transporte de Fase.2
- Definición de coeficiente de arrastre fija para el modelo Haider–Levenspiel en el acoplamiento multifísico Mixture Model para Transporte de Fase.2
Composite Materials Module
- Ampliado el número de configuraciones soportadas para hendiduras en materiales compuestos.2
File Import for CATIA® V5
- Se ha añadido el soporte para importar archivos de CATIA® V5 (.CATPart, .CATProduct) versió 2020.2
Heat Transfer Module
- Para radiación en medios semitransparentes, las propiedades dependientes de la longitud de onda para geometrías 2D con simetría axial ahora estan habilitadas.1
- El coeficiente de transferencia de calor para una cama de gránulos esféricos en la interfaz multifísica No equilibrio térmico local, ha sido corregido.2
- Definición de variables fijas en interfaces de dominio isotérmico para acoplamiento con radiación superficie a superficie.2
LiveLink™ for MATLAB®
- Exporting animations from MATLAB® now works when the server is running on another computer.2
Nonlinear Structural Mechanics Module
- Ahora se puede calcular plasticidad en la interfaz Cáscara con múltiples interfaces. Previamente, aplicar plasticidad en varios dominios asociados con diferentes materiales generaba un error sobre duplicidad de nombres de variables.2
Optimization Module
- Los métodos de optimización libres de derivadas ahora soportan la funcionalidad de optimización de forma Polynomial Boundary.1
Particle Tracing Module
- Al utilizar la formulación Massless y permitiendo grados de libertad fuera de plano en las interfaces de Trazado de Partículas con Carga o Trazado (Rastreo) de Partículas para Flujo de Fluido, ahora se puede especificar la componente de velocidad fuera de plano en la ventana de Ajustes de las Propiedades de la Partícula. Anteriormente, únicamente se mostraban las componentes en el plano.2
- Solucionado un error donde los ajustes para la distribución lognormal de diámetros de partícula no aparecían de forma apropiada en los ajustes de la funcionalidad Liberar desde archivo de datos.2
- Solucionado un error en la visualización de la ecuación para el nodo Boundary Load en la interfaz de Trazado de Partículas para Flujo de Fluido.2
- Asegurado que la fuerza acustoforética pueda tomar el valor correcto de la frecuencia utilizada para calcular el campo de presión acústica, incluso si el estudio en el dominio de la frecuencia para acústica de presión no precede inmediatamente al estudio dependiente del tiempo para el trazado de partículas (por ejemplo, si hay Study 1 y Study 3 en un modelo).2
- El software ahora deshabilita automáticamente el nodo de Simetría en las interfaces de Trazado de Partículas con Carga y el Trazado de Partículas para Flujo de Fluido si se utiliza la formulación sin Masa. 2
- Solucionado un error que ocurre cuando se selecciona una distribución de velocidades de partículas inicial y entonces se cambia la formulación a Massless.2
- Cuando se utiliza el método de colisión nula para modelado de colisiones Monte Carlo con la interfaz Trazado de Partículas con Carga, la elección de aplicar las colisiones a únicamente una única especie ahora se respeta.2
- Solucionado un error que ocurría al utilizar las opciones para incluir efectos de rarefacción y para especificar una distribución de diámetros de partícula en la interfaz Trazado de Partículas para Flujo de Fluido.2
- Mejora en la robustez de las funcionalidades de Contador de Partículas y Detector de Rayos al utilizarlos con un barrido paramétrico sobre valores de parámetros múltiples.2
Porous Media Flow Module
- Ahora están disponibles las siguientes condiciones de dominio y de contorno adicionales para la interfaz de Transferencia de calor en fracturas con licencias de Subsurface Flow Module o el Porous Media Flow Module:2
- Dominios: Fuente de calor
- Contornos: Temperatura, Flujo de calor, Fuente de calor, y Radiación superficie a ambiente
Ray Optics Module
- Solucionado un error en la liberación de órdenes de difracción desde una rejilla o rejilla cruzada cuando la reflectancia o transmitancia de un orden dado (pero no ambos) son exactamente cero.2
- Solucionado un error en la perturbación debida a la rugosidad de la superficie para la funcionalidad de Superficie iluminada en 2D.2
- Solucionado un error cuando la casilla Incluir rugosidad de superficie se seleccionó en alguno, pero no todos, de los nodos de Superficie iluminada en un modelo de óptica geométrica.2
- Solucionado un fallo cuando se añadía un atributo Altura al gráfico de Aberración óptica, mientras también se aplicaba un filtro a los rayos.2
- Ajuste de la visualización de la ecuación para el nodo de Discontinuidad del material de forma que los símbolos para los coeficientes de transmisión y reflexión sean más consistentes.2
- Para las funcionalidad es liberación de rayos que mustran el número total de rayos liberados en una distribución cónica, el número mostrado ahora se actualiza correctamente cambiando el número de ángulos acimutales o polares.2
- Solucionado un error en la visualización de la ecuación para el nodo de Orden de Difracción en la interfaz de Óptica geométrica.2
- Cuando se liberan rayos con una de las distribuciones cónicas, Hexapolar o Especificar distribuciones polar y acimultal, ahora se puede entrar cero en el número de ángulos polares. Esto causará que un único rayo sea liberado a lo largo del eje del cono.2
RF Module
- Solucionado un error que resultaba en grupos de gráficos Polares o de Smith vacíos cuando se renderizaban en el cliente web.2
Semiconductor Module
- Solucionado un error en la actualización 5.5 update 1 que no permitía la selección de la opción de tunelado WKB en contactos Schottky.2
- Mejora en la estabilidad para casos muy raros de interferencia entre el Plasma Module y el Semiconductor Module.2
Structural Mechanics Module
- Corregido un problema donde ocurría un error cuando se generaba una secuencia de resolvedor de Frecuencias Propias. Esto podía ocurrir en algunos ordenadores si se seleccionaba una coma como el separador decimal en los ajustes del sistema.2
- Corregido un problema donde la integración en los operadores
rms ym para vibración aleatoria podía devolver resultados erróneos.2
1Nuevo en actualización update 1 2Nuevo en actualización update 2
ACIS es una marca registrada de Spatial Corporation. Autodesk, el logo Autodesk, AutoCAD, e Inventor son marcas registradas o marcas de Autodesk, Inc., y/o sus subsidiarias y/o afiliadas en EE.UU. y/o otros paises. CATIA es una marca registrada de Dassault Systèmes o sus subsidiarias en EE.UU. y/o otros paises. Debian es una marca registrada de marca de Software en el Public Interest, Inc. en Estados Unidos. Linux es una marca registrada de Linus Torvalds en EE.UU. y otros paises. Microsoft, Excel, y Windows son marcas registradas o marcas de Microsoft Corporation en los Estados Unidos y/o otros paises. macOS es una marca de Apple Inc., en los EE.UU y otros paises. MATLAB es una marca registrada de The MathWorks, Inc. NX es una marca o marca registrada de Siemens Product Lifecycle Management Software Inc. o sus subsidiarias en los Estados Unidos y en otros paises. Red Hat Enterprise Linux es una marca registrada de Red Hat, Inc. SOLIDWORKS es una marca registrada de Dassault Systèmes SolidWorks Corp. SUSE es una marca registrada de SUSE LLC.
- Detalles
- Categoría: Minitab
- Visto: 5944

Por Joshua Zable.
¿Ha oido hablar alguna vez de la Pera Cocodrilo? Si no, no se preocupe ¡No está solo! Sorprendentemente es otro nombre para el aguacate.
Tan de moda como se han convertido los aguacates últimamente, han existido y han sido utilizado en platos populares de todo el mundo durante cientos de años. El guacamole, por ejemplo, lo crearon los Aztecas y data de algún tiempo ¡por allá entre los siglos XIV y XVI! A medida que esta deliciosa salsa verde y otros platos pesados de aguacate continúan ganando popularidad, la demanda de aguacates aumenta. Con un suministro limitado, el coste aumenta y crea problemas para los consumidores, restaurantes y fabricantes de alimentos, en igual medida.
Un sencillo cambio: ¿calabacines por aguacates?
Dado el precio vertiginoso de los aguacates gracias a la demanda mundial, un fabricante de guacamole decidió ver si podían sustituir algunos aguacates en su guacamole por calabacines, o calabacitas, una calabaza mexicana de color verde brillante con características similares; un truco que a veces se usa en la industria de restaurantes.
Sin embargo, con un público fiel, al fabricante le preocupaba cambiar la receta y poner en riesgo su marca. El fabricante de guacamole decidió realizar una prueba y pedirle a un grupo de muestra que probara y clasificara su receta de guacamole "clásica" frente a su receta "nueva" con aguacates y calabacines.
Como experto en marketing, sé que una de las campañas de marketing más atrevidas y convincentes es que un fabricante de alimentos realice pruebas de sabor comparando sus alimentos con la competencia. Además de ser una herramienta de marketing, las pruebas de sabor pueden ayudar seriamente a los restaurantes a introducir nuevos alimentos y probar nuevas recetas. Y los fabricantes de alimentos pueden usar pruebas de sabor para sustituir los ingredientes por una serie de resultados beneficiosos, que incluyen hacerlos más saludables o menos costosos de producir.
Los restaurantes introducen cambios en su menú y confían en el boca a boca del personal o los clientes para determinar si los nuevos elementos del menú están a la altura. Las cadenas y fabricantes más grandes pueden probar alimentos en mercados de muestra. Los tests-T son una forma sencilla de realizar una prueba de sabor, sin importar cuán grande o pequeña sea su operación.
El fabricante de guacamole reune a gente para su prueba de sabor, hace que clasifiquen a los dos guacamoes y empieza a recopilar datos, pero sin ningún antecedente estadístico, ¡recurren a Miniteab para obtener ayuda con sus test-T!
¿Poner tu prueba de sabor ... en el Test estadístico!
Para comparar con precisión las formulaciones de los dos productos, pedimos a 25 panelistas que probaran ambas recetas la Clásica y la Nueva y que punturaran el gusto en una escala del 1 al 10, donde 10 era la que tenía el mejor sabor.
Sabiendo que necesitábamos minimizar el sesgo, aleatorizamos el orden en el que los panelistas probaban las recetas de forma que aproximadamente la mitad del grupo probó primero la Clásica, mientras que lo otra mitad probó primero la Nueva. También tapamos las dos formulaciones durante la prueba para eliminar cualquier opinión preconcebida que los panelistas puedieran tener sobre ambas.
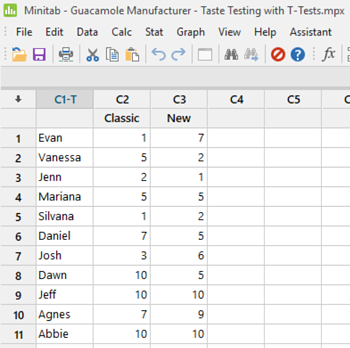
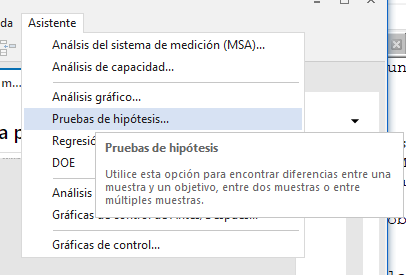
Los datos eran fáciles de entrar, como se puede ver arriba a la izquierda. Para analizar estos datos, el Asistente de Minitab puede guiar y ayudar con el análisis y el informe de resultados. Pasando por encima del menú de Pruebas de Hipótesis, mostrado arriba a la derecha, el Asistente explica alguna de las opciones.
Cuando se hace clic en la Prueba de Hipótesis se abre una nueva ventana que presentará un mapa preguntando qué se desea hacer. En nuestro ejemplo de prueba, queremos comparar las dos muestras entre sí.
En este caso, sabemos que queremos comparar dos muestras entre sí, pero como estamos utilizando Minitab para el análisis, no estamos seguros de qué opción es la apropiada así que clicamos "Ayudarme a elegir" bajo el Asistente de Minitab "Comparar dos muestras entre sí."
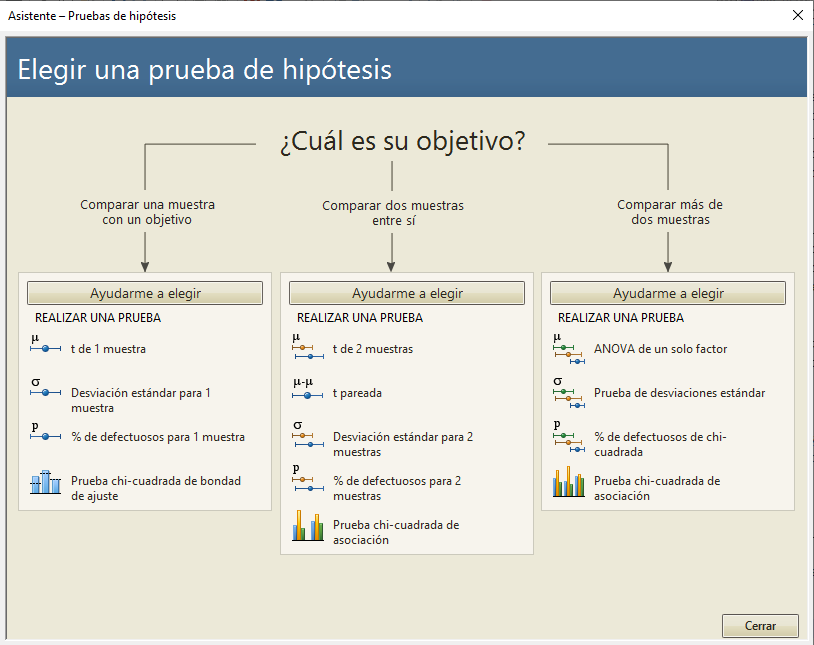
Ahora también sabemos que cada panelista probó ambas recetas, así que queremos comparar las medias de la receta para unos elementos de conjunto coincidentes. La T pareada es la prueba apropiada aquí porque considera que las observaciones en las columnas Clásica y Nueva no son independientes, ya que cada panelista puntuó a ambas recetas.
Una receta para resultados maduros
Después de que Minitab corriera el análisis, me emocioné al ver los resultados. El informe resumido de Minitab me dice que la media de la clásica no es significativamente diferente que la media de la Nueva. Minitab calcula las diferencias para cada fila, con esas diferencias se representa en el histograma. la diferencia promedio es muy cercana al cero (-0.16) y el intervalo rojo proporciona un rango para la diferencia de medias verdadera, diciéndome que las dos recetas no son diferentes después de todo. ¡Esto significa que mis probadores no pueden detectar una diferencia entre las recetas!
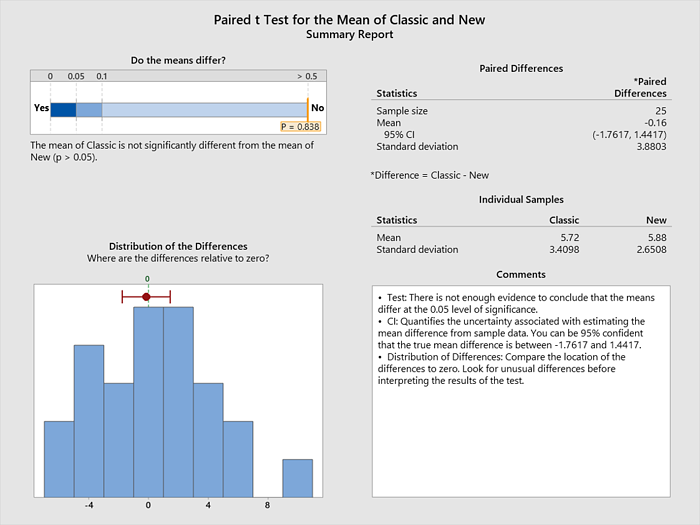
Antes de entusiasmarme demasiado con los resultados, necesito verificar que mi prueba tenga la potencia adecuada. La potencia estadística es la probabilidad de detectar un efecto, suponiendo que existe. Quiero evitar el error de suponer que no hay diferencia entre las recetas basadas únicamente en el hecho de que tuve un experimento débil. Minitab ayuda fácilmente a calcular la probabilidad de detectar la diferencia práctica entre las recetas utilizando el Informe de Diagnóstico de Minitab.
Dado el tamaño de mi muestra, tenía un 87% de probabilidad de detectar la diferencia, tal y como se muestra abajo. Esto me indica que mi prueba no era débil, significando que tenía la potencia adecuada para detectar una diferencia entre las recetas.
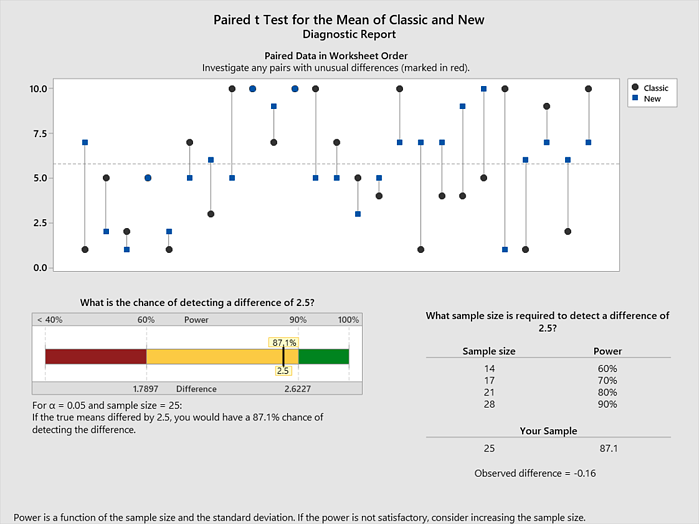
A medida que leo más abajo la tarjeta del informe, me informan que no hay puntos de datos inusuales y que la normalidad no es un problema. Reitera que tenía un 87.1% de posibilidades de detectar una diferencia y que algunos profesionales creen que un 80% de posibilidades de detectar es suficiente, por lo que puedo confiar en los resultados originales y en mi conclusión.

Decisión final deliciosa
¡Este experimento fue un gran éxito gracias a las estadísticas básicas! Basándose en los resultados finales y en la verificación del experimento, descubrimos que el fabricante de guacamole puede cambiar su producto con la nueva receta con los calabacines y el aguacate mezclados con la confianza de que podrán mantener bajos sus costes de fabricación sin sacrificar el sabor.
- Detalles
- Categoría: Comsol
- Visto: 6095
.png)
Aunque la simulación con COMSOL Multiphysics se utiliza para predecir el funcionamiento de un componente dentro de un entorno virtual, la podemos utilizar también para realizar análisis de sensibilidad.
El análisis de sensibilidad juega un papel de gran importancia en ingeniería para ayudar a los ingenieros a obtener un mayor conocimiento de comportamientos complejos del modelo y tomar decisiones informadas sobre dónde emplear el esfuerzo de ingeniería.
El dominio de aplicación del análisis de sensibilidad es muy amplio y permite cuantificar el impacto de las incertidumbres en variables aleatorias sobre la incertidumbre en los resultados del modelo. Las funciones de sensibilidad llevan información muy valiosa para la síntesis de sistemas de control automático. Si se desarrollan métodos informáticos adecuados para el cálculo de funciones de sensibilidad en sistemas no lineales de orden superior, el análisis sistemático de sensibilidad se convertirá en una práctica habitual en el diseño de ingeniería.
Kristian Ejlebjaerg Jensen nos explica en su entrada del blog de COMSOL cómo realizar un análisis de sensiblidad en COMSOL Multiphysics, a través del ejemplo de la flexión y torsión de una torre de armadura.
- Detalles
- Categoría: Minitab
- Visto: 4485

Por Evan McLaughlin
¿Por qué tantos programas de mejora finalmente acaban en el patíbulo? Los líderes de las empresas a menudo patrocinan estos esfuerzos al principio, entonces, ¿qué es lo que pasa entre el día que arranca un desarrollo con el soporte entusiasta de la alta dirección y el día en que se le desenchufa?
Hasta proyectos que dan como resultado mejoras en el mercado a menudo fallan al no dejar impresionados a los que toman las decisiones.
Pero, ¿por qué?
Bien, el éxito del programa a menudo permanece invisible para los que están arriba. en su informe 2020 Global State of Process Excellence, Process Excellence Network dijo que el mayor reto que tienen que encarar los profesionales de procesos es "Enlazar la mejora del proceso con la estrategia de negocio de alto nivel". Esto tampoco es nada nuevo — las respuestas de su encuesta realmente han mostrado que este ha sido el mayor reto durante al menos tres años.
Además, la investigación de la American Society for Quality ha mostrado que únicamente el 25% de los ejecutivos sénior reciben métricas sobre el desarrollo del proyecto ni siquiera anualmente. Es fácil de adivinar que ellos toman decisiones que impactan sobre esos programas con mucha más asiduidad!
Incluso en organizaciones con programas de mejora continua maduros, calcular el impacto acumulativo de una iniciativa puede ser difícil, y a veces imposible.
Encontramos estas 5 razones, y tenemos varias sugerencias sobre cómo evitarlas.
1. Los datos del proyecto están dispersos e inaccesibles
|
|
Los equipos de proyectos individuales normalmente hacen un gran trabajo capturando e informando sus resultados, pero las dificultades surgen rápidamente cuando se acumulan proyectos. Una empresa grande puede tener miles de proyectos simultáneos activos en un momento dado, e innumerables más ya completados. Recoger la información crítica de todos ellos y entonces ponerla en un formato a la que los directivos puedan acceder y usar fácilmente es una tarea extremadamente desalentadora. Muchas organizaciones simplemente fallan en hacer esto, y el impacto global de sus programas siguen siendo un misterio. |

2. Los proyectos son un batiburrillo de aplicaciones y documentos
|
En la mayoría de las organizaciones, los equipos tienen que utilizar una serie de aplicaciones separadas para los documentos, mapas de procesos, mapas de cadena de valor y otras herramientas de proyectos esenciales. Esto significa que el registro del proyecto se convierte en una compilación de archivos distintos, fecuentemente incompatibles, de muchos programas de software diferentes. Entonces, los miembros del equipo se ven forzados a perder el tiempo y su energía entrando la misma información en múltiples aplicaciones. Para aumentar esta confusión, las últimas versiones de documentos pueden residir en varios ordenadoers diferentes. Incluso en la nube pueden existir diferentes versiones en diferentes OneDrive o Google Drive, Dropbox, Microsoft Teams, Sharepoint, etc, personales. Por lo tanto, los jefes de proyecto necesitan hacer un seguimiento de las múltiples versiones de un documento para mantener el registro actual del proyecto oficial. |
|

3. ¿Mitad lleno? ¿Mitad vacío? Las métricas varían de un proyecto a otro
|
|
Hasta los equipos del mismo departamenteo a menudo no tratan las métricas esenciales de forma consistente o hacen un seguimiento de los mismos datos de la misma manera. Multipliquemos esto por los miles de proyectos en marcha en un momento determinado en una insitución, y no es difícil de ver porqué nunca se recopila un informe fiable sobre el impacto de todos estos proyectos. Incluso si los indicadores clave de rendimiento (KPI) son consistentes en toda la organización, cuando una división les hace un seguimiento sobre manzanas y el siguiente los sigue en naranjas, sus resultados no pueden ser evaluado o agregados. |

4. Los equipos tienen dificultades con los agujeros cuadrados de los sistemas de seguimiento
|
Muchas organizaciones intentan monitorizar y calcular el impacto de las iniciativas de mejora continua utilizando métodos que van desde bases de datos de proyectos domésticos hasta sistemas completos de gestión de cartera de proyectos (PPM) extremadamente caros. A veces estos trabajos - al menos durante un tiempo - pero muchas organizaciones encuentran que mantener sus sistemas domésticos se vuelve un problema grande y caro. Y, como otros han descubierto, las soluciones ya existentes, creadas para cubrir las necesidades de finanzas, tecnologías de información, servicio de clientes o otras funciones de negocio, no se ajustan o soportan de forma adecuada proyectos que estén basados en metodologías de mejora continua como Seis Sigma o Lean. ¿El resultado? Sistemas que lentamente se marchitan a medida que los recursos son dirigidos a cualquier otro sitio, mecanismos de notificación que se hacen inútiles y resúmenes que fallan al transmitir el cálculo cierto del impacto de una iniciativa incluso si son utilizadas. |
|

|
|
5. Los informes requieren demasiado tiempoSolo hay las horas que hay en el día, y los miembros y líderes del ocupado equipo necesitan priorizar. Especialmente cuando se opera en algunas de las condiciones anteriores, los líderes de equipo consideran que informar sobre proyectos es una carga que nunca llega a la cima de la lista de prioridades. Con tiempo disponible limitado, copiar y pegar información de los documentos del proyecto en un lugar y formato, después de que haya sido redondeado por varios miembros del equipo, ordenadores y servidores, no parece que sea una actividad de valor añadido. |

Y si el jefe no está pidiendo esos números (parece ser que muchos altos ejecutivos no lo hacen), la mayoría de los jefes de proyectos más bien dedicarán su tiempo límitado a otras tareas.
Las organizaciones pueden establecer estándares y asegurarse que todos los equipos de proyectos utilicen métricas consistentes. Los jefes pueden dar pasos para asegurarse que los informes de resultados lleguen a ser un paso crítico de cada proyecto individual.
Informar sobre los esfuerzos de mejora no tiene que ser tan difícil
Dada la complejidad de la tarea, y de los factores humanos y sistémicos involucrados en la mejora continua, no es difícil de ver por qué muchas organizaciones se esfuerzan en saber lo bien que funcionan sus iniciativas. El reto es asegurarse que los informes de resultados se convierten en un paso crítico en cada proyecto individual y que todos los proyectos utilizan métricas consistentes. Los equipos que puedan hacerlo encontrarán que se presta más atención a sus resultados y recibirán más crédito por cómo afectan al balance final.
Este hallazgo en el informe de ASQ subraya drásticamente los problemas en los que nos hemos centrado recientemente en Minitab; de hecho, nuestro software Companion by Minitab aborda de frente muchos de estos factores. Para los ejecutivos, gerentes y partes interesadas, Companion proporciona una visión sin precedentes ni competidores sobre el progreso, el rendimiento y el impacto final de toda iniciativa de mejora de la organización, o cualquier parte individual de ella.
Brian Mapani, director nacional de mejora continua del fabricante sudafricano de alimentos Premier FMCG, realmente atribuye a Companion el éxito de su compañía, que describe como una compañía que solo tenía una visión de mejora continua a una que ha ejecutado y entregado mucho antes su plan y estrategia para 5 años. Cuenta entre sus logros, haber ahorrado a la compañía cientos de miles de dólares al optimizar su proceso de formulación de recetas.
- Detalles
- Categoría: Comsol
- Visto: 4337

¡Resérvese las fechas!
Vea de primera mano lo que es posible con el modelado multifísico y la simulación numérica. Únase a nosotros en la Conferencia COMSOL 2020 Grenoble del 14 al 16 de octubre para:
» Sesiones de Café Técnico con debates técnicos organizados por los directores de producto e ingenieros de aplicaciones de COMSOL
» Minicursos que abarcan todo, desde la tecnología de simulación del núcleo (resolvedores, mallado, creación de geometría y más) hasta una gran variedad de áreas de física y modelado
» Presentaciones en póster y artículos de los usuarios del software COMSOL®
» Charlas magistrales y mesas redondas
- Detalles
- Categoría: Minitab
- Visto: 3860

Por Shelby Anderson.
¿Fuiste uno de los más de 300 afortunados profesionales, analistas de datos, estadísticos, consultores de mejora, directores de programa, ingenieros, directores clínicos, coordinadores y profesionales de la calidad que asistieron a la conferencia "2019 Minitab Insights Global Conference" el pasado otoño?
No te preocupes si te fue imposible asistir - con la ayuda de nuestra experta Jenn Atlas, vamos a resumir los 5 retos y aprendizajes clave que necesitas saber.
1. Los métodos de aprendizaje automático son componentes importantes del portafolio de resolvedores de problemas modernos
¿Piensas que el término aprendizaje automático se ha ido amontonando más y más últimamente? Tú No. Estás. Solo.
El aprendizaje automático, definido como los algoritmos y modelos estadísticos que los sistemas informáticos utilizan para realizar una tarea específica utilizando patrones e inferencia más que con instrucciones explícitas, existe desde hace años, pero recientemente ha ido ganando popularidad y uso debido al enorme volumen de datos que ahora están disponibles gracias a la digitalización.
Con más datos fácilmente accesibles, utilizar los métodos de resolución de problemas originales, puede ya no ser la manera más rápida o más eficiente para que los profesionales resuelvan sus problemas. Aquí es donde los métodos de aprendizaje automático son los más útiles ya que están mejor construidos para manejar grandes cantidades de datos y además en última estancia proporcionan respuestas precisas rápidamente a los problemas que tienen que resolverse.
2. Los datos pequeños todavía importan
Hemos mencionado que existen más datos que nunca antes pero eso nos lleva al siguiente punto: solo porque se puedan obtener y analizar más datos, no significa que se deba de hacer. Recuérdese que existen todavía montones de escenarios donde es mejor trabajar con cantidades pequeñas de datos de caliad y ser más reflexivo con el análisis que con el modelado y el análisis de enormes conjuntos de datos sin un propósito específico.
3. El análisis de sistemas de medida siempre es un primer paso crítico
Aunque el análisis del sistema de medida puede no parecer demasiado apasionante, muchas de las sesiones durante el 2019 Minitab Insights destacaron su importancia porque sin la adecuada verificación es difícil de probar la validez de cualquier experimento, medida o resultado.
4. La excelencia operacional en la asistencia sanitaria crece constantemente
Existe una tremenda oportunidad de mejorar la experiencia de los paciente en el secotr de los servicios de asistencia sanitaria.
La asistencia sanitaria a un alto nivel puede parecer a veces tener problemas similares a los de la fabricación, pero existen dos diferencias principales entre estas industrias:
- La asistencia sanitaria a menudo tiene que tratar más con los políticos, procesos y gente (en la forma de pacientes) así que el margen para el error es mucho más fino ya que podrían haber vidas en riesgo.
- Los profesionales sanitarios pueden tener diferentes conjuntos de capacidades y maneras de pensar que un profesional de fabricación. Estos profesionales están generalmente más orientados a procesos, tienen más habilidades con la gente y menos experiencia en análisis, por lo tanto su formación y la aplicación de métodos de mejora pueden ser únicos y diferentes a los de sus contrapartidas en fabricación.
A pesar de sus diferencias, muchas de las sesiones de 2019 Insights mostraron que estas dos industrias pueden realmente crecer y aprender una de otra.
5. La resolución de problemas estructurados nunca pasará de moda
Innumerables ponentes, incluyendo a nuestro plenario John Aarons, llamaron la atención sobre el hecho de que, de nuevo, una y otra vez, los equipos de resolución de problemas realmente se benefician de seguir una metodología estructurada como CRISP-DM, DMAIC, DMADV y SEMMA.
Estos métodos muestran el pensamiento e intención detrás de la resolución de un problema particular y, a menudo, todavía son una manera estratégica para conseguir la aceptación de los dirigentes y otros interlocutores dentro de una organización.
Profundice en estos temas y otros más, y además tenga la oportunidad de estar entre las mentes más brillantes en el mundo de la calidad, mejora y análisis de datos y comparta sus conocimientos y experiencia con otros líderes de la industria en la Conferencia "2020 Minitab Insights Global Conference". Las fechas y localización acaban de ser anunciados así que ¡le esperamos allí!