
Análisis predictivo avanzado
- Detalles
- Categoría: Minitab
- Visto: 6855
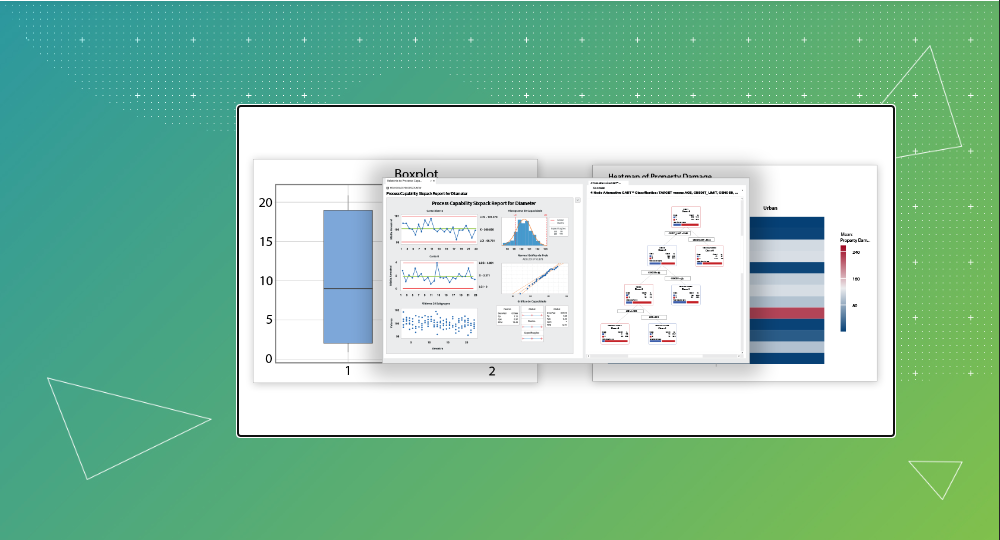
Si realmente se desea aprovechar el análisis predictivo para resolver los desafíos cotidianos, se debe de aumentar el poder analítico de los analizadores con los mejores algoritmos de aprendizaje automático más precisos de su clase. Estos proporcionan una visión más profunda de los datos. Además de proporcionar métodos estadísticos tradicionales, Minitab ha hecho que los métodos más avanzados, como los métodos basados en árboles, sean más accesibles para todos.
Lleve sus capacidades de regresión fuera de este mundo con MARS® (Splines de regresión adaptativa multivariante) o mejore sus habilidades utilizando nuestros métodos basados en árboles, como los árboles de clasificación y regresión, más conocidos como CART®, Random Forests® y gradiente potenciado, más conocido como TreeNet®. ¿No está seguro de qué método elegir? Confirme fácilmente que está utilizando el mejor modelo predictivo para responder a su pregunta con el aprendizaje automático automatizado (Auto-ML). Perfecto para aquellos que son nuevos en el análisis predictivo y necesitan recomendaciones, y expertos que buscan una segunda opinión.
CART®Árboles de clasificación y regresión |
|
Como una de las herramientas más importantes y populares en la minería de datos moderna, CART es el árbol de clasificación definitivo. CART y su motor de modelado han revolucionado el campo de la analítica avanzada e inaugurado la era actual de la ciencia de datos.
Para aquellos que son nuevos en CART, se trata de un algoritmo basado en árboles que funciona buscando muchas formas de particionar o dividir datos localmente en segmentos más pequeños en función de diferentes valores y combinaciones de predictores. CART selecciona las divisiones de mejor rendimiento, luego repite este proceso recursivamente hasta que se encuentra la colección óptima. El resultado es un árbol de decisión representado por una serie de divisiones binarias que conducen a nodos terminales que pueden describirse mediante un conjunto de reglas específicas. El árbol y su diseño son visualmente estimulantes e intuitivos de interpretar, por lo que no es necesario ser un científico de datos para comprenderlo y obtener información útil.
Diseñado para usuarios de todos los niveles, el modelo de CART puede revelar rápidamente relaciones importantes que podrían permanecer ocultas al usar otras herramientas analíticas. CART se destaca en el campo del análisis predictivo gracias a su metodología original y altamente deseable que incluye automatización integrada, facilidad de uso, rendimiento y precisión.
Propietario
La metodología de CART se basa en una teoría matemática histórica introducida en 1984 por cuatro estadísticos de renombre mundial en la Universidad de Stanford y la Universidad de California en Berkeley. El motor de modelado CART, la implementación de árboles de clasificación y regresión de Minitab, es el único software de árboles de decisión que incorpora el código patentado original.
Rápido y Versátil
Las extensiones patentadas del motor de modelado CART se diseñaron específicamente para mejorar los resultados de la investigación y el análisis de mercado, respaldar la implementación de alta velocidad y predecir y puntuar en tiempo real. A lo largo de los años, nuestro motor se ha convertido en uno de los algoritmos de modelado predictivo disponibles más populares y fáciles de usar, y es fundamental para muchos enfoques modernos de minería de datos basados en bagging y boosting.
Random Forests®Los bosques aleatorios de Breiman y Cutler |
|

Basado en una colección de árboles de clasificación y regresión (CART®), el motor de modelado Random Forests® suma las predicciones hechas de cada árbol CART para determinar la predicción general del bosque, al tiempo que garantiza que los árboles de decisión no se vean influenciados entre sí.
Para aquellos nuevos en Random Forests, es una potente técnica de conjunto desarrollada por Leo Breiman y Adele Cutler en la Universidad de California, Berkeley, y es favorecida por muchos practicantes de modelos predictivos. La simplicidad engañosa del algoritmo construye cientos de árboles independientes y emplea mucho muestreo de observaciones y variables.
La capacidad única de Random Forests para evaluar el rendimiento imparcial del modelo en función de los datos listos para usar elimina la necesidad de tener una muestra de prueba/validación separada. Esto posiciona inmediatamente a Random Forests como la mejor herramienta de modelado predictivo en las amplias aplicaciones de datos donde la cantidad de variables excede, a menudo muchas veces, la cantidad de observaciones disponibles.
Responsabilidad
Random Forests tiene una capacidad única para aprovechar cada registro en su conjunto de datos sin los peligros del sobreajuste. Esto es especialmente importante para conjuntos de datos pequeños (en términos de observaciones), donde cada registro puede aportar algo valioso. Random Forests se asegurará de que todos los registros se hayan tenido en cuenta en sus modelos y que no se haya perdido ninguna información.
Importancia variable robusta
Random Forests utiliza técnicas novedosas para clasificar los predictores según su importancia. Esto es conveniente cuando los datos incluyen miles, decenas o incluso cientos de miles de variables o predictores, lo que está más allá del alcance de las herramientas de regresión y clasificación convencionales. Random Forest puede manejar situaciones tan extremas e informar qué variables usar en la investigación de seguimiento. Múltiples rondas de muestreo agregarán solidez y calidad a estos conocimientos.
TreeNet®Aumento de gradiente |
|
La herramienta de aprendizaje automático más flexible, galardonada y potente de Minitab, TreeNet® Gradient Boosting, es capaz de generar modelos extremadamente precisos de manera consistente.
Para aquellos que son nuevos en TreeNet, es una potente implementación de la moderna clase de algoritmos de aprendizaje automático generalmente conocida como Stochastic Gradient Boosting. Desarrollada por Jerome Friedman en la Universidad de Stanford, la técnica es conocida por su excelente precisión predictiva. El secreto está en la forma en que se construye un modelo: en cada iteración se agrega un pequeño árbol al conjunto actual de árboles para corregir los errores combinados del conjunto.
Utilizando la variedad de funciones de pérdida suministradas, el proceso puede ajustarse para la tarea específica de modelado predictivo, como regresión de mínimos cuadrados, regresión robusta, clasificación, etc. Para ayudar con la interpretación del modelo, TreeNet va un paso más allá y genera automáticamente varios 2D y gráficos 3D para explicar la naturaleza de la dependencia de la variable de respuesta en las entradas del modelo. El modelo es lo suficientemente flexible para descubrir e incorporar automáticamente varias no linealidades e interacciones multidireccionales. Un conjunto adicional de controles permite al usuario ajustar las interacciones del modelo para cumplir con los objetivos de diseño específicos.
Precisión incomparable
Nuestro motor de modelado TreeNet tiene un grado de precisión generalmente inalcanzable por un solo modelo o conjuntos, como embolsado o refuerzo convencional. Nuestra metodología no es sensible a los errores de datos y no requiere preparación de datos, preprocesamiento o imputación de valores faltantes que consumen mucho tiempo. Con otros métodos, los errores de datos pueden ser un desafío para la minería de datos convencional y catastróficos para el impulso convencional. Por el contrario, el modelo TreeNet es inmune a tales errores, ya que rechaza dinámicamente los datos que difieren demasiado del modelo existente o que están contaminados con etiquetas objetivo erróneas.
Perspectivas ilustradas
Evite las técnicas convencionales de prueba y error o caminar en la oscuridad en el futuro. Nuestro motor de modelado TreeNet ofrece un conjunto único de información sobre el funcionamiento interno de sus modelos con gráficos de dependencia. Nuestras gráficas de dependencia parcial en 2D muestran la naturaleza de los efectos principales, mientras que nuestras gráficas de dependencia parcial en 3D también incluyen interacciones bidireccionales. Armado con los nuevos conocimientos descubiertos automáticamente por TreeNet, podrá crear modelos de regresión y clasificación de alta precisión si es necesario.
Detección de interacción
La detección de interacciones dentro de nuestro motor de modelado TreeNet establece si se necesitan interacciones de algún tipo en un modelo predictivo. Este sistema no solo ayuda a mejorar el rendimiento del modelo, a menudo de forma espectacular, sino que también ayuda a descubrir y utilizar nuevos conocimientos valiosos.
MARS®Splines de regresión adaptativa multivariable |
|
El motor de modelado MARS® es ideal para los usuarios que prefieren los resultados en una forma similar a la regresión tradicional, pero sin dejar de detectar las no linealidades y las interacciones esenciales.
El enfoque de modelado de regresión de la metodología MARS revela de manera efectiva patrones y relaciones importantes en los datos que son difíciles, si no imposible, de revelar para otros métodos de regresión. El motor de modelado MARS construye su modelo juntando una serie de líneas rectas, donde cada una puede tener su propia pendiente. Esto permite que el motor de modelado MARS trace cualquier patrón detectado en los datos.
Regresión y clasificación de alta calidad
El modelo MARS está diseñado para predecir resultados numéricos, como la factura mensual promedio de un cliente de telefonía móvil o la cantidad que se espera que un comprador gaste en una visita a un sitio web. El motor MARS también es capaz de producir modelos de clasificación de alta calidad para un resultado sí/no. El motor MARS realiza selección de variables, transformación de variables, detección de interacciones y autoevaluaciones, todo de manera automática y a gran velocidad.
Resultados de alto rendimiento
Las áreas en las que el motor MARS ha exhibido resultados de muy alto rendimiento incluyen la predicción de la demanda de electricidad para empresas generadoras de energía, la asociación de las puntuaciones de satisfacción de los clientes con las especificaciones técnicas de los productos y el modelado de presencia/ausencia en los sistemas de información geográfica (SIG).