- Detalles
- Categoría: Comsol
- Visto: 3022

El límite final de presentación de resúmenes para la conferencia en línea COMSOL Conference 2020 Europe se ha ampliado haste el próximo viernes 7 de agosto.
Presentar en la Conferencia es una gran oportunidad para que tus logros de modelado y simulación obtengan reconocimiento dentro de la comunidad de COMSOL.
Presenta un resumen ahora para un póster y/o una presentación oral como escaparate de tu uso del software COMSOL Multiphysics®. Tanto los presentadores como los coautores podrán obtener un precio de registro reducido por sus contribuciones.
Para presentar el resumen, utilice el enlace inferior.
- Detalles
- Categoría: Comsol
- Visto: 6451

En esta entrada del blog de COMSOL, su autor, Walter Frei, nos presenta un útil índice a toda una serie de lecciones en vídeo sobre el modelado de bobinas electromagnéticas con COMSOL®.
El índice está dividido en cuatro partes, cada una de ellas formada por cinco videos. Por tanto un total de vídeos sobre modelado de bobinas.
Estos son los cuatro apartados en que se han dividido las lecciones:
1. Arranque con el modelado de bobinas electromagnéticas
2. Calentamiento electromagnético en bobinas
3. Modelado, de fuerzas, movimiento, no linealidaes, y más...
4. Modelado de bobinas 3D
Por tanto, todo aquel que busque una introducción guíada al modelado de bobinas con COMSOL Multiphysics® y el módulo AC/DC, en esta entrada del blog de COMSOL encontrará una serie de lecciones en vídeo para recorrer numerosos aspectos del modelado de bobinas electromagnéticas, diseñados para mostrar las claves para la construcción de estos modelos.
- Detalles
- Categoría: Minitab
- Visto: 6763

Por Shelby Anderson.
La industria sanitaria ha encarado retos enormes en 2020, principalmente luchar contra el nuevo coronavirus COVID-19. Esta industria está formada por profesionales conocidos por su resistencia, empatía, largas horas de duro trabajo y optimismo. Dado todo lo que hace para ayudar a los demás, los trabajadores de la salud merecen especialmente ayuda para facilitar sus trabajos y salvar vidas. Una pequeña manera en la que Minitab puede ayudarles específicamente es con los mapas de flujo de valor.
¿Qué es un mapa de flujo de valor?
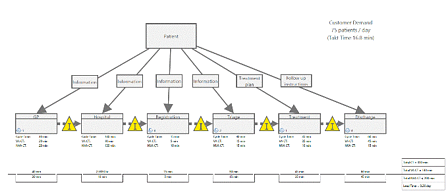
Un mapa de flujo de valor (VSM) es una herramienta que ayuda a visualizar cada paso o acción requerida para completar un proceso desde el principio al final.
Originalmente se creó como una técnica de producción ajustada (Lean), pero el objetivo de un VSM es ayudar al usuario no solo a visualizar, sino a mapear y comprender el flujo de los materiales e información. Esta información entonces puede ser utilizada para identificar mejoras para optimizar el proceso, como reducir los desperdicios o incrementar la velocidad.
Cuando miramos específicamente a la industria sanitaria, existen muchas oportunidades ricas en datos que podrían utilizar la ayuda de los mapas de flujo de valor. Algunos ejemplos incluyen la mejora de las puntuaciones de HCAHPS (Evaluación del consumidor del hospital de proveedores y sistemas de atención médica), decrementando los tiempos de espera de los pacientes, incrementando la capacidad/rendimiento y optimización del inventario global para artículos como máscaras N95, desinfectantes de manos o bolsas de suero.
¿Pueden los mapas de flujo de valor (VSM) realmente ayudar en sanidad?
¡Absolutamente sí! Una aplicación para VSM en salud es mapear la ruta de un paciente durante su tratamiento, y entonces utilizarla para mejorar el servicio y minimizar retardos.
Hay que tener en cuenta que cuando se intenta mapear con precisión un proceso o sistema, la obtención de datos fiables, de alta calidad, sobre el flujo de información y el tiempo que un paciente tarda en uno o entre pasos, es clave. Es esencial cronometrar con precisión los pasos del proceso y aprovechar la comunicación entre equipos interfuncionales para obtener una imagen real de lo que está sucediendo.
Para empezar a mapear la ruta de un paciente en el tratamiento, sería necesario crear un mapa del estado actual para que actúe como línea de base para identificar áreas de mejora. Una de las maneras más fáciles de crear un mapa de flujo de valor es utilizar Minitab Workspace o Companion by Minitab.
En este ejemplo, el primer paso que un paciente realiza es visitar su médico general (general physician o, abreviado "GP"). Este paso se representa con una forma de proceso rectanguar el el mapa de flujo de valor. El tiempo total que el paciente emplea en este paso recibe el nómbre de tiempo de ciclo y se desglosa debajo del rectángulo en valor añadido ("VA") y no valor añadido ("NVA"). VA es el tiempo que el cliente está dispuesto a pagar, p. ej., los 20 minutos utilizados con el GP, mientras que NVA es el tiempo que el cliente no está dispuesto a pagar, p. ej., el tiempo utilizado en la sala de espera antes de la cita.

Después de calcular el tiempo de ciclo, se verá una flecha de linea punteada entre los pasos del proceso llamada flecha de empuje. Ésta muestra que una vez que un paciente completa un paso, es "empujado" o avanzado al siguiente paso. Los expertos en Lean generalmente sugieren que se podría diseñar un proceso más eficiente cambiando estos pasos de empuje a flujos continuos o pasos estirar ("pull"). Los triángulos amarillos encima de las flechas de puntos indican el tiempo que un paciente emplea esperando al siguiente proceso. Esos pasos son acciones sin valor añadido para el paciente.
Al identificar todos los pasos se puede empezar a mapear el proceso completo, moviéndose desde la izquierda a la derecha. Aunque VSM puede realmente hacerse con papel y lápiz, el uso de potentes herramientas visuales de negocio como las de Minitab Workspace o Companion by Minitab pueden hacer el proceso mucho más fácil. Por ejemplo, tanto Minitab Workspace como Companion by Minitab calculan automáticamente y visualizan una línea de tiempos en la parte inferior del VSM, que añade el tiempo total para realizar el sistema completo (conocido como "lead time"), incluyendo información de resumen global.
Una vez que todo el sistema ha sido mapeado, se puede crear un mapa de estado futuro ideal, y posiblemente una serie de pasos futuros intermedios. Estos pueden identificar áreas de mejora, y una vez implementados, pueden convertirse en el "nuevo" mapa de estado actual como parte de un proceso de mejora de calidad iterativo.
¿Cómo se mejora el mapa o el proceso del estado actual?
Cuando se buscan áreas de mejora, hay que intentar poner el foco en cambios para mejorar el flujo de pacientes a lo largo del proceso. Un flujo continuo es lo ideal y mueve pacientes a través del sistema sin que tengan que esperar. Sin embargo, el flujo continuo no siempre es posible, así que en su lugar se deben de introducir otros cambios- como FIFO (primero en entrar, primero en salir).
Otra idea sería echar un vistazo al tiempo "Takt time", que puede ayudar a descifrar el ritmo de demanda. En este caso, Takt Time puede interpretarse como el número de pacientes que pueden tratarse por unidad de tiempo. Tanto Minitab Workspace como Companion by Minitab calculan el Takt Time automáticamente.
Una vez que se han completado los mapas de estado actual y futuro, pueden compararse ambos, cuantificar las oportunidades de mejora y mirar cómo implementar los cambios. En este ejemplo, los pasos de triaje y clasificación/designación podrían combinarse para que los pacientes requieran menos visitas al hospital y para que reciban un tratamiento más rápido.
- Detalles
- Categoría: BIOVIA
- Visto: 6117

El grupo Biophym del Instituto de Estructura de la Materia (IEM) del CSIC, liderado por el Dr. Javier Martínez Salazar, lanzó a finales de abril un proyecto científico denominado COVID-PHYM para el estudio de fármacos contra el COVID-19. El proyecto se lleva a cabo con la colaboración de la Vicepresidencia de Cultura Científica del CSIC y de la Fundación Ibercivis a través de la plataforma Boinc de colaboración ciudadana.
El proyecto COVID-PHYM quiere evaluar la capacidad de varios fármacos, utilizados en el tratamiento de otras enfermedades virales y que han demostrado ser suficientemente seguros para la salud humana, para inhibir la multiplicación del virus SARS-Cov-2, causante de la enfermedad COVID-19. De este modo se podría tratar a pacientes con COVID-19 mucho antes que con un compuesto de nueva creación y esto permitiría acelerar el control de la pandemia.
Para llevar a cabo este estudio el grupo Biophym ha propuesto realizar simulaciones de la interacción de fármacos empleados contra el ébola, la infección por VIH, la gripe o la hepatitis B con la maquinaria de replicación del genoma del virus SARS-Co-V, y se recurre a técnicas informáticas y a la ayuda de los ordenadores de miles de personas voluntarias conectadas a través de la plataforma de computación distribuida de Ibercivis. El proyecto COVID-PHYM utiliza de forma puntual algunas herramientas de BIOVIA Discovery Studio para diversas acciones de preparación y test de viabilidad de receptores y ligandos relacionadas con los objetivos del proyecto.
- Detalles
- Categoría: Comsol
- Visto: 6597
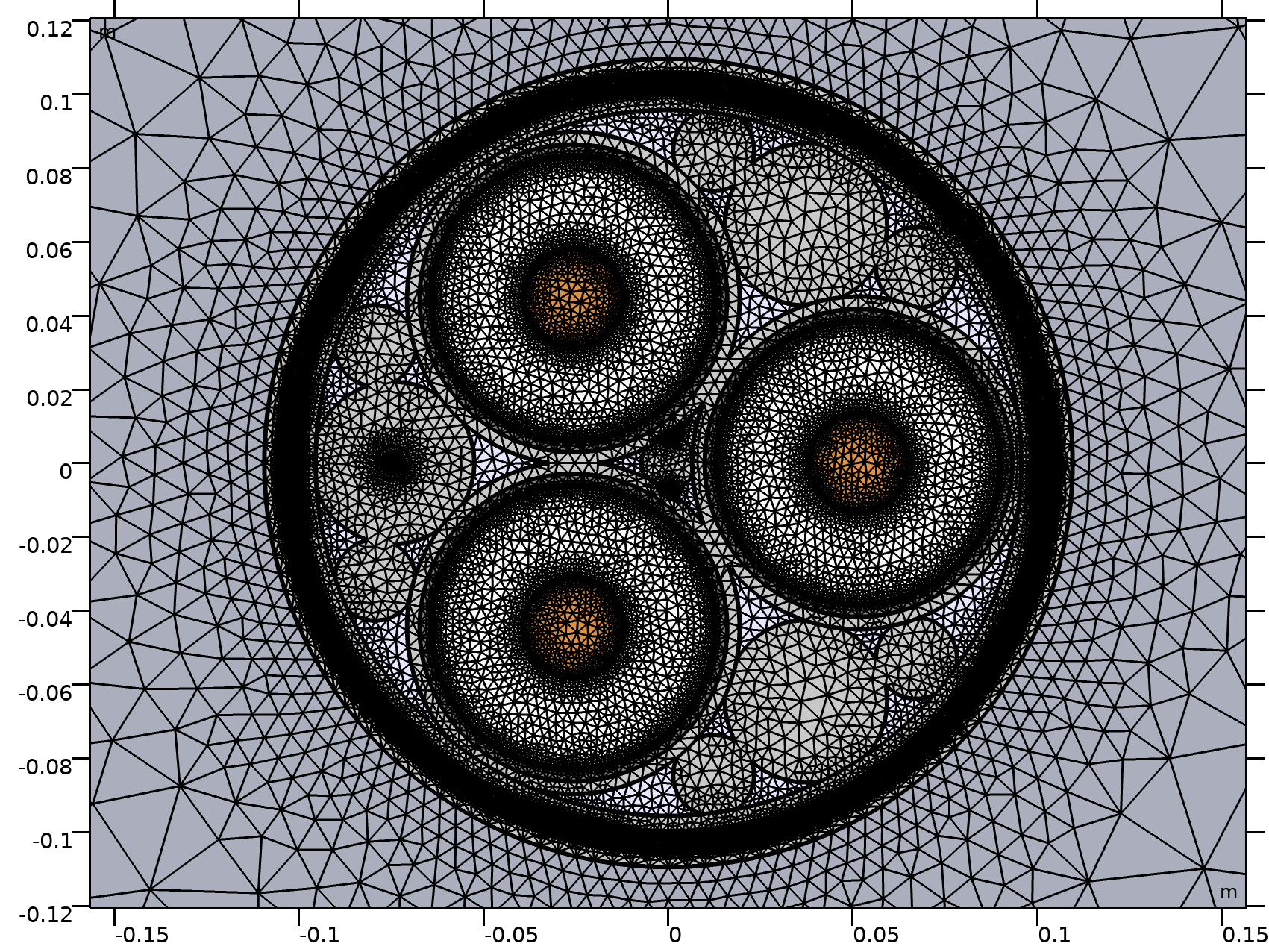
Presentamos un par de artículos del blog de COMSOL, actualizados de una publicación original de diciembre de 2017, en la que Durk de Vries nos ofrece una hoja de ruta para modelar cables con COMSOL.
Se trata de una serie de tutoriales en ocho partes, que muestra cómo modelar un cable a escala industrial utilizando COMSOL Multiphysics y su módulo AC/DC.
La serie completa se presenta en dos publicaciones del blog. En la primera publicación "Modelado de cables en COMSOL Multiphysics®: Serie de tutoriales de 8 partes" solo se presentan modelos en 2D (Partes 1 a 6 de la serie). Los modelos de torsión 3D (Parte 7 y 8) se analizan en otra publicación de blog: "Uso de modelos 3D para investigar efectos inductivos en un cable submarino."
Los artículos también pueden servir como una buena introducción al modelado de fenómenos electromagnéticos en general. El modelo numérico se basa en diseños de cable estándar y está validado por las cifras reportadas.
- Detalles
- Categoría: Minitab
- Visto: 13062

Por José Padilla.
Los gráficos de control son gráficos de series temporales especializados que ayudan a determinar si un proceso está bajo control estadístico. Aunque algunos de los más utilizados como pueden ser Xbar-R y los cuadros Individuales son excelentes para detectar cambios relativamente grandes en el proceso (cambios de más de 1.5 sigma), se necesitará algo diferente para los cambios más pequeños. Nos referimos al gráfico de media móvil ponderada exponencialmente (EWMA).
Algunas de las propiedades importantes de los gráficos EWMA son:
- Incorporan datos de todos los puntos anteriores en cada punto trazado posteriormente. Por tantp, todos los datos se usan para calcular los puntos trazados en el gráfico.
- Los datos se pueden recopilar individualmente o en subgrupos.
- No son sensibles a la suposición de normalidad.
Pero la mayor ventaja del gráfico EWMA es que puede usarse para detectar pequeños cambios en la media del proceso. Esto es importante porque la detección temprana ayuda a reaccionar más rápidamente y corregir el proceso.
EWMA vs. Gráfico de datos individuales para detectar pequeños cambios en el proceso
Digamos que un fabricante de pequeñas válvulas de polipropileno quiere usar gráficos de control de proceso para monitorizar la resistencia a la tracción. Al fabricante le preocupa la posibilidad de pequeños cambios en la media.
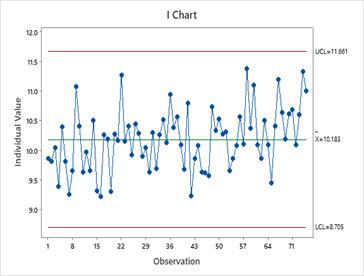
Un gráfico de control de Individuos para los datos muestra el proceso en control. Sin embargo, parece haber un pequeño cambio en el proceso en torno a la observación 66.
Para los mismos datos de proceso, el gráfico de control de EWMA marca el último punto de datos como fuera de control.
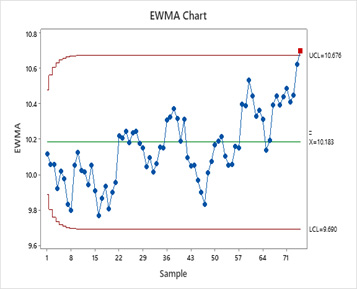
Los ingenieros pueden investigar el proceso en busca de posibles causas especiales que estén afectando el proceso y eliminarlas.
¿Dónde podría usar la tabla de control de EWMA?
El mismo concepto podría aplicarse a numerosas métricas que se investigan en la organización. Aunque una señal en un I-Chart puede informar sobre un cambio o evento repentino y extremo, la EWMA probablemente revelará si el proceso se ha desviado ligeramente de estar centrado (suponiendo que estaba centrado para empezar) y la calidad del producto se ha deteriorado. ¡Piense dónde podría aplicar esta herramienta en un cuadro que ya esté utilizando, para obtener más información de su proceso!
Es importante utilizar gráficos de control para monitorizar las características del proceso. Elegir el gráfico de control correcto ayudará mejor a las empresas a detectar cambios en los procesos cuando estén presentes. Los cuadros de control tradicionales son efectivos para grandes cambios en el proceso. La detección rápida de pequeños cambios en procesos maduros o altamente sensibles es donde realmente brilla el cuadro de control de EWMA.
- Detalles
- Categoría: Maple
- Visto: 3923

La fecha límite para la presentación de propuestas (una página) para participar en el Congreso Virtual de Maple 2020 (denominado formalmente Maple Conference 2020) ha sido ampliada hasta el 16 de agosto de 2020. ¡No pierda esta oportunidad!
La edición de este año tendrá lugar en forma virtual del 2 al 6 de noviembre de 2020, como medida preventiva frente a la pandemia del COVID-19. El cambio de formato permitirá que profesionales, investigadores, profesores y estudiantes que habían descartado asistir en ediciones anteriores por el desplazamiento que suponía, puedan presentar sus trabajos en esta edición y/o participar en las diferentes sesiones.
Este congreso está dedicado a explorar diferentes aspectos del software matemático Maple, incluyendo su impacto en la educación matemática, en los nuevos algoritmos y técnicas de cálculo simbólico y en sus aplicaciones. Los asistentes tendrán la oportunidad de conocer las últimas funcionalidades de Maple y de compartir experiencias, e interactuar, con sus desarrolladores. Este congreso incluirá presentaciones y debates en vivo, así como grabaciones y salas de chat con el fin de ajustarse a las diferentes zonas horarias de los participantes.
INTRODUCTION
The Maple Conference 2020 is happening online November 2-6, 2020. This conference is dedicated to exploring different aspects of the math software Maple, including Maple's impact on education, new symbolic computation algorithms and techniques, and the wide range of Maple applications. Attendees will have the opportunity to learn about the latest research, share experiences, and interact with Maple developers. The conference will take place online, and will include live presentations and discussions as well as recordings and chatrooms, in order to accommodate time zones. Maplesoft staff will also offer Maple training sessions on a variety of topics during the conference.
CALL FOR PRESENTATIONS
Maple Conference 2020 invites submissions of proposals for presentations on a range of topics related to Maple, falling into three broad categories:
Maple in Education
Topics could include, but are not limited to:
- Effective ways to use Maple as a tool to support remote learning or hybrid courses
- Innovative uses of Maple in the classroom (new ways to approach old problems, methods for using Maple to teach courses outside of traditional core math, impact on the curriculum, etc.)
- Measurable improvements in student performance after integrating Maple into a course
- Classroom tips and techniques/best practices drawn from experience
Algorithms and Software
Topics could include, but are not limited to:
- Symbolic and symbolic-numeric methods for solving mathematical problems, from any field
- Algorithm optimization and performance tuning techniques
- Effective use of types and data representations for particular problems or domains
- User interfaces for mathematical problem solving
Applications of Maple
Topics could include, but are not limited to:
- Applications that use Maple in unusual settings or in unusual ways
- Applications that push or extend the limit of what Maple can do
- Applications that explore critical world problems
- Applications that combine Maple with other technology
All presentation proposals will be reviewed by the conference organizing committee. If the proposal is accepted, the submitter will be invited to present their work at the conference.
After the conference, all presenters and invited speakers will be invited to submit a full paper for inclusion in the conference proceedings. These submissions will undergo peer-review, and the decision about acceptance or rejection lies with the Maple Conference 2020 Program Committee.
PRESENTATION PROPOSALS
Your presentation proposal should be in the form of a title and abstract for your proposed talk. Abstracts should be under one page/400 words in length, and must be in English. If your presentation proposal is accepted, at least one author is expected to attend the conference to present the paper.
All presentations are to be given in English.
PAPERS (OPTIONAL)
After the conference, all presenters and invited speakers will be invited to submit a full paper on the work they presented. These papers will undergo peer-review, and if accepted, will appear in the conference proceedings. Papers should not duplicate work published or submitted for consideration elsewhere.
Papers must be in English and should be 6-15 pages in length. Please follow the Springer LNCS conference proceedings author instructions. Authors should download the .zip file: "LaTeX2e Proceedings Templates."
SUBMISSION INSTRUCTIONS AND DEADLINES
Proposals should be in the form of a Word doc or a PDF. Submission is via EasyChair:
- Abstract submission:
July 15, 2020Extended until Aug. 16, 2020 - Notification of acceptance/rejection of presentation proposal: August 31, 2020
- Paper submission: December 31, 2020
- Notification of paper acceptance/rejection: February 28, 2021
- Camera-ready copy due: March 31, 2021
CONFERENCE DETAILS
- Conference Date: November 2-6, 2020
- Location: The conference will be held online
- Program Chairs: Robert M. Corless, Western University, and Jürgen Gerhard, Maplesoft