- Detalles
- Categoría: MapleSim
- Visto: 8367
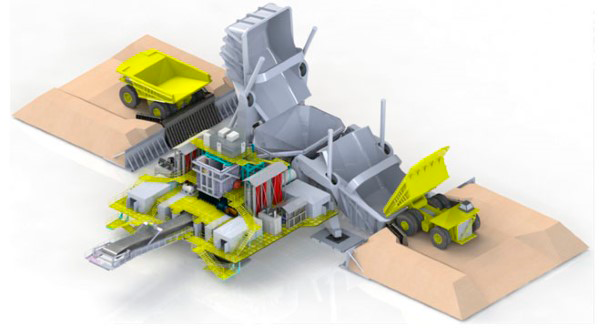
RETO FLSmidth quería desarrollar una maquina muy compleja que revolucionase la industria minera al reducir el coste asociado con combustible, el mantenimiento del vehículo y la infraestructura. SOLUCIÓN FLSmidth trabajó con el equipo de Soluciones de Ingeniería de Maplesoft para crear un modelo multidominio de alta fidelidad de la máquina, para identificar cualquier problema potencial con el diseño del sistema antes de la producción. RESULTADO Trabajando con Maplesoft, FLSmidth diseñó un modelo completamente funcional del Dual Truck Mobile Sizer (DTMS). El aprendizaje de los posibles problemas en la fase de diseño permitió al proyecto no salirse del camino. Saber que el DTMS funcionará correctamente la primera vez que se pruebe permitirá ahorrar millones de dólares en producción y costes de rediseño. |
En la industria minera, las plantas de procesado se construyen generalmente en la zona de extracción. El mineral extraído es transportado por por camiones súper-pesados a la planta, donde es triturado en tamaños menores antes de apilarlos, o transportarlos a otro lugar para seguir con su procesado. Además del mineral, la mina normalmente tiene que mover cuatro veces más carga que la del propio mineral. Las grandes minas generalmente mueven 700.000 toneladas de material al día. A medida que crece la mina, los camiones tienen que recorrer distancias más largas para depositar su carga, lo que se traduce en un incremento de costes de combustible y mantenimiento del vehículo.
Para abordar este problema, FLSmidth pidió a los servicios del equipo de Soluciones de Ingeniería de Maplesoft que desarrollasen herramientas de diseño y análisis que les ayudara a diseñar el Dual Truck Mobile Sizer (DTMS) – una máquina innovadora que puede ser reposicionada durante el proyecto, a medida que incrementan las distancias del transporte.
El DTMS aumenta la eficiencia de rotura del material en el depósito gracias a su configuración de doble salto. Un camión retrocede hacia un depósito hasta alcanzar el bordillo de restricción en el suelo. Después de depositar su carga, lentamente se mueve, baja el contenedor y se aleja. Una vez el camión se separa del depósito, este puede ser levantado. Mientras se levanta, va depositando los materiales en la tolva del alimentador de la plataforma. A medida que el material se introduce se transporta ese material hasta la trituradora hasta que queda reducido a un tamaño adecuado. Después de ser triturado, el material se deposita en la cinta de descarga donde es llevado a la cinta de banco. Este proceso se realiza mientras otro camión deposita material en el otro contenedor, lo que aumenta el numero de ciclos de descarga de camión.
- Proyectos complejos involucran múltiples grupos de diseño trabajando en diferentes subsistemas que luego han de ser integrados.
- El modelado a nivel de sistema provee identificación temprana y corrección de problemas de integración antes de que se conviertan en problemas costosos.
- MapleSim esta fuertemente integrado mediante comandos API con Maple, permitiendo el análisis y optimización de modelos multidominio complejos.
- Los estudios multidominio a nivel de sistema del DTMS proveyeron una visión temprana de todo el comportamiento dinámico, llevando a la implementación de mejoras significativas en su estructura y respuesta dinámica.
- MapleSim y Maple fueron herramientas indispensables para el temprano diseño y análisis del sistema.
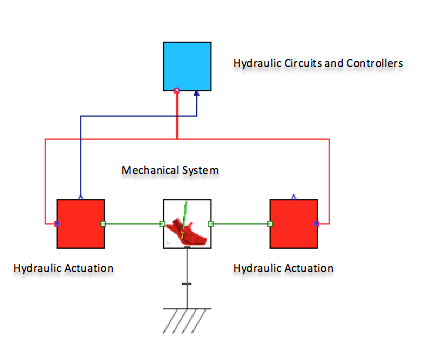
Para crear herramientas que ayudasen a FLSmidth a diseñar esta innovadora pieza de su equipamiento, el equipo de Maplesoft tuvo que comprender en profundidad las dinámicas del sistema de salto. Empezaron usando MapleSim, la plataforma de modelado y simulación avanzada, para desarrollar un modelo completamente parametrizado del salto. Aprovechándose de las capacidades de modelado multidominio de MapleSim, fueron capaces de crear un modelo de alta fidelidad que incorporaba todos los componentes clave del salto – desde su estructura geométrica y funcionamiento mecánico, hasta los circuitos hidráulicos y controladores. "El DTMS es una maquina muy grande y compleja," dice Willem Fourie, Global Product Line Manager – Mobile Sizer Stations, FLSmidth. "La habilidad para modelar todos los aspectos de sus operaciones durante la fase de diseño usando MapleSim nos dio la confianza de que el producto que definitivamente construyésemos funcionaria correctamente desde el inicio. No podemos ni empezar a poner un valor a lo que significa esto para nosotros."
 |
 |
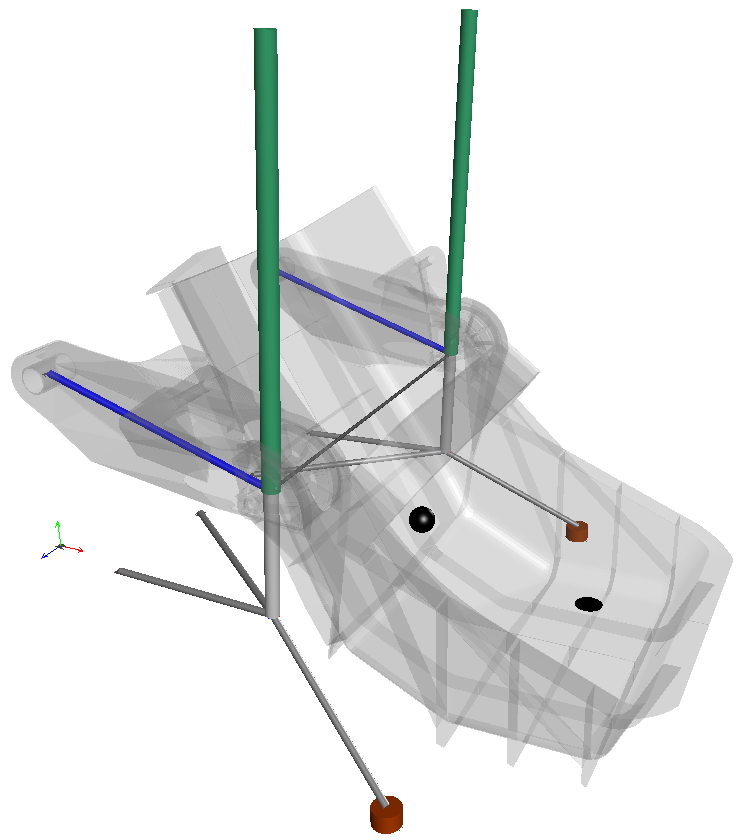
| Modelo en 3D del depóstito, y su correspondiente modelo con hidráulica en 2D | |
El enfoque del modelado con MapleSim no solo ofrece los requerimientos básicos de la simulación dinámica multidominio, sino que también da acceso a las ecuaciones simbólicas que hay debajo, permitiendo al usuario crear rápidamente herramientas de diseño específico usando el motor computacional simbólico de alto rendimiento de Maple.
La creación del modelo del contenedor se complementó con el desarrollo de múltiples herramientas de diseño para ayudar a ajustar el modelo para conseguir el comportamiento deseado. Una de esas herramientas es la Geometric Design Evaluation, que proporciona la habilidad de evaluar cambios en las dimensiones del diseño del contenedor y su efecto en las dinámicas del sistema. La herramienta utiliza Maple, la herramienta de computación simbólica de Maplesoft, para realizar un barrido paramétrico, mientras simultáneamente ejecuta simulaciones usando los diferentes valores de los parámetros provistos. Maple luego presenta los resultados dentro de una única gráfica para una fácil comparación y evaluación. Otras herramientas desarrolladas incluyen herramientas para modelar la hidráulica y los componentes, diseñar el perfil de movimiento, investigar la carga dinámica en los cojinetes, y estimar la carga de flujo de material.
Como parte de desarrollo y verificación del modelo del contenedor, el equipo técnico de Maplesoft también evaluó el diseño, para identificar las fuentes de vibraciones y sus efectos. Desarrollaron un método para realizar un análisis de estabilidad, que fue posible gracias al hecho de que el modelo del contenedor proporcionaba un fácil acceso a características geométricas clave y propiedades dinámicas del diseño. El método de análisis de estabilidad se mostró usando un caso de estudio donde se variaba la localización del sensor de retroalimentación. El análisis identificó un problema potencial muy temprano en la fase de diseño, permitiendo a los ingenieros de FLSmidth desarrollar un diseño más robusto.
"El análisis de estabilidad realizado por el equipo de Maplesoft fue muy esclarecedor," dijo Fourie. “El conocimiento temprano de un problema potencial nos permitió realizar el diseño teniéndolo en mente, en lugar de tenerque volver atrás y tener que volver a trabajar el diseño en una etapa posterior. Esto contribuyó a mantener nuestro proyecto según lo planeado, y ahorrarnos millones de dólares." El método de diseño del análisis de estabilidad y todoas las otras herramientas de análisis desarrolladas por Maplesoft se proporcionaron a FLSmidth, capacitándolos para aplicarlas en futuros proyectos.
Una vez que se completo el modelo y su verficiación, durante las siguientes fases del proyecto, el personal de Maplesoft siguió con el desarrollo del modelo del chasis, y finalmente el DTMS completo. Se crearon muchas más herramientas de diseño, proporcionando la posibilidad de evaluar la flexibilidad de las articulaciones, variaciones de los centros de masas cuando el depósito se elevaba y bajaba, e incluso el modelado del terreno para investigar los desplazamientos verticales del sistema en diferentes tipos de suelo.
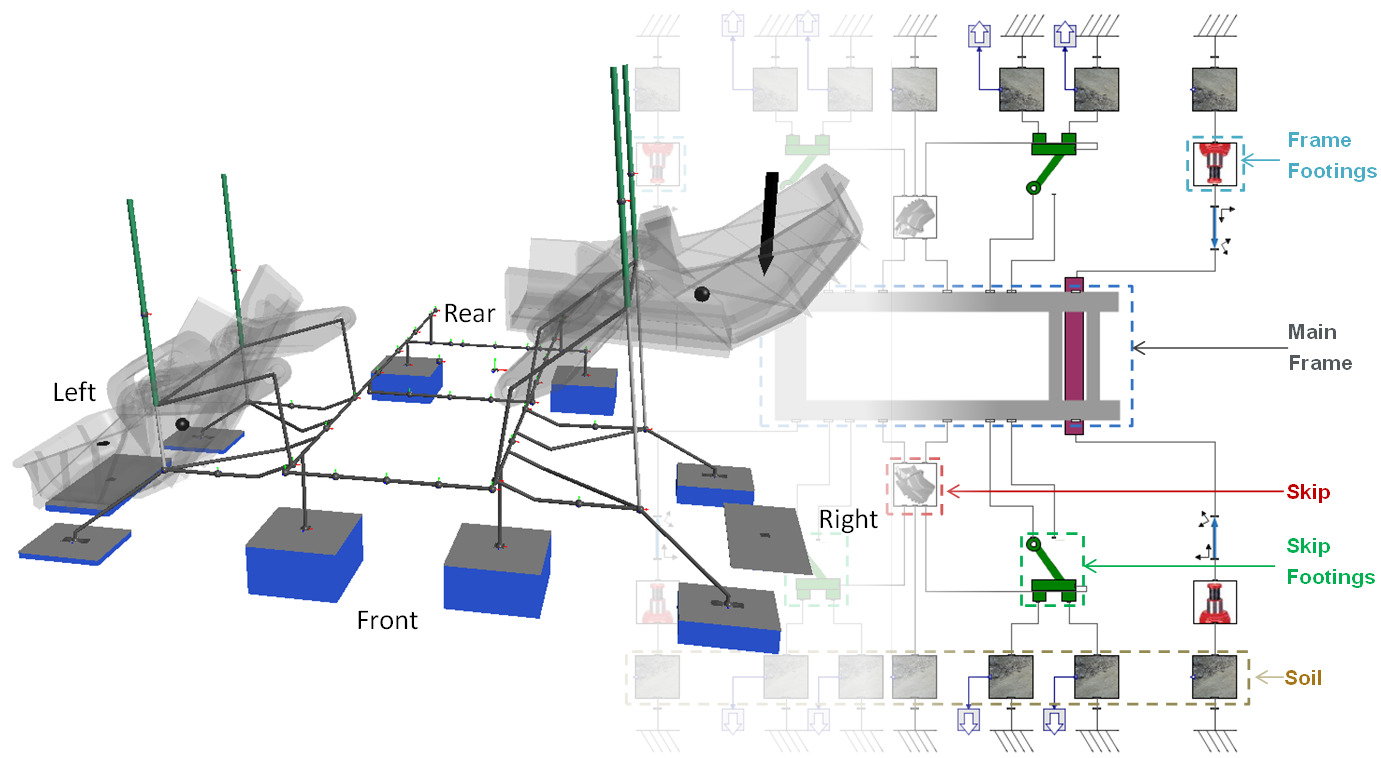
Modelo de DTMS completo, incluyendo interacciones de la cimentación y el suelo
- Detalles
- Categoría: Otras
- Visto: 11732
Después de invertir billones de dólares anuales en investigación y desarrollo de nuevos fármacos, la producción de nuevas medicinas está muy por debajo de los valores obtenidos en las últimas décadas. Esto no es tan ilógico como de primeras pueda parecer. En la industria uno puede esperar obtener resultados tan positivos como sea la inversión que se realiza para conseguir dichos resultados, pero en cambio, esto no siempre es así.
No todo el dinero fue gastado en vano. Haber podido completar el Genoma Humano, el esclarecimiento de nuevos mecanismos de acción de enfermedades, la habilidad para analizar millones de muestras por día y las nuevas sofisticadas plataformas de detección, son aspectos fundamentales para los procesos de descubrimiento y desarrollo de fármacos hoy y, por supuesto, indispensables para continuar con estos procesos en el futuro.
Diluvio de datos
En los últimos 10 años, los nuevos métodos de comunicación y almacenamiento de información han permito la generación y el almacenamiento de cantidades crecientes de datos electrónicos de forma diaria. El gigante farmacéutico, Roche, informó en 2010 que su compañía estaba produciendo tantos datos que se llegaban a duplicar cada 15 meses. Estos datos no solo se incrementan por investigación y desarrollo interno, sino también a partir de una red de datos que involucran la obtención de licencias (tanto internas como externas), las organizaciones que participan en el proceso de investigación, los socios farmacéuticos, etc. Esta organización es un excelente ejemplo de por qué la tecnología emergente es una buena opción para consolidar tanto el análisis de datos clínicos como no clínicos.
Rápido crecimiento en el desarrollo clínico
El número de ensayos clínicos en curso incrementa cada año en todo el mundo. En los últimos cinco años más de 75.000 pruebas fueron apoyadas por el gobierno federal y privado, con una creciente tendencia de ensayos realizados en Brasil, Rusia, India y China.
Con una amplia gama de diseños de estudios, la recopilación de datos varía métodos y tiempos. El desarrollo se ha vuelto más importante que nunca. Cuando más efectivos sean los datos que se gestionan durante el estudio, más rápido podrá ser extraída y analizada la información. Por ejemplo, durante las primeras etapas de un ensayo clínico el acceso a los datos es vital no solo para la seguridad del paciente, sino también para resolver problemas.
TIBCO Spotfire, plataforma que puede ayudarte en la investigación clínica
La recopilación de datos clínicos, filtrado, análisis y reporte son pasos lentos y caros. Este esfuerzo se agrava a medida que aumenta el número de ensayos. El software TIBCO Spotfire permite agilizar el análisis de datos de ensayos clínicos con acceso en tiempo real a datos clínicos durante las fases de desarrollo, permitiendo al usuario que interactúe con la información tan pronto como se recopile. Lo que hace que este software sea único y poderoso es su capacidad de producir visualizaciones interactivas que permiten al usuario explorar fácilmente los datos.
Monitorización y revisión de datos
Evaluar el nivel del paciente y los datos de seguridad asociados a cada etapa es un aspecto esencial en la realización de un ensayo eficaz. Además de analizar los datos a nivel del paciente, TIBCO Spotfire puede analizar datos operacionales o periféricos.
Revisión de datos más rápida, evaluación de calidad y mejora de procesos
Los beneficios de explorar antes datos cruciales (efectos adversos, demografía, exposición al fármaco y respuesta) en los procesos clínicos son numerosos. Esto permite reducir errores, mejorar en calidad e incrementar la productividad un 20-40%. Algunos beneficios son:
- Evaluación de los datos más rápida y de mejor calidad.
- Disminución de la saturación de bases hasta un 50%.
- Mejoras fundamentales del proceso.
- Identificación temprana de violaciones del protocolo.
- Identificación temprana de abandonos.
- Mejor administración, pudiendo ahorrarse 20K $ por paciente.
Gráficos clínicos
Una organización típica invierte mucho tiempo en crear gráficos estadísticos. Otras muchas organizaciones crean gráficos mediante procesos ad-hoc de desarrollo bajo demanda, seguido de un largo proceso de calidad para, finalmente, introducir esta gráfica en el proceso de producción. Si el usuario quisiera realizar algún sencillo cambio, el costoso proceso realizado anteriormente debería repetirse.
Una prueba típica contiene 8-10 gráficas creadas a partir de procesos ad-hoc. Para una compañía farmacéutica que realice 150 pruebas, con 30 empleados a tiempo completo, esto representa un coste de 5.4 millones de dólares. TIBCO Spotfire puede ayudar en el proceso clínico creando gráficas estadísticas con la inclusión de la información obtenida durante el estudio.
Ventajas de TIBCO Spotfire
¿Qué ventajas tiene TIBCO Spotfire frente a otras aplicaciones clínicas? En comparación, este software ofrece más capacidades, flexibilidad y mejor eficiencia. El formato es fácil de usar y proporciona visualizaciones in vivo interactivas. Entre las principales razones para elegir TIBCO Spotfire destaca:
- Acceso y actualización de los datos clínicos a tiempo real, permitiendo el acceso a sistemas de gestión de datos clínicos, sistemas de captura de datos electrónicos, SAS, SDD, SAS/SHARE, farmacovigilancia y sistemas de desarrollo clínico federado.
- Múltiples áreas de uso además de la revisión de datos clínicos.
- Gráficos superiores.
- Fácil de usar por analistas, autores y revisores.
- Robustez.
- Ad-hoc, análisis de simulación y filtrado instantáneo.
- Exploración interactiva de gráficos.
- Integración con varios almacenes de datos.
¿Le interesa conocer cómo mejorar y obtener mejores resultados? no dude en preguntarnos.
- Detalles
- Categoría: Comsol
- Visto: 10789
por Magnus Ringh
El uso de piezas de geometría, creadas por el usuario o agregadas desde cualquiera de las bibliotecas de piezas disponibles con el software COMSOL Multiphysics® y algunos de sus módulos adicionales, puede simplificar enormemente la construcción de geometrías más complejas para sus simulaciones. En esta entrada del blog de COMSOL le mostramos cómo puede agregar y hacer uso de partes de geometría y crear bibliotecas de partes definidas por el usuario.
Partes de geometría e instancias de partes
Las herramientas de CAD que están disponibles para crear geometrías con COMSOL Multiphysics incluyen una serie de las llamadas primitivas geométricas: formas geométricas básicas como bloques, conos, cilindros, esferas, pirámides y toros en 3D. Estas primitivas geométricas pueden combinarse para formar geometrías más complejas que sean utilizadas en las simulaciones.
Las partes de geometría proporcionan una forma de reproducir y parametrizar tales geometrías complejas. Se pueden usar para simplificar la creación de geometrías al proporcionar piezas fáciles de usar con una serie de parámetros para adaptar la forma o dimensión de la pieza cuando se agregan a una geometría COMSOL de multifísica.
Cuando se agregan partes de geometría (creadas directamente en el modelo o tomadas de una biblioteca de partes), se convierten en instancias de parte en la geometría activa, donde aparecen como cualquier otra característica de geometría como parte de la secuencia de geometría que define la geometría completa utilizada para las simulaciones. En la ventana de Ajustes para las instancias de geometría, puede definir la forma, la dimensión y la ubicación de la instancia de la pieza especificando los valores de los parámetros de entrada que se han definido para la parte de la geometría y la posición y orientación de la parte instanciada (relativa a la global sistema de coordenadas o un plano de trabajo definido por el usuario).
Cuando se crea una parte de geometría (en Definiciones globales en el Generador de modelos), se tiene acceso a las mismas características de CAD que están disponibles en las secuencias de geometría que utiliza para definir las geometrías de los componentes del modelo: todas las primitivas geométricas; Planos de trabajo con extrusiones asociadas, rotaciones y barridos; y otras herramientas de geometría. Para partes más avanzadas, también puede usarse la programación agregando nodos If , Else If , Else y End If para, por ejemplo, usar algún parámetro para controlar ciertos aspectos de la parte. Además, puede añadirse la comprobación de parámetros.nodos para emitir un error si, por ejemplo, el usuario ingresa un valor de parámetro que está fuera del rango para una parte realista. Pueden definirse partes de geometría para geometrías 1D, 2D y 3D.
Para la parametrización, puede agregar parámetros de entrada para la parte de geometría directamente en la ventana Configuración para el nodo Parte principal . Esos parámetros de entrada están disponibles para los usuarios de la parte cuando la agregan como una instancia de la parte. Además, puede agregar un subnodo de Parámetros locales para definir parámetros adicionales que se usarán localmente dentro de la parte que el usuario no necesita especificar.
- Detalles
- Categoría: Maple
- Visto: 8042
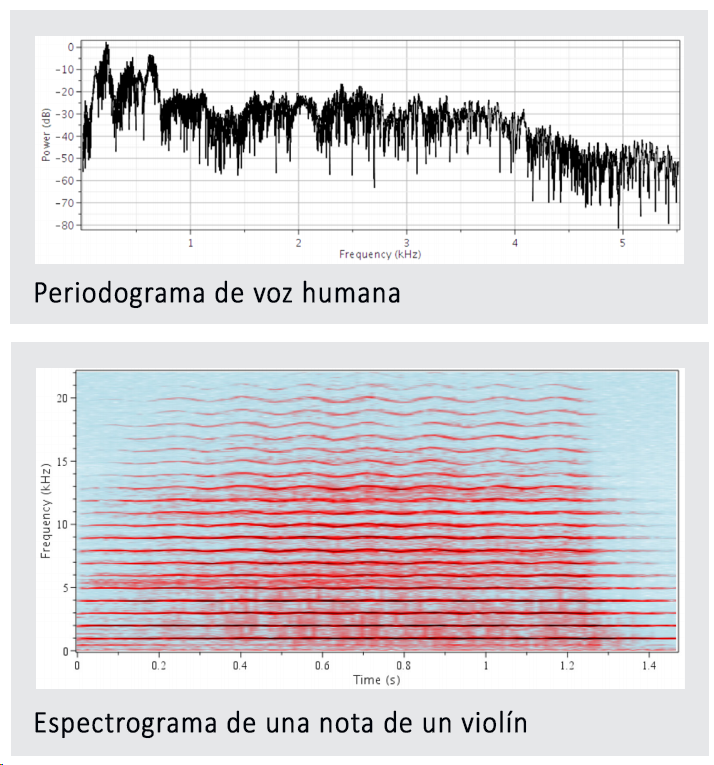
El procesado de señal nos permite transformar, analizar y utilizar la vasta cantidad de información de nuestro mundo digital. Las técnicas de procesado de señal son utilizadas ampliamente por un extenso abanico de ingenieros:
• Un ingeniero biomédico puede querer suavizar la presión sanguínea y los datos del pulso,
• Un ingeniero de automoción puede querer analizar el sonido de un motor para identificar las frecuencias características, o
• Un ingeniero eléctrico puede querer modelar la transmisión de ultrasonidos a través de un medio con ancho de banda.
Los entornos de procesado de señal tradicionales son normalmente solo herramientas programables y mientras que pueden ser de ayuda para hacer la batería de cálculos, no maximizan el valor del trabajo. El valor del trabajo es la suma de varios factores tangibles e intangibles, e incluye:
• cálculos - el núcleo de nuestros análisis
• documentación – los procesos de pensamiento y asunciones detrás de los cálculos
• distribución – los métodos con los que los análisis pueden ser compartidos con clientes y colegas
• extensibilidad – el grado con el que los análisis pueden ser ampliados para diferentes o más sofisticados problemas
• auditabilidad – la facilidad con la que puede ser verificado el trabajo por el autor o por cualquiera, y
• fiabilidad – el grado en el que uno puede fiarse de los cálculos.
La mayoría de las herramientas de procesado únicamente se enfocan en el primero de los requerimientos - los cálculos. Maple, sin embargo, proporciona un entorno en el que son satisfechos todos los requerimientos; esto, en efecto, ayuda a gestionar el trabajo técnico. Descárguese este documento técnico donde se explora el valor que proporciona Maple a los análisis de procesado de señal.
- Detalles
- Categoría: Signals Notebook
- Visto: 31942

Enero/Febrero 2019
Novedades químicas: Sales y compuestos solvatados
Los químicos ahora pueden asociar sales y solvatos, complejos o fraccionados, a reactivos y productos. Se pueden agregar múltiples sales y/o solvatos a cualquier reactivo y/o producto. El reactante/nombre del producto, fórmula molecular y fórmula en masa se ajustan de acuerdo a esto.
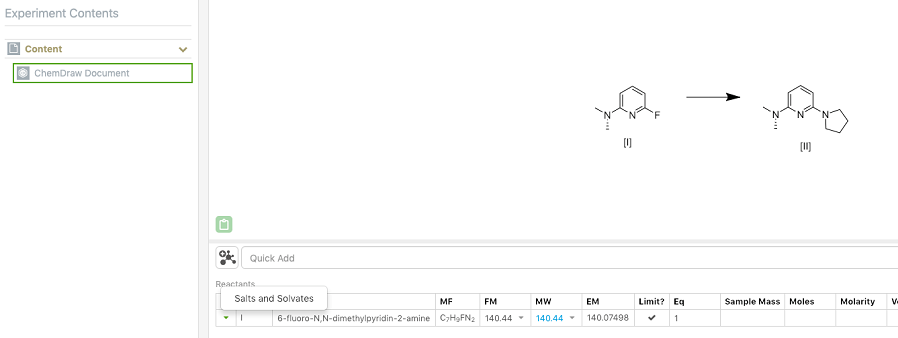
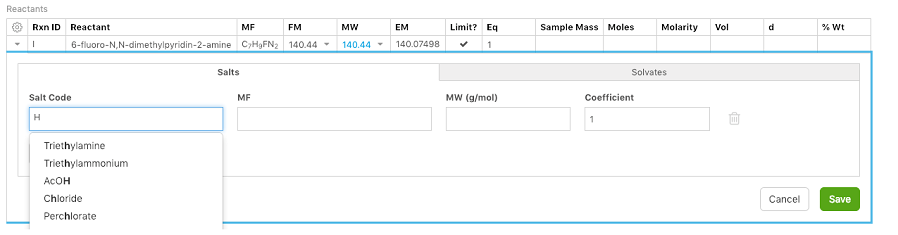
Si la sal o solvato requerido no se encuentra en la lista disponible, puede agregarla usted mismo introduciéndola de forma manual.
Actualizaciones en la interfaz del usuario
Los comentarios del experimento aparecen ahora en el panel de la izquierda, permitiendo así una mejor visualización del contenido del experimento.
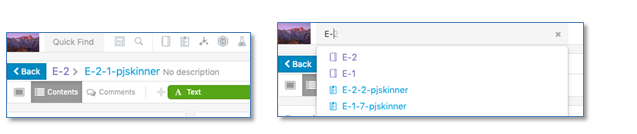
La búsqueda rápida, que permite realizar búsquedas sencillas de texto, se ha movido a la barra de herramientas superior para que sea más accesible. La búsqueda rápida admite el acceso a los marcadores guardados y la búsqueda de texto con la predicción de escritura actualizada.
Actualizaciones en tabla de reactivos y productos
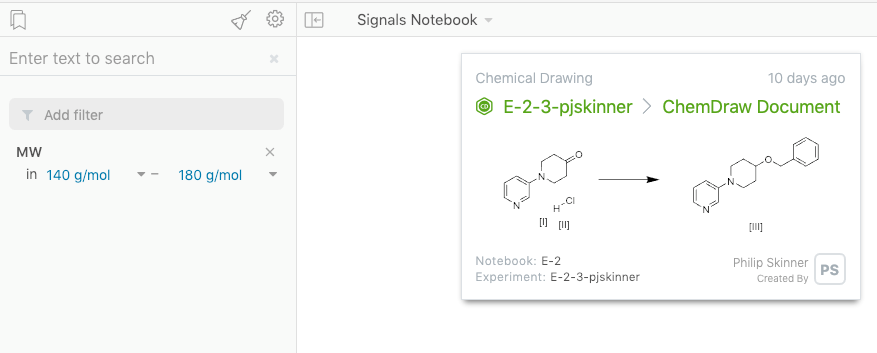
Se agregó un campo adicional para “peso molecular” (MW) para reactivos y productos, además de la “fórmula de masa” (FM) ya existente.
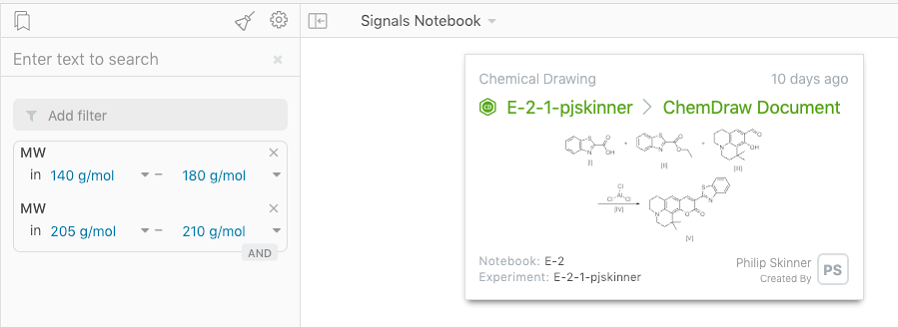
Aquellas propiedades que admiten múltiples valores dentro de un mismo documento ahora permiten el uso del filtro “Y”. Como ejemplo, puede utilizarse para propiedades que podemos encontrar en las tablas de reactivos en aquellos experimentos donde podría realizarse un filtrado en función del peso molecular de varios reactivos.
Actualizaciones administrativas
Estas prestaciones sólo se encuentran disponibles para usuarios y administradores de Signals Notebook Standard o Private Cloud, pero no están permitidas para Signals Notebook Individual Edition.
Los administradores ahora pueden modificar la política de seguridad para excluir el texto personal y las plantillas de experimentos, de tal forma que las mismas no se compartan.

La vista del historial de las tablas de materiales en experimentos se ha actualizado para mostrar el antes y el después de los cambios que se realice.
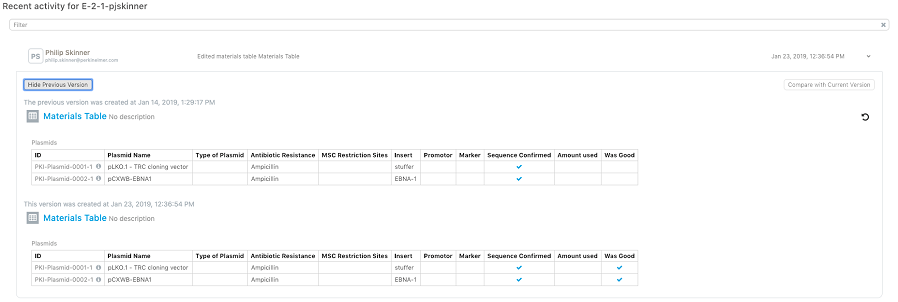
Archivo de E-Notebook
El archivo de E-Notebook Enterprise se ha mejorado para permitir la sincronización de E-Notebook a Signals Notebook. También se ha agregado la búsqueda de texto de tablas y listas de propiedades.
Esta prestación sólo está disponible para clientes de Signals Notebook Standard o Private Cloud y requiere licencias y servicios adicionales. No está disponible para usuarios de Signals Notebook Individual Edition.
- Detalles
- Categoría: Minitab
- Visto: 65439

Cuando trabajaba en el departamento de soporte técnico de Minitab, los clientes a menudo me preguntaban: "¿Cuál es la diferencia entre Cpk y Ppk?" Es una buena pregunta, especialmente porque muchos usuarios utilizan Cpk por defecto, pasando por alto Ppk. Es como el dúo pop de los 80 ¡Wham!, donde Cpk es George Michael, y Ppk es ese otro tipo.
Vaporosos peinados realizados con espuma, hombreras y calentadores, comencemos por definir que son los subgrupos racionales y luego exploremos la diferencia entre Cpk y Ppk.
Subgrupos racionales
Un subgrupo racional ees un grupo de medidas producidas bajo el mismo conjunto de condiciones. Los subgrupos están destinados a representar una instantánea de un proceso. Por lo tanto, las medidas que forman un subgrupo deben tomarse desde un punto similar en el tiempo. Por ejemplo, si se muestrean 5 elementos cada hora, el tamaño del subgrupo sería 5.
Fórmulas, Definiciones, etc.
El objetivo del análisis de capacidad es asegurar que un proceso sea capaz de cumplir con las especificaciones del cliente, y utilizamos estadísticas de capacidad como Cpk y Ppk para realizar esta evaluación. Si observamos las fórmulas de Cpk y Ppk para la capacidad de un proceso (de distribución) normal, podemos ver que son prácticamente idénticas:
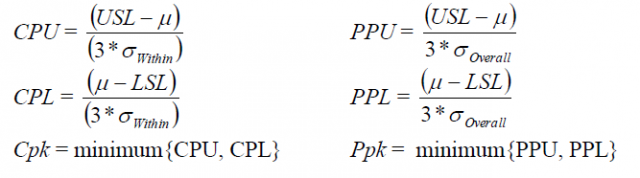
La única diferencia radica en el denominador para las estadísticas Superior e Inferior: Cpk se calcula utilizando la desviación estándar DENTRO, mientras que Ppk utiliza la desviación estándar TOTAL. Sin aburrir con los detalles que rodean a estas fórmulas para las desviaciones estándar, hay que pensar en la desviación estándar dentro como el promedio de las desviaciones estándar del subgrupo, mientras que la desviación estándar total representa la variación de todos los datos. Esto significa que:
Cpk:
- Solo tiene en cuenta la variación DENTRO de los subgrupos
- No tiene en cuenta el cambio y la deriva entre subgrupos
- A veces se la denomina capacidad potencial porque representa el potencial que tiene su proceso para producir piezas dentro de las especificaciones, suponiendo que no hay variación entre los subgrupos (es decir, a lo largo del tiempo)
Ppk:
- Tiene en cuenta la variación TOTAL de todas las medidas tomadas
- Teóricamente incluye tanto la variación dentro de los subgrupos como el cambio y la deriva entre ellos
- Es donde estás al final del día proverbial
Ejemplos de la diferencie entre Cpk y Ppk
Como ejemplo ilustrativo, consideremos un conjunto de datos donde se tomaron 5 medicioines cada día durante 10 días.
Ejemplo 1 - Cpk y Ppk similares
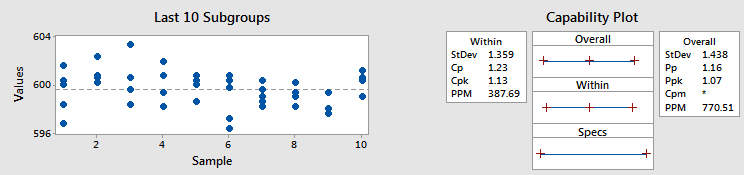
Como muestra el gráfico de la izquierda no hay muchos cambios y desviaciones entre los subgrupos en comparación con la variación dentro de los propios subgrupos. Por lo tanto, las desviaciones estándar dentro y total son similares, lo que significa que Cpk y Ppk son similares, también (a 1.13 y 1.07, respectivamente).
Ejemplo 2 - Cpk y Ppk diferentes
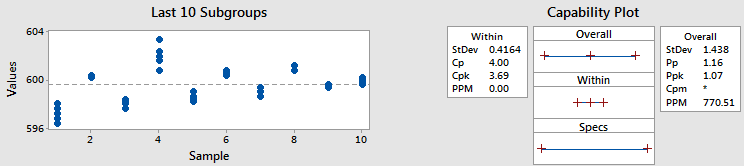
En este ejemplo, utilicé los mismos datos y el mismo tamaño de subgrupo, pero cambié los datos, moviéndolos a diferentes subgrupos. (Por supuesto, en la práctica nunca querríamos pasar datos en diferentes subgrupos - lo he hecho aquí para ilustrar un punto.)
Como se utilizaron los mismo datos, las desviación estándar total y Ppk no cambiaron. Pero ahí es donde acaban las similitudes.
Miremos la estadística Cpk. Es 3.69, que es mucho mejor que el 1.12 que obtuvimos antes. Mirando el gráfico de los subgrupos, ¿sabemos por qué aumentó Cpk? La gráfica muestra que los puntos dentro de cada subgrupo están mucho más cerca que antes. Anteriormente mencionamos que podemos pensar en la desviación estándar dentro como el promedio de las desviaciones de estándar del subgrupo. Por lo tanto, una menor variabilidad dentro de cada subgrupo es igual a una desviación estándar más pequeña.Y eso nos da un Cpk más álto.
Un Ppk o no un Ppk
Y aquí es donde está el peligro, en solo informar un Cpk y olvidarse de Ppk como si fuera el compañere de la banda menos conocido de George Michael (sin ofender a quienquiera que sea). Podemos ver en los ejemplos anteriores que Cpk solo nos cuenta parte de la historia, por lo que la próxima vez que se examine la capacidad de un proceso hay que considerar tanto Cpk como Ppk. Y si el proceos es estable con poca variación con el tiempo, las dos estadísticas deberían ser casi iguales.
(Nota: Es posible, y está bien, obtener un Ppk que sea más grande que Cpk, especialmente con un tamaño de subgrupo de 1, pero dejaremos la explicación para otro día.)
- Detalles
- Categoría: Minitab
- Visto: 10303

Un aspecto destacado de escribir y editar el blog de Minitab es la oportunidad de leer sus respuestas y responder a sus preguntas. A veces, para mi disgusto, nos indican que hemos cometido un error. Sin embargo, estoy particularmente agradecido por esos comentarios, ya que nos permite corregir errores involuntarios.
Pensé que tenía la oportunidad de corregir un error cuando vi que este comentario aparecía en una de nuestras publicaciones de blog más antiguas:
Usted dijo que un p-valor mayor que 0.05 da un buen ajuste. Sin embargo, en otra publicación, usted dijo que el p-valor debería estar por debajo de 0.05 si el resultado es significativo. ¡Por favor, míralo!
¿Alguna vez le han entrado escalofrios cuando se ha dado cuenta de que se ha equivocado? Eso es lo que sentí cuando leí ese comentario. Oh no, pensé. Si el p-valor es mayor que 0.05, los resultados de una prueba ciertamente no serían significativos. ¿Pasé por alto un error tan básico?
Antes de automachacarme, decidí revisar las publicaciones en cuestión. Después de revisarlas, me di cuenta de que no tendría que ponerme la camiseta después de todo. Pero la pregunta me recordó la importancia de una idea fundamental.
Comienza con la Hipótesis
Si en algún momento ha realizado un curso introductorio de estadística, probablemente recordará que el profesor le explicó a la clase lo importante que es formular sus hipótesis con claridad. Excelente consejo.
Sin embargo, muchas herramientas estadísticas comunmente utilizadas formulan sus hipótesis de forma que no coinciden. Eso es lo que este agudo comentarista notó y señaló.
El autor de la primera publicación detalló cómo usar Minitab para identificar la distribución de los datos, y en su ejemplo señaló que un p-valor mayor a 0.05 significaba que los datos se ajustaban a una distribución dada. El autor del segundo post, el suyo realmente, comentó la alarmante tendencia a utilizar un lenguaje engañoso para describir un alto p-valor como si indicara una significación estadística.
Para ponerlo en un lenguaje plano, el post de mi colega citaba el alto p-valor como un indicador de un resultado positivo. Y mi publicación reprendió a las personas que citan un alto p-valor como un indicador de un resultado positivo.
Ahora, ¿qué es lo que es tan confuso?
No olvidar lo que realmente se está comprobando
Puede ver dónde ésto parece una contradicción, pero para mi alivio, las publicaciones fueron consistentes. La aparición de la contradicción se deriva de las hipótesis discutidas en los dos mensajes. Vamos a verlo.
Mi colega presentó este gráfico, obtenido de la Identificación de Distribución Individual:
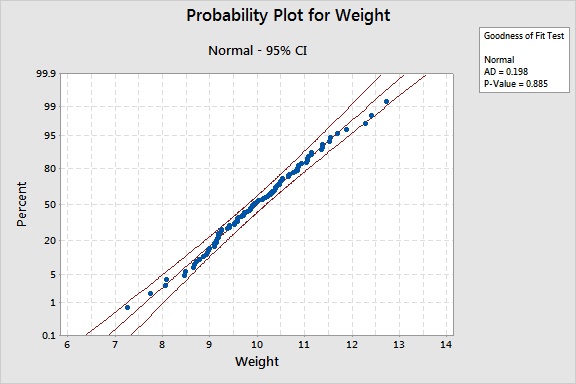
La identificación de distribución individual es un tipo de prueba de hipótesis, y por tanto el p-valor ayuda a determinar cuando se debe o no rechazar la hipótesis nula.
Aquí, la hipótesis nula es "Los datos siguen una distribución normal," y la hipótesis alternativa sería "Los datos NO siguen una distribución normal." Si el p-valor es mayor que 0.05, no podremos rechazar la hipótesis nula y concluiremos que los datos siguen la distribución normal.
Echemos un vistazo a ese p-valor:
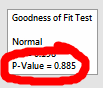
Es un p-valor alto. Y para esta prueba, eso significa que podemos concluir que la distribución normal se ajusta a los datos. Así que si estamos verificando la asunción de normalidad de estos datos, este alto p-valor es bueno.
Pero muy a menudo buscamos un p-valor bajo. En una prueba t, la hipótesis nula podría ser "las medias de la mustra NO SON diferentes," y la hipótesis alternativa, "Las medias de la muestra SON diferentes." Visto de esta manera, el valor o disposición de la hipótesis es opuesto al de la identificación de la distribución.
De ahí, la aparente contradicción. Pero en ambos casos un p-valor mayor que 0.05 significa que no podemos rechazar la hipótesis nula. Estamos interpretando el p-valor en cada prueba de la misma manera.
Sin embargo, como las connotaciones de "bueno" y "malo" son diferentes en los dos ejemplos, la manera de hablar sobre estos p-valores respectivos parecen contradictorios-hasta que consideramos exactamente lo que están diciendo la hipótesis nula y la alternativa.
Y ese es un punto importante que me alegra recordar.