- Detalles
- Categoría: Maple
- Visto: 13105
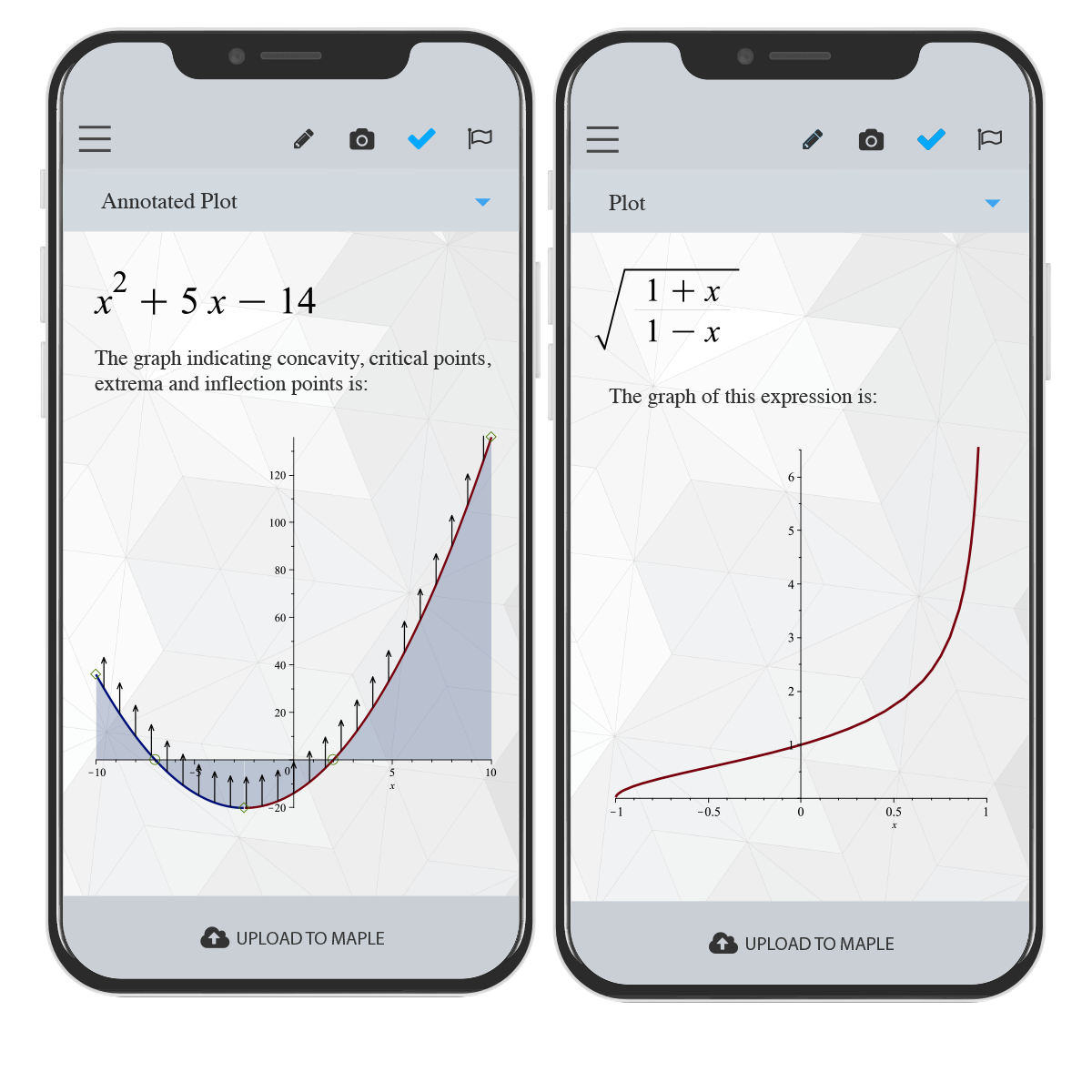
La aplicación móvil de Maplesoft resuelve problemas matemáticos complejos
¡Obtén ayuda en tus tareas de matemáticas! Con la aplicación gratuita Maple Companion, puedes verificar las respuestas a problemas de álgebra, precálculo, cálculo, álgebra lineal, ecuaciones diferenciales y más, utilizando la cámara de tu teléfono. Y si eres usuario de Maple, también puede usar el Maple Companion para llevar las matemáticas que tienes en frente a Maple, donde puedes acceder a todo el poder de Maple para resolver, visualizar y explorar tus matemáticas.
Maplesoft ™ acaba de lanzar una nueva versión de Maple ™ Companion, una aplicación móvil gratuita que ayuda a los estudiantes a aprender matemáticas y complementa al producto de software matemático Maple. El lanzamiento inicial utilizaba la cámara del teléfono para traer expresiones matemáticas a Maple, donde las matemáticas pueden resolver, visualizar, analizar y explorar. La nueva versión agrega poder matemático a la aplicación en sí, para que los estudiantes puedan resolver una amplia variedad de problemas matemáticos directamente en su teléfono y luego pasar fácilmente a Maple para realizar exploraciones más avanzadas.
Con la aplicación gratuita Maple Companion, los estudiantes pueden comprobar las respuestas a problemas de álgebra, precálculo, cálculo, álgebra lineal, ecuaciones diferenciales y más, utilizando la cámara de su teléfono. Pueden encontrar integrales, factorizar polinomios, invertir matrices, resolver sistemas de ecuaciones, resolver ecuaciones diferenciales y realizar muchas otras operaciones matemáticas simples y avanzadas. La aplicación también produce visualizaciones de expresiones matemáticas, que ayudan a los estudiantes a profundizar en la comprensión de sus problemas y soluciones.
Para introducir problemas en Maple Companion los usuarios simplemente toman una foto de las ecuaciones matemáticas usando su teléfono. Las matemáticas pueden estar en notas escritas a mano, un libro de texto, una pizarra o en cualquier otro lugar donde aparezcan las matemáticas. Con esta nueva versión, los usuarios también tienen la opción de incluir problemas manualmente utilizando un editor matemático incorporado. Incluso pueden combinar los dos enfoques, comenzando con una imagen de las matemáticas y luego utilizando el editor para realizar cambios.
"Una de las mejores maneras para que los estudiantes de cursos basados en matemáticas determinen si han entendido un concepto es verificar las respuestas a los problemas de sus tareas para casa. A menos que la respuesta esté al final del libro, esto no es fácil de hacer, pero con Maple Companion, los estudiantes pueden verificar sus respuestas literalmente con un clic de su cámara ", dice Karishma Punwani , Directora de Gestión Académica de Productos en Maplesoft. "Y cuando se combina con Maple, Maple Companion ofrece a los estudiantes la oportunidad de mejorar su aprendizaje aún más, como determinar dónde se equivocaron, obtener práctica adicional o explorar problemas relacionados".
La aplicación gratuita Maple Companion está disponible en Apple App Store para iOS y en Google Play para usuarios de Android.
- Detalles
- Categoría: Minitab
- Visto: 3986
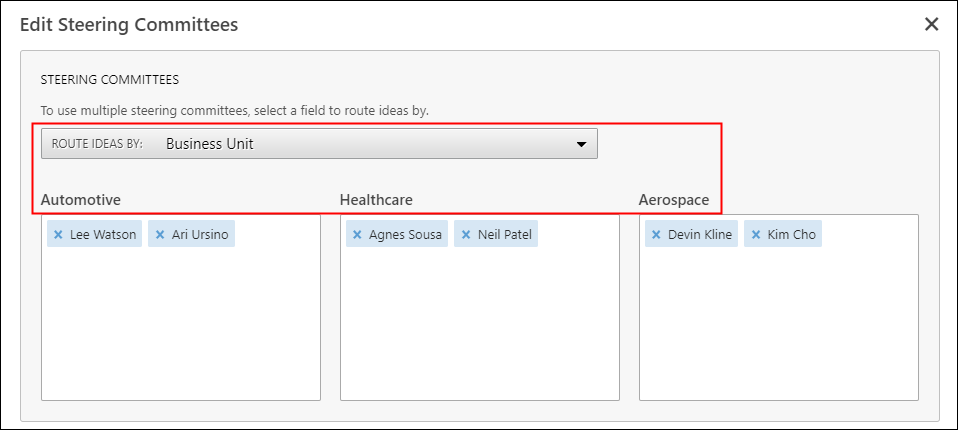
Las grandes organizaciones ahora tienen un mejor flujo de trabajo en Companion 5.4: Múltiples comités directivos
Con la última actualización gratuita de Companion, las organizaciones ahora tienen flexibilidad añadida de dirigir las ideas de proyectos a comités directivos específicos cuando se utiliza la funcionalidad de flujo de trabajo. Los comités directivos evalúan las ideas de proyecto y ayudan a llevarlas a cabo a través de fases de ejecución críticas.
Para actualizar su versión desktop a la versión completa (con web application) que incluye las funcionalidades de tablero de control en línea y flujo de trabajo como gestión de ideas, un tanque de proyectos, revisión de etapas formales, email de notificaciones y seguimiento de cambio de campos - por favor contacte con el departamento comercial de Addlink.
- Detalles
- Categoría: Minitab
- Visto: 4615
Por Evan McLaughlin.
En entornos hospitalarios y clínicos, tomar las decisiones correctas no solo reduce los costes del trabajo duplicado y las ineficiencias de los procesos, sino que da como resultado mejores resultados para los pacientes. Pensemos en la necesidad de tomar una radiografía adicional porque la primera captó el pie equivocado. Incluso si es la extremidad correcta, ¿qué pasa si se realizó desde el ángulo incorrecto?
Durante los 14 años que trabajó en la mejora de la calidad de la atención médica, Art Wheeler vio este y muchos otros escenarios de mejora de procesos. Más recientemente, como gerente de soporte de decisiones para servicios de mejora de la calidad en una de las redes de salud pediátrica independientes más grandes del país, sin fines de lucro, fue el estadístico principal, así como mentor y entrenador del programa Six Sigma Black Belts y Green Belts, directores de programa y jefes de proyecto durante 8 años y medio.
Como experto en control estadístico de la calidad, una de sus principales responsabilidades era asegurarse de que los datos se recopilaran de manera sólida y aseguraran las mejores oportunidades para detectar la significación estadística de cualquier mejora reportada. También desarrolló los cuadros y las reseñas de las secciones de análisis de los artículos publicados correspondientes y respondió a las preguntas o comentarios de los revisores para ayudar a garantizar la aceptación.
¿Recuerda el escenario de rayos X extras que mencionamos anteriormente? Art trabajó como consultor en un estudio sobre rayos X duplicados, que encontró que cada exploración innecesaria tiene un coste adicional de 150$ a 300$ y los pacientes en general esperaban más tiempo. Un estudio de 18 departamentos de emergencias pediátricas de EE.UU. mostró que los errores de radiología son el tercer evento más común en las redes de investigación de emergencias pediátricas y los errores humanos en lugar de los problemas del equipo causaron el 87% de ellos.
Además de reducir los errores, el equipo también estaba motivado para lograr el objetivo de tener cero errores en dos clínicas para que también pudieran reducir la exposición a la radiación de por vida para las personas, lo que a su vez disminuiría su riesgo de desarrollar cáncer. Esfuerzos como este eran parte del programa "Zero Hero" del hospital: medirían el período de tiempo y la cantidad de casos involucrados, tratarían de reducir los incidentes a cero y registrar cuánto tiempo mantuvieron cero incidentes.
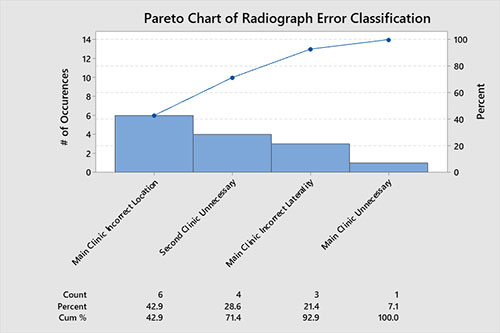
Sin embargo, no todo era blanco o negro. Necesitaban comprender el contexto existente detrás de los rayos X duplicados para realmente hacer mejoras. Con una revisión retrospectiva de un período de 14 meses en dos instalaciones, sabían que había buenas y malas razones detrás de los más de 170 rayos X duplicados que se grabaron, para una radiografía duplicada. Cada radiografía duplicada se clasificó como ...
- Sin error, donde intencionalmente estudiaron desde múltiples puntos de vista;
- Ubicación incorrecta, cuando la queja inicial del paciente no coincide con la radiografía inicial (por ejemplo, el pie equivocado mencionado anteriormente);
- Lateralidad incorrecta, cuando es el lado equivocado; o
- Radiografía innecesaria, un problema conocido cuando un entrenador de atletismo clínico pidió múltiples radiografías sin evaluación y valoración del médico.
El siguiente cuadro de Pareto muestra que el error más común durante el período de 14 meses fue la ubicación incorrecta.
El equipo de mejora de la calidad tomó medidas para cumplir con su objetivo de cero por ciento en ambas clínicas, que incluyeron la realización de encuestas a pacientes y familias durante el registro para ayudar a documentar dónde debían someterse a rayos X y si habían recibido rayos X en el pasado.
La radiografía innecesaria también fue un problema conocido cuando un entrenador atlético clínico ordenó múltiples radiografías sin evaluación y valoración del médico. Se realizó una intervención para solucionar esto, haciendo que los médicos sean responsables de poner sus propias órdenes de radiografía en el Registro Médico Electrónico.
En general, estos pasos mejoraron la comunicación entre médicos, entrenadores clínicos, tecnólogos de radiología, pacientes y familias, y contribuyeron en gran medida a mejorar resultados para todos los involucrados.
- Detalles
- Categoría: Comsol
- Visto: 4279
Todos los productos de software de COMSOL® se han visto sometidos a mejoras de estabilidad que se han introducido como actualizaciones. La siguiente lista contiene las mejoras más importantes de la versión COMSOL® 5.5 update 1.
COMSOL Multiphysics®
- Para el complemento de Controlador PID, los coeficientes de los términos proporcional e integral han cambiado sus signos para seguir las convenciones estándar, y ya no es más necesario especificar unidades para los coeficientes o los términos cuando el valor es 0.
- Los requisitos del sistema para el gestor de licencias han sido ampliados para soportar ahora también Debian® 6, Red Hat® Enterprise Linux®/CentOS 6, y SUSE® Enterprise Linux® 11.4 y posteriores.
Heat Transfer Module
- Para radiación en medios semitransparentes, ahora se han habilitado las propiedades dependientes de la longitud de onda para geometrías axisimétricas 2D.
Optimization Module
- Los métodos de optimización libres de derivada ahora soportan la funcionalidad de optimización de forma de Contorno Polinomial.
Si tiene instalada la interfaz de PowerPoint o LiveLink for Excel y tiene al menos uno de estos programas corriendo durante el proceso de actualización, visualizará un mensaje de advertencia durante la actualización. Salga tanto de PowerPoint como de Excel, y entonces haga clic en Try Again.
Debian es una marca registrada o marca de Software in the Public Interest, Inc. en los EEUU. Linux es una marca registrada de Linus Torvalds en los EE.UU. y otros países. Microsoft, Excel, y Windows son marcas registradas o marcas de Microsoft Corporation en los EE.UU. y/o otros países. macOS es una marca de Apple Inc., en los EE.UU. y otros países. MATLAB es una marca registrada de The MathWorks, Inc. Red Hat Enterprise Linux es una marca registrada de Red Hat, Inc. SUSE es una marca registrada de SUSE LLC.
- Detalles
- Categoría: Comsol
- Visto: 4809

En Multiphysics Simulation 2019, vea de primera mano cómo se utiliza la simulación de nuevas e innovadoras formas, desde el diseño de motores de vehículos eléctricos para la electrificación del sistema de propulsión hasta para la optimización de un horno de convección de estado sólido para conseguir una cocción rápida y uniforme. Además, lea acerca de cómo la simulación multifísica está ayudando a las personas a experimentar fenómenos físicos de nuevas maneras, incluido un sistema de infoentretenimiento de audio para vehículos de lujo basado en la realidad virtual y un plan de formación que permite a los estudiantes visualizar ondas electromagnéticas más allá del libro de texto. Explore todos los estudios de casos de clientes haciendo clic en el enlace inferior o descárguese la revista completa en pdf.
Áreas temáticas:
|
|
- Detalles
- Categoría: Twinn Witness
- Visto: 4544
Nos complace anunciar que WITNESS Horizon 23.0 ya está disponible, ofreciendo a nuestros clientes una versión de software que contiene muchas de las bases para implementar gemelos digitales predictivos con experimentos de simulación más potentes.
Enfoque de WITNESS 23.0
El desarrollo de WITNESS Horizon 23.0 se basa en un movimiento estratégico para permitir una mayor experimentación y capacidades de optimización para modelos desarrollados en la plataforma WITNESS. Lanner está comprometido con el desarrollo de capacidades analíticas avanzadas para los gemelos digitales de sus clientes, incluida la experimentación paramétrica para el diseño y la optimización de procesos utilizando la potencia de la nube y los clústeres de computación de alto rendimiento (HPC).
El futuro de la tecnología WITNESS
Al haber sido adquirido a principios de 2019 por el gigante de consultoría de ingeniería holandesa Royal Haskoning DHV, Lanner ha podido acelerar su desarrollo tecnológico para la plataforma WITNESS. La hoja de ruta tecnológica de Lanner ahora se centra en la integración de la plataforma WITNESS con otras tecnologías clave de Royal HaskoningDHV, incluidos entornos 3D y diseño de infraestructura, modelado paramétrico, inteligencia artificial e infraestructuras de datos enriquecidos. La versión WITNESS Horizon 23.0 contiene muchos de los elementos básicos que serán un requisito previo para aprovechar estos desarrollos en el futuro cercano.
Características adicionales encontradas en WITNESS 23.0
- Las herramientas de experimentación avanzadas, que incluyen la longitud de ejecución automática y el análisis de réplicas, garantizan que los experimentos alcancen la precisión estadística sin la necesidad de intervención del analista.
- Canal de experimentación optimizado para ayudar a los usuarios a realizar experimentos con muchas simulaciones y obtener los resultados que requieren más rápido que nunca
- Soporte escalable de múltiples núcleos para todos los tipos de licencia que permite a los usuarios utilizar sus recursos locales para ejecutar más simulaciones en el tiempo disponible
- Algoritmo de optimización de templado simulado (Simulated Annealing) mejorado con una capacidad de búsqueda más inteligente basada en el tiempo y los recursos informáticos disponibles
- Varias correcciones y mejoras en las tablas de datos, transportadores continuos, turnos y la API WITNESS Horizon
- Detalles
- Categoría: Signals Notebook
- Visto: 23755

Septiembre 2019
Actualizaciones de usabilidad
Las imágenes grandes ahora se escalan automáticamente para visualizarse mejor en su pantalla. La imagen se amplía aún más a medida que cambia el tamaño de su pantalla y / o ventana. Los cambios posteriores al escalado de la imagen anularán el escalado inicial. La escala puede ingresarse manualmente además de la operación de arrastre actual.
.png)
También hemos agregado más colores para usar en anotaciones de imágenes.
.png)
El archivo de imagen original también se puede incluir opcionalmente en los archivos adjuntos al imprimir en PDF
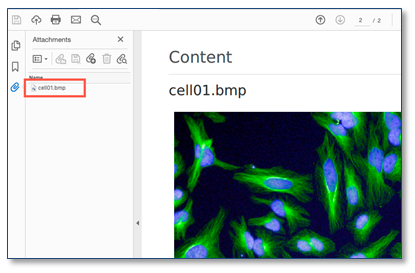
Las propiedades de experimento y plantilla (metadatos) ahora se muestran en línea además de desde la vista de propiedades. Esta nueva vista se puede expandir o contraer como se desee.
.png)
Las siguientes capacidades solo están disponibles para usuarios y administradores de Signals Notebook Standard, E3 o Private Cloud y no están disponibles como parte de Signals Notebook Individual Edition.
Actualizaciones de búsqueda
Las propiedades de búsqueda de las Tablas de materiales, Materiales, Tablas y Muestras ahora tienen como prefijo un encabezado para ayudar a identificar qué propiedad usar para una búsqueda determinada.
.png)
Actualizaciones de tablas
Las tablas ahora admiten la carga de datos desde un archivo .csv.
.png)
Cuando el experimento que contiene una tabla se imprime en PDF y los documentos se incrustan como archivos adjuntos, también se incluye un archivo .csv de la tabla en el PDF.
.png)
Los administradores ahora también pueden definir una nueva propiedad de "Tipo de referencia" en las tablas. Una vez agregado, los usuarios pueden buscar otros elementos en Signals Notebook para hacer referencia dentro de una tabla. La entrada de la tabla actúa como un hipervínculo a ese elemento.
.png)
Actualizaciones de muestras
Las muestras ahora admiten la descarga de datos en un archivo .sdf o .csv. Las propiedades mostradas se incluyen en el archivo de descarga.

Los archivos .csv y .sdf también se incluyen opcionalmente en los archivos adjuntos cuando el experimento se imprime en PDF.
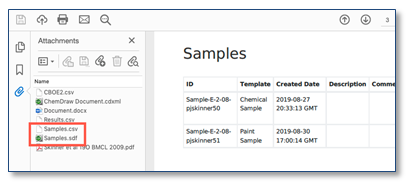
Los valores del campo "Fórmula molecular" (MF) ahora también se pueden editar directamente en la tabla Muestras.

Octubre 2019
Mejoras de la imagen
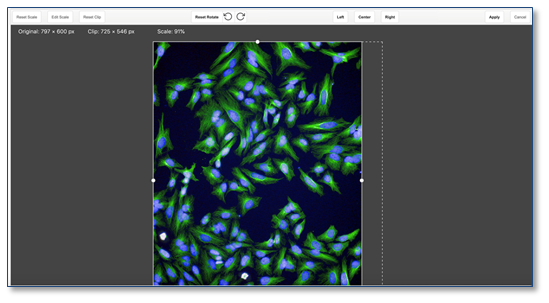
Las imágenes ahora se pueden rotar, si es necesario, cambiando la orientación. La rotación está disponible en la vista "Editar imagen". La rotación de la imagen no rota las anotaciones.
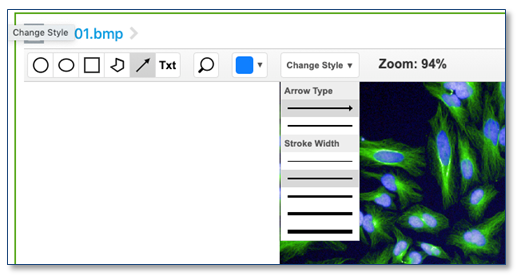
También hemos agregado líneas a la herramienta de anotación de imagen de flecha.
Edición de ida y vuelta de Tibco Spotfire
Si el usuario guarda un archivo de Tibco Spotfire (.dxp) en Signals Notebook, el archivo de Spotfire se puede iniciar en el cliente de Spotfire Analyst para su posterior edición.
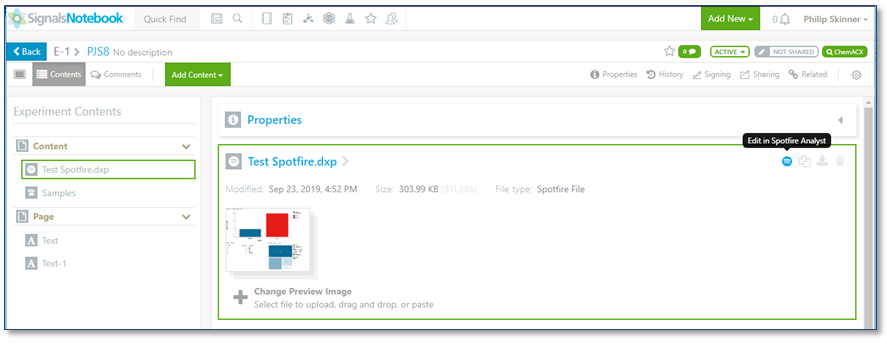
Tenga en cuenta que esta capacidad requiere la instalación del cliente Tibco Spotfire Analyst (7.11 o 10.3) y la instalación de un complemento en el servidor Spotfire por parte del administrador de Spotfire.
Las siguientes capacidades solo están disponibles para usuarios y administradores de Signals Notebook Standard o Private Cloud y no están disponibles como parte de Signals Notebook Individual Edition.
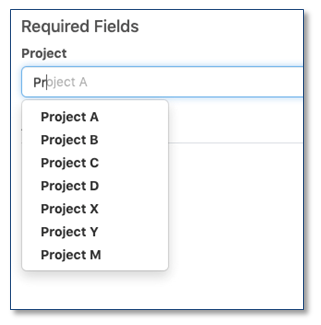
Actualizaciones de atributos
Cuando un administrador ha configurado un Atributo para usar en "Propiedades del experimento" o para usar en "Materiales", "Muestras" o "Tablas", el Usuario ahora tiene una búsqueda de escritura anticipada de valores en lugar de una lista desplegable para facilitar el uso de listas más largas.
Cuando el experimento que contiene una tabla se imprime en PDF y los documentos se incrustan como archivos adjuntos, también se incluye un archivo .csv de la tabla en el PDF.
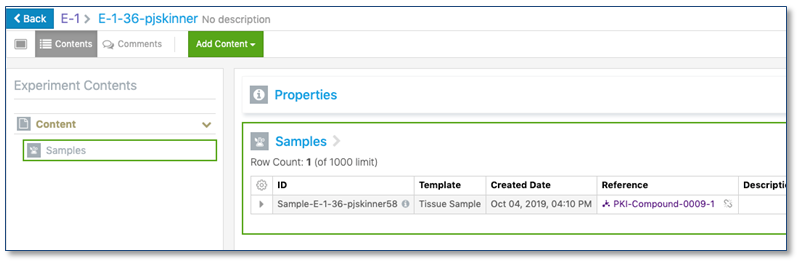
Tipo de propiedad de referencia interna
El tipo de propiedad de referencia interna se ha ampliado para su uso en muestras y tablas de materiales. Los administradores ahora pueden definir propiedades personalizadas para estos elementos que permiten a un usuario final agregar una referencia hipervinculada a otro elemento dentro de Signals Notebook.
Las siguientes capacidades se consideran una versión beta y solo están disponibles para los usuarios y administradores de Signals Notebook Standard o Private Cloud previa solicitud. Estas capacidades no están disponibles como parte de Signals Notebook Individual Edition.
Listas externas
El administrador ahora puede definir las fuentes externas que se utilizarán para los atributos del experimento. Las listas externas se configuran conectándose a una API externa. Se puede identificar el campo clave, un campo adicional que se puede usar como descripción y los campos adicionales que se muestran en Propiedades. Una vez que se configura la fuente, la lista se puede usar como un Atributo e incluirse en las Plantillas del sistema.
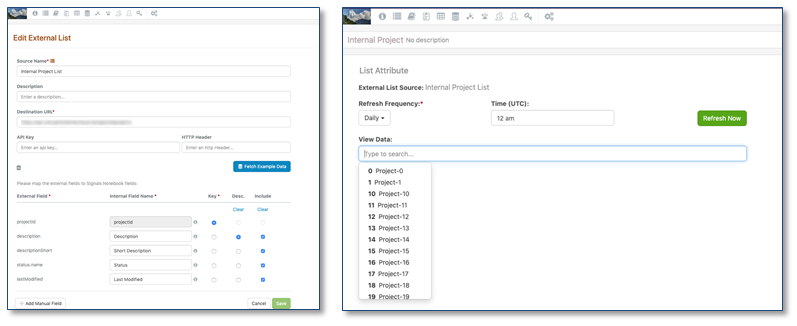
Cuando un usuario final selecciona un valor de atributo, las propiedades asociadas se ven dentro de las propiedades del Experimento.
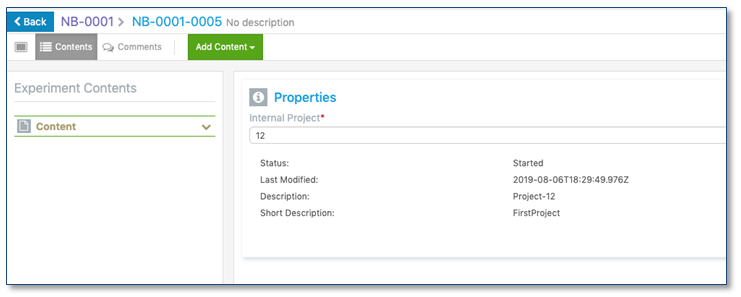
API públicas
Se ha desarrollado un marco inicial para acceder a las API públicas de Signals Notebook. Los administradores tienen acceso en línea a la documentación de la API. Las API iniciales de GET Entity y GET Entity PDF se han lanzado. La configuración y el acceso a la documentación de la API se proporcionan a través de la pantalla "Configuración del sistema" de la consola administrativa (SNCofig).
Diciembre 2019
Mejoras de usabilidad
Se han agregado una serie de solventes y solvatos al sistema. Los solventes se pueden agregar a la tabla de solventes en la reacción. Los solvatos se pueden usar en la ventana sales y solvatos.
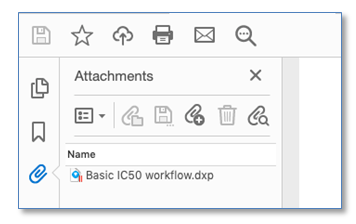
Los archivos Spotfire .dxp ahora se incluyen como un archivo adjunto cuando un experimento se exporta a PDF.
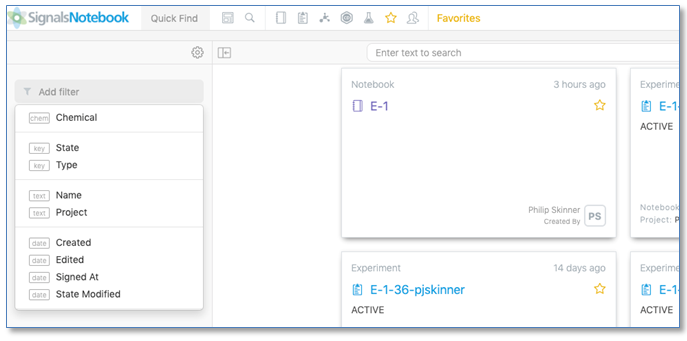
La carpeta Favoritos ahora utiliza la capacidad de búsqueda por filtrado para brindar una mayor flexibilidad y capacidad de recuperación.
Las siguientes capacidades solo están disponible para usuarios y administradores de Signals Notebook Standard o Private Cloud y no están disponibles como parte de Signals Notebook Individual Edition.
Tipo de propiedad de referencia interna
El tipo de propiedad de referencia interna se ha ampliado para incluir ahora Propiedades (Experimento y Cuaderno) y Materiales.
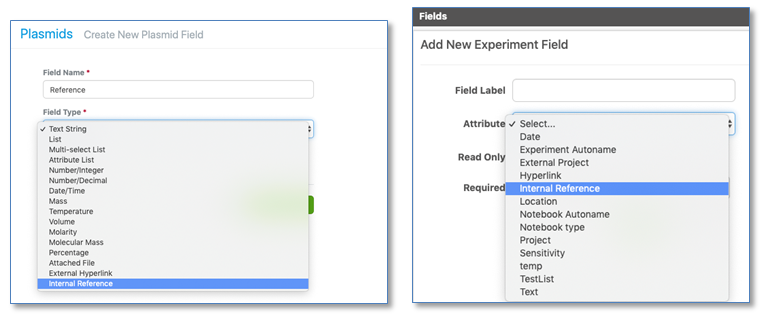
Los administradores pueden definir propiedades de referencia internas para los campos Experimento/Cuaderno en las plantillas del sistema, o en los campos de nivel Activo o Lote en Materiales. Los usuarios finales pueden seleccionar otros objetos dentro de Signals Notebook para crear una referencia a ese objeto
Actualizaciones administrativas
Las plantillas del sistema ahora se comparten con privilegios de edición con todos los miembros del grupo de administradores del sistema, lo que permite a todos los administradores del sistema ver y modificar las plantillas del mismo.
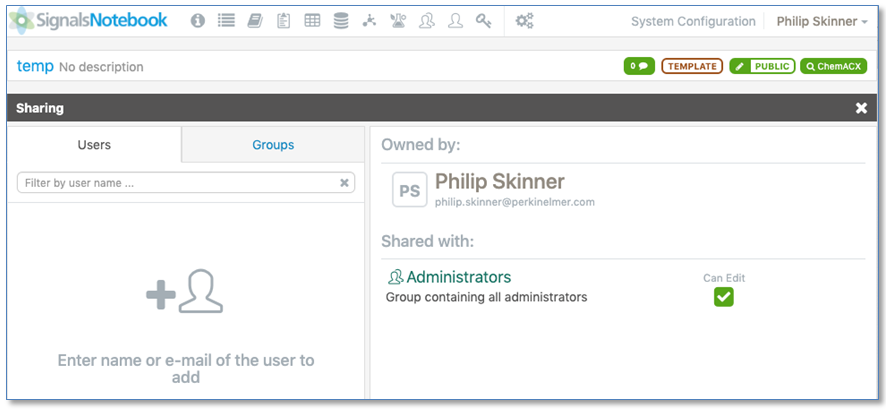
Las plantillas del sistema ya no se comparten a través de ACL sino solo con Compartir.
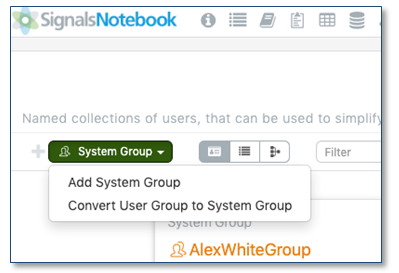
El sistema ahora también diferencia entre los grupos del sistema, utilizados para la seguridad y para compartir las plantillas del sistema y las plantillas de tabla, y los grupos de usuarios creados por los usuarios finales. Solo los grupos del sistema pueden usarse con fines administrativos. Todos los grupos del sistema se comparten con privilegios de edición con todos los miembros del grupo de administradores del sistema, lo que permite a todos los administradores del sistema ver y modificar los grupos del sistema. El administrador del sistema también puede promover un grupo de usuarios existente para que se convierta en un grupo del sistema si es necesario.
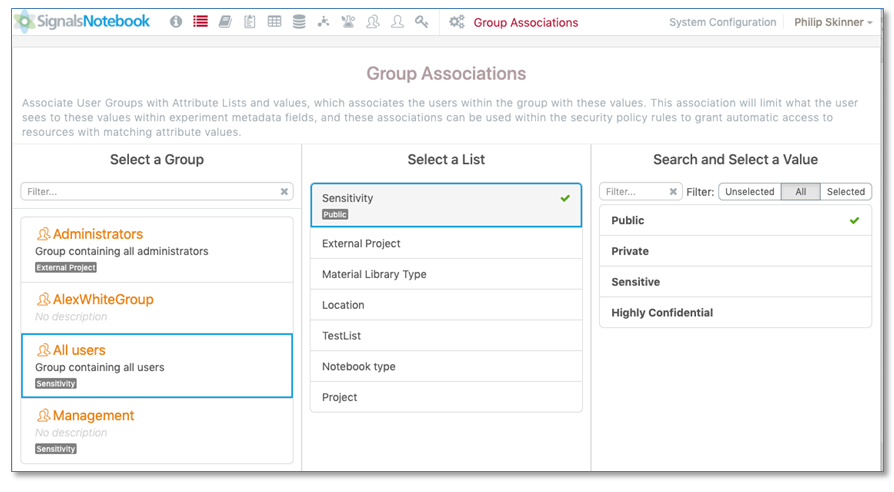
La página de Asociaciones de grupos también se ha mejorado. Los tipos de listas asociadas con Grupos ahora se muestran en los Grupos relevantes. Los valores de las listas ahora también se pueden filtrar, ya sea mediante un filtro de escritura anticipada o mediante el filtrado solo a los valores seleccionados o los valores no seleccionados.
Las siguientes capacidades está en versión beta y solo está disponibles para los usuarios y administradores de Signals Notebook Standard o Private Cloud a solicitud. No están disponibles como parte de Signals Notebook Individual Edition.
Configuración de proxy para fuentes de datos externas, listas externas
Las listas externas y las fuentes de datos externas ahora se pueden conectar a través de un proxy en lugar de directamente a una API de aplicación externa. Conectarse al Proxy permite la simplificación de la experiencia administrativa al conectarse a varios puntos finales API, junto con la capacidad de agregar una configuración personalizada a la transferencia y autenticación de datos.
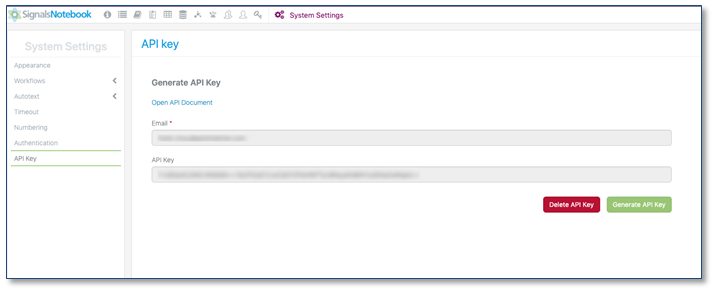
API públicas adicionales
Se han agregado API de entidad GET y PATCH adicionales. Las mejoras continuas de la API continuarán independientemente de las actualizaciones de Signals Notebook.