- Detalles
- Categoría: Minitab
- Visto: 11816
Por Shelby Anderson.
Las capacidades de los datos y su análisis han ocupado un lugar central en los últimos años. El volumen de datos disponibles ha crecido exponencialmente, y la exposición a los análisis ha mejorado constantemente y se ha convertido en un tema objetivo en todas las organizaciones. La convergencia de estas tendencias está impulsando la eficiencia empresarial y la innovación.
Según McKinsey and Company, la oportunidad puede ser inmensa. Aprovechar el poder de los datos puede ayudar a las organizaciones a aprovechar sus propios conocimientos para diferenciar sus productos y servicios en el mercado a través de la innovación y aumentar la eficiencia con estrategias de optimización de costes.
Impacto estimado de la analítica avanzada por función empresarial
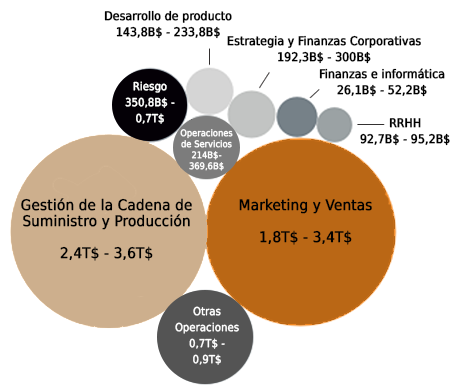
Fuente: Análisis del McKinsey Global Institute
Sin embargo, existen desafíos presentes para las organizaciones que buscan generar valor utilizando el análisis de datos.
- Hay una continua escasez de talento analítico. Para 2020, la cantidad de empleos para todos los profesionales de datos de EE.UU. aumentará de 364.000 a 2.720.000 vacantes, según IBM; sin embargo, solo el 23% de los educadores dice que todos los graduados de colegios y universidades estadounidenses tendrán habilidades en ciencia de datos y análisis.
- Encontrar las herramientas analíticas correctas para recoger conocimiento desde los datos con los que se pueda actuar puede ser un desafío. Las organizaciones quieren herramientas que sean fáciles de usar, fiables y con el respaldo de expertos técnicos. Las complejas herramientas de análisis de datos que son difíciles de usar pueden dificultar que los equipos proporcionen valor.
Minitab intenta mirar a estos desafíos de frente con su último lanzamiento, Minitab 19. Jeffrey T. Slovin , Director Ejecutivo de Minitab, LLC, dijo: "Durante casi 50 años, Minitab ha ayudado a miles de organizaciones a impulsar la contención de costes, mejorar la calidad, aumentar la satisfacción del cliente y aumentar la eficacia. Con el lanzamiento de Minitab® 19, hemos creado una solución mejor, más rápida y más fácil para ayudar a los usuarios a tomar mejores decisiones basadas en los datos".
Nuevas características hacen de Minitab® 19 una herramienta estadística aún más potente
Minitab® 19 Statistical Software mejoró en las versiones anteriores con nuevas características y un mejor rendimiento. Con Minitab® 19, los usuarios pueden analizar grandes conjuntos de datos con rapidez, comparar resultados y tomar mejores decisiones basadas en los datos.
Minitab® 19 también tiene una nueva interfaz, limpia y fresca, que hace el software más fácil de usar. Con principios de diseño de aplicaciones familiares que utilizan clics, no código, y el Asistente de Minitab, una función incluída que ayuda a guiar y solucionar cualquier análisis, Minitab está diseñado tanto para principiantes como para los científicos y analistas de datos más experimentados.
Para aquellos que comienzan su viaje por el análisis, necesitan un repaso o ayudar a incorporarse a nuevos miembros del equipo, Minitab también ofrece Quality Trainer, un curso de aprendizaje electrónico que incluye lecciones animadas, pruebas y ejercicios prácticos que ayudan a enseñar estadística fácilmente y a cómo usar Minitab.
Disponible en versiones de 32 y 64 bits, con mejoras de algoritmos, importaciones más rápidas de documentos y un acceso más conveniente para automatizar el análisis de rutinas con macros, Minitab® 19 permite a los usuarios obtener resultados precisos más rápido.
El Sr. Slovin continuó: “Minitab se compromete a desarrollar las mejores herramientas y capacitación para ayudar a los clientes a detectar tendencias, resolver problemas y descubrir información valiosa sobre sus datos con una facilidad sin precedentes. Minitab® 19 fijará el estándar para el software estadístico, permitiendo a los clientes analizar conjuntos de datos aún más grandes y comparar los resultados de forma más rápida y más fácil que nunca.”
- Detalles
- Categoría: Minitab
- Visto: 8507
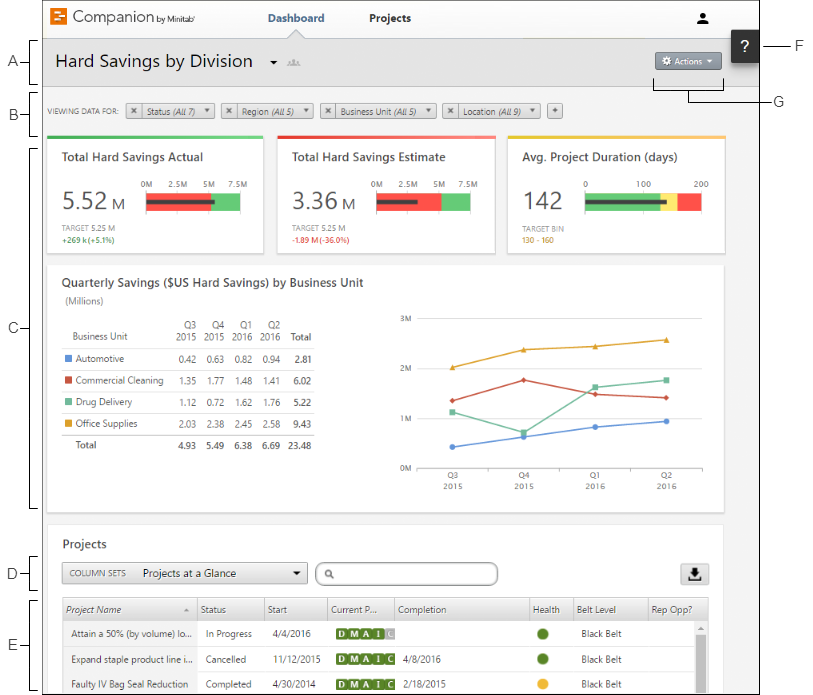
A día de hoy nos encontramos frente a un flujo constante de información, y muchas veces no sabemos cómo organizarla. ¿No le ha pasado nunca que tenemos toda la información desperdigada a lo largo y ancho del escritorio, sabiendo más o menos dónde está todo, pero sin saber exactamente dónde está nada?
El ciudadano medio de Estados Unidos gasta aproximadamente un año de su vida buscando cosas que no recuerda dónde las ha dejado
[Rovira Celma, Álex (24 de julio de 2005). El tiempo perdido. El País Semanal]
En nuestros proyectos, acumulamos un gran número de informes, correos, reuniones, archivos, lista de clientes, etc. Solamente pensar que podemos perder esta información valiosa y que tanto esfuerzo nos ha llevado obtener, nos genera un gran dolor de cabeza.
Pues bien, si tan importante es esa información, ¿Por qué la almacenamos en lugares diferentes? ¿Por qué tengo los documentos de mi proyecto en un lugar distinto a los correos electrónicos que también forman parte de mi proyecto?... Y así podríamos seguir con una larga lista de preguntas que podríamos solucionar con la misma respuesta.
Companion by Minitab
Companion by Minitab es el complemento perfecto para todos nuestros proyectos: la herramienta de gestión de proyectos y de mejora continua más potente del mercado.

Companion by Minitab está diseñado para tener el control de todo nuestro trabajo, desde hojas de ruta, diagramas de flujo y análisis de calidad, hasta un historial de correos electrónicos, y todo ello con el fin último de conseguir la Mejora Continua en todas las fases de nuestro proyecto.
¿Si tan completo es, no será demasiado complicado?
La respuesta es NO. Companion by Minitab está estructurado de manera que de un solo vistazo podamos ver los puntos importantes o nuestras prioridades, facilitando así una visión general del proyecto. Disponer de ella ella es una labor fundamental para el gestor del proyecto, quien tiene que saber exactamente en qué punto se encuentra el proyecto para dirigirlo de la manera más eficiente posible.
En Companion by Minitab, como toda la información está estructurada de la forma que necesitamos, se hace más simple la detección de los problemas para así tomar las acciones necesarias para corregirlos.
Cuando llevamos a cabo un proyecto necesitamos tener un plan, es un elemento fundamental, y no sólo se encuentra en la fase inicial del proyecto. En Companion by Minitab podemos establecer los plazos de ejecución y podemos permitir que todas las personas pertenecientes al proyecto estén informadas.
Cuando tienes un sueño, y le pones fecha lo conviertes en objetivo.
Cuando trazas un plan lo conviertes en meta.

Los costes, esa palabra de la que quiere hablar primero todo el mundo antes de nada. Hay que contabilizar todos los gastos. Tener una previsión de gastos imputables, ya sea en inversiones en infraestructuras, logística, imprevistos, etc., es fundamental. Si son obviados y a eso le sumamos una mala gestión, podemos encontrarnos ante un proyecto inviable. Si sabemos de dónde partimos y a dónde vamos, lo más seguro es que en ningún momento se dispare el coste total. Este control de contabilidad lo podemos llevar a cabo con las herramientas financieras que ofrece Companion by Minitab.
La buena gestión económica se basa en: Debe, Haber y Saldo
- Detalles
- Categoría: Signals Notebook
- Visto: 8694
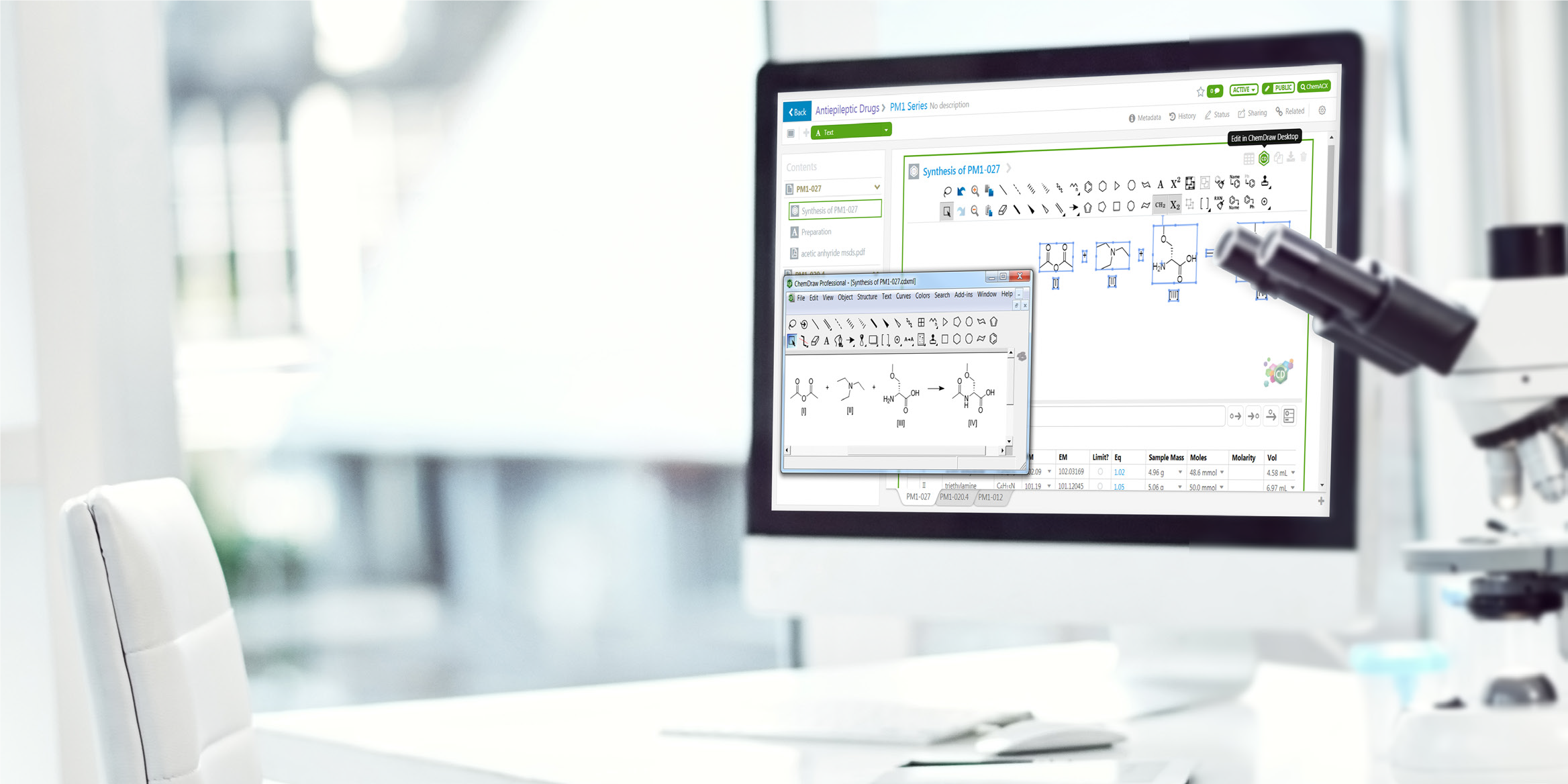
Utilizar un editor de estructuras químicas en una aplicación de navegador web no es algo nuevo. Desde 1995, en la infancia de la World Wide Web, ChemFinder.com, el primer motor de búsqueda con capacidad química, introdujo el complemento ChemDraw Netscape Navigator, que permitió a los usuarios encontrar información química en la web. Sergei y Larry todavía estaban en su dormitorio de Stanford pirateando el primer motor de búsqueda de Google.
Desde el principio, el complemento ChemDraw permitió a los usuarios dibujar directamente estructuras químicas dentro del navegador utilizando la barra de herramientas y los métodos abreviados de teclado del programa. Mientras tanto, las aplicaciones web contemporáneas tenían que basarse en el uso de editores químicos externos para copiar cadenas SMILES y archivos mol en un cuadro de texto en la página web. El Complemento ChemDraw de Netscape, y su gemelo, el control ActiveX ChemDraw para Internet Explorer, marcó el comienzo de una nueva generación de aplicaciones químicas de la empresa que incluye: registro de productos químicos, adquisición, gestión de inventario y, en última instancia, el primer sistema de cuaderno electrónico de química ampliamente adoptado. Si bien la capacidad de dibujar estructuras directamente en el navegador fue fundamental para su adopción generalizada, aún más importante fue el hecho de que el editor acoplado se comportó exactamente igual que la aplicación de escritorio independiente ChemDraw.
Sin embargo, la capacidad de replicar el comportamiento del escritorio de ChemDraw dentro de un navegador tuvo un coste. Los complementos a menudo requerían procedimientos de instalación engorrosos y poco confiables. Dependiendo de la marca y versión específicas del navegador, diferentes componentes de software de Java, ActiveX u otros del lado del cliente tenían que estar preinstalados en el ordenador del usuario final. Además, algunos de estos procedimientos de instalación requerían privilegios de administrador del sistema, lo que tuvo un gran impacto en la capacidad de uso de los sitios web de los hosts y los sistemas de información química.
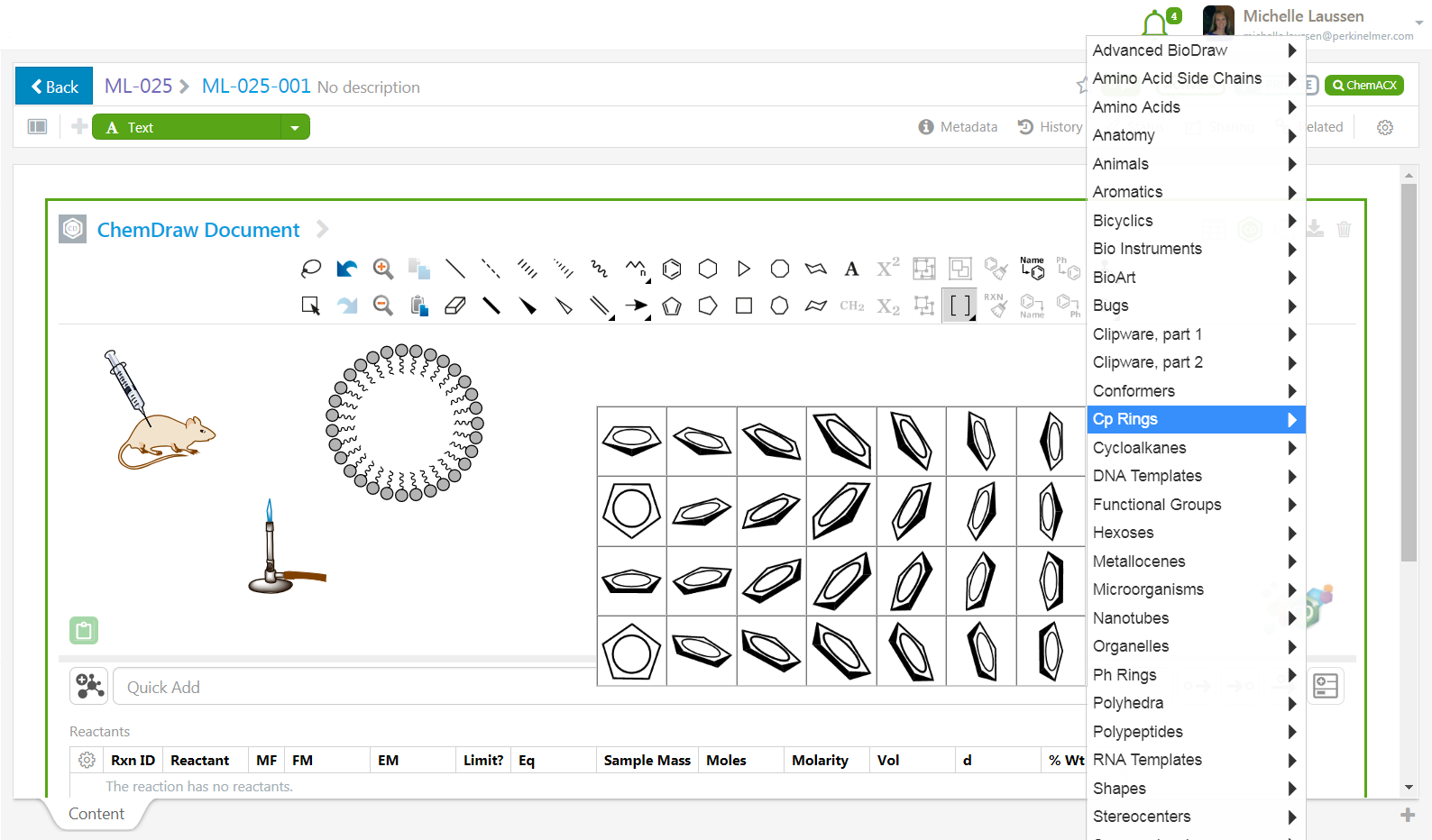
Algunas herramientas de este tipo de plataformas de dibujo son demasiado complicadas de implementar y usar dentro de un editor implementado en un servidor web. Estas son características que requieren herramientas auxiliares, como las de dibujo de biopolímeros, creación de monómeros vía editor HELM o la creación de placas de TLC. Sin embargo, Signals Notebook proporciona una perfecta integración con ChemDraw Desktop. En un solo clic los contenidos almacenados en cualquier apartado químico se abrirán en la aplicación de escritorio de ChemDraw, lo que le permitirá utilizar todas las funciones. Una vez editado, los contenidos se guardarán directamente en Signals Notebook.
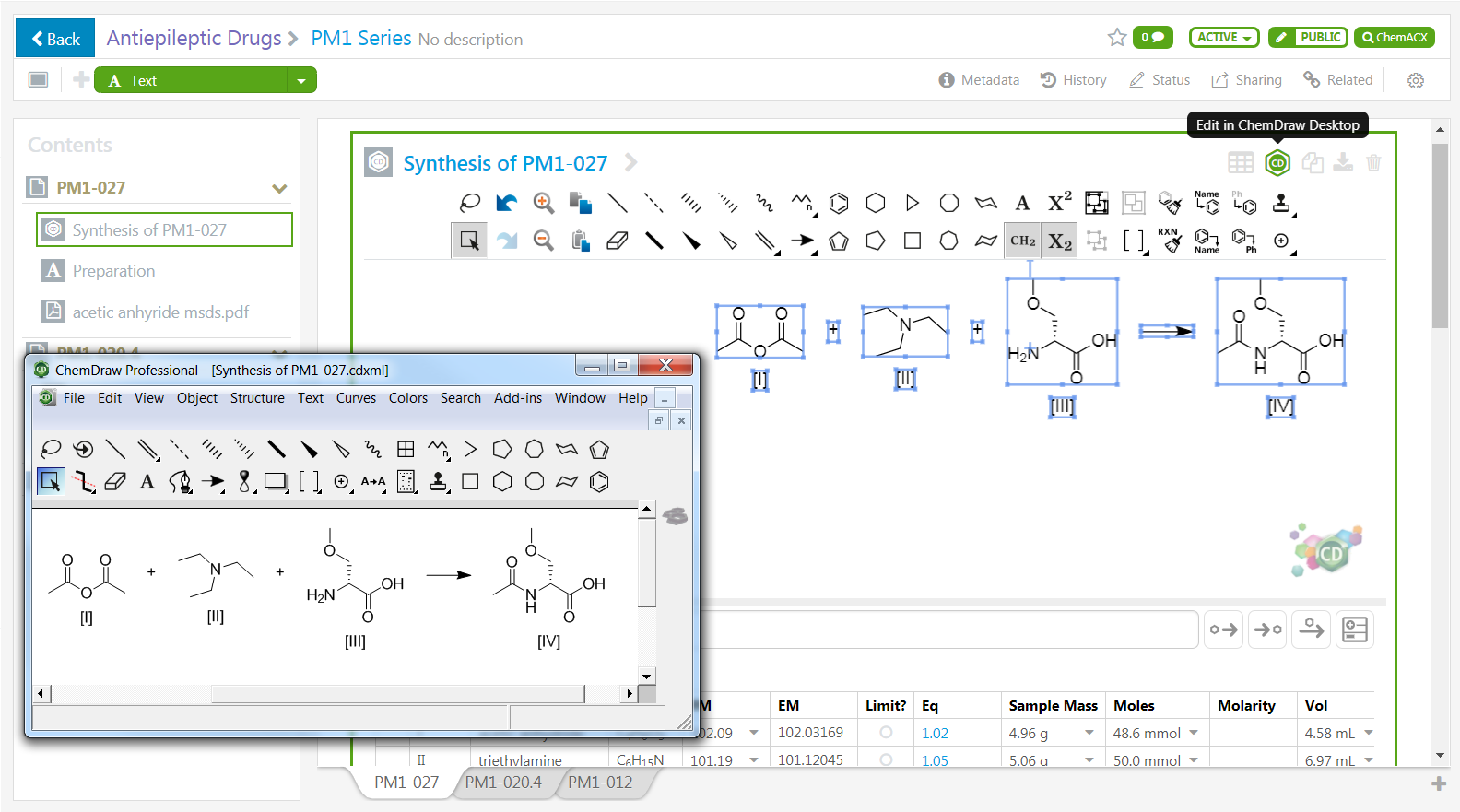
Implementación de ChemDraw JS en Signals Notebook
Signals Notebook proporciona opciones para llevar a cabo estudios de estequiometría. Tales como reactivos, catalizadores, productos, etc, que se pueden dibujar utilizando estos apartados de dibujo químico (con las herramientas de ChemDraw). Las tablas de reactivos y productos se actualizarán dinámicamente con valores de ID generados automáticamente (nombre químico, fórmula molecular, masa exacta, etc). El trabajo pesado que supone analizar los componentes de una reacción y calcular las propiedades químicas podrá ser delegado a ChemDraw. Existe, además, la posibilidad de utilizar ChemACX para buscar entre más de 20 millones de sustancias disponibles, obteniendo sus estructuras químicas, propiedades e, incluso, hojas de seguridad de materiales.
En resumen, los usuarios de Signals Notebook y ChemDraw tienen plena capacidad de dibujo químico, pudiendo además acceder de manera eficiente a estructuras químicas y datos de fuentes externas.
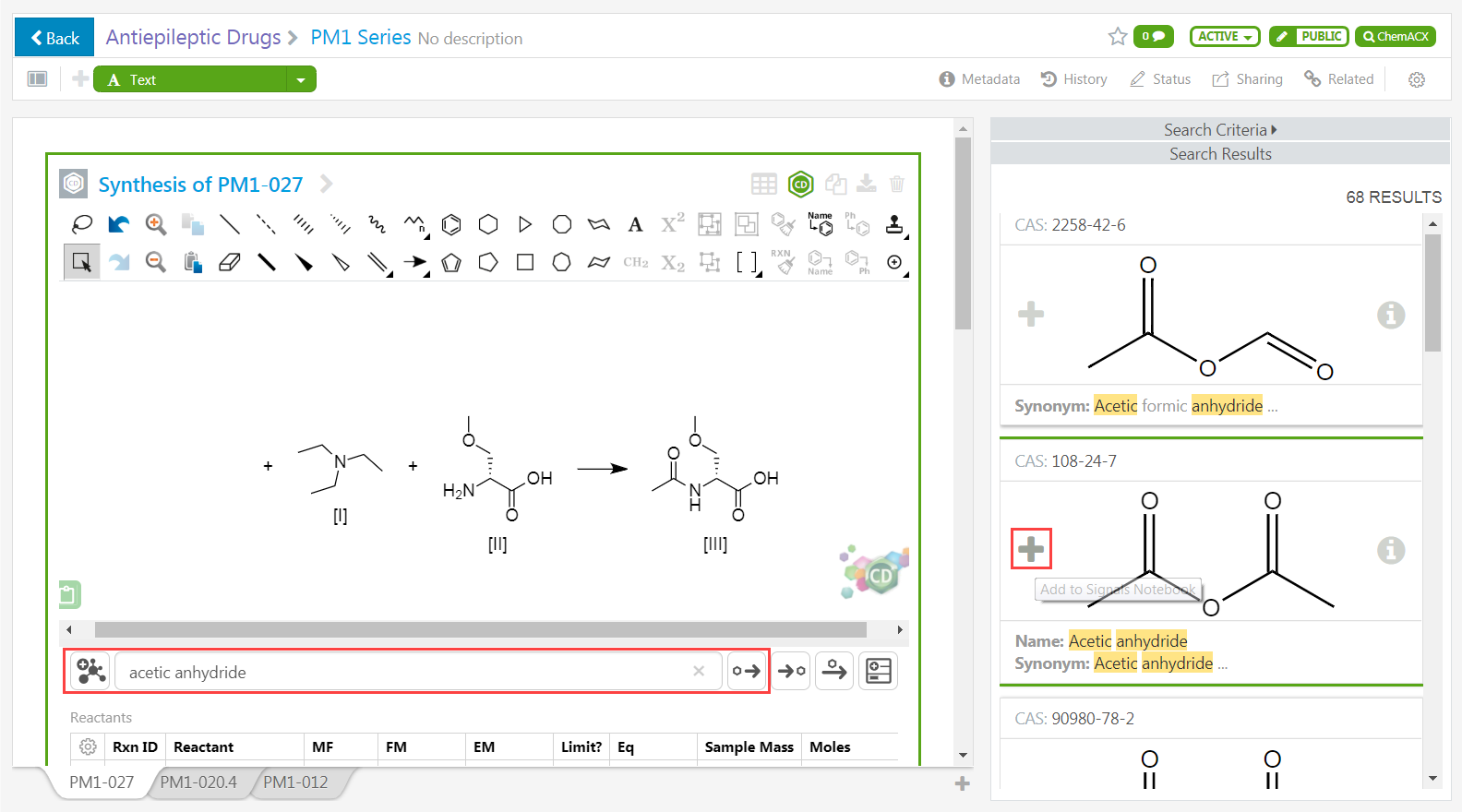
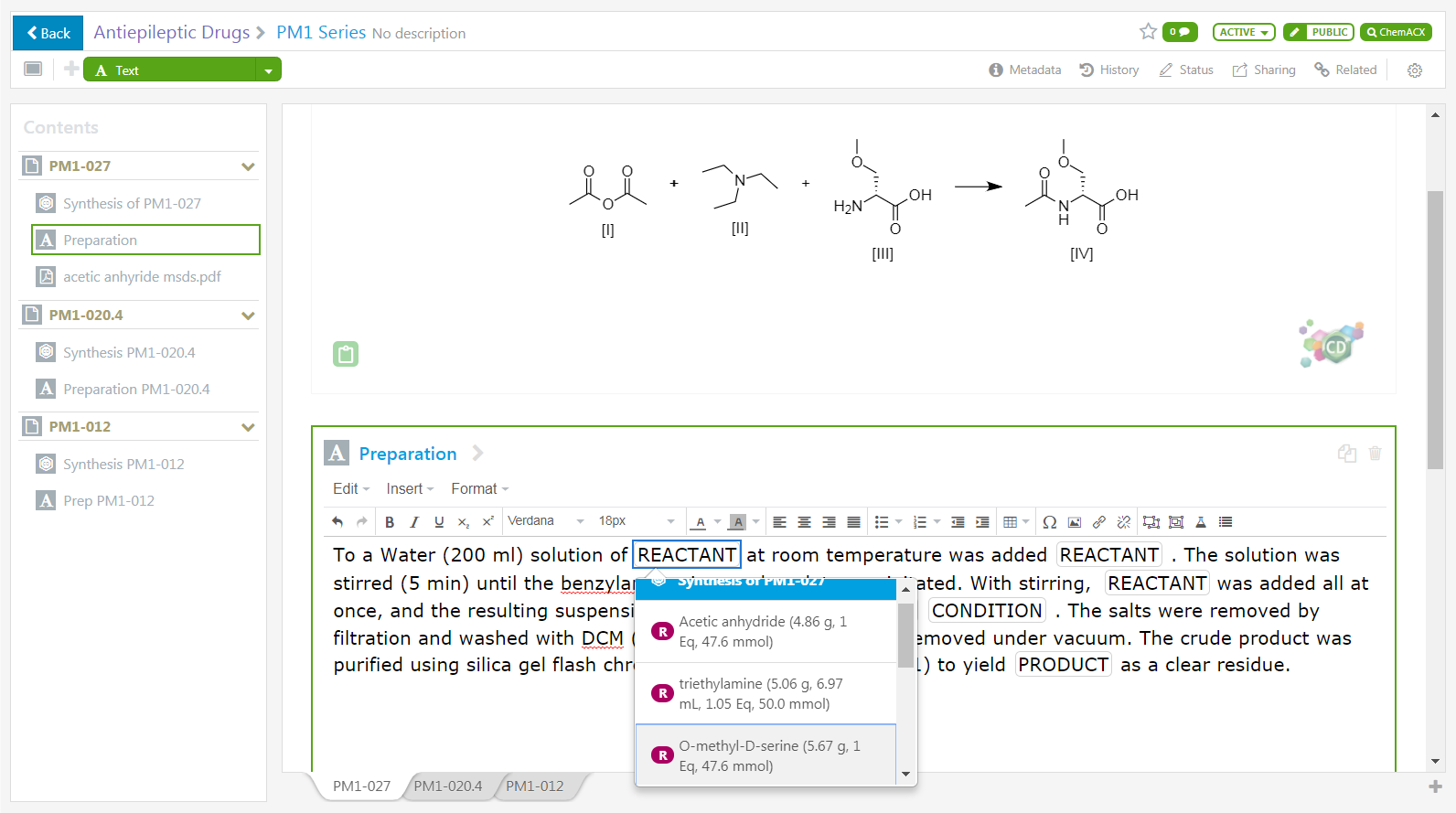
¿Le quedan dudas?
Después de más de 30 años de evolución, ChemDraw JS sigue siendo el editor químico basado en la web más avanzado, programable y rico en funciones. Es un una herramienta esencial para equipos que desarrollen aplicaciones web intranet o comerciales que requieran inteligencia química. Proporciona las caraterísticas de la aplicación de escritorio, todo en una aplicación que no requiere ningún tipo de instalación. ChemDraw JS se encuentra implementado en el cuaderno de laboratorio electrónico Signals Notebook.
- Detalles
- Categoría: Minitab
- Visto: 8568

Por Bruno Scibilia
La forma en que se describe el sabor del vino a menudo se lee como un poema: “con cuerpo y rico pero no pesado, con alto contenido de alcohol, pero ni ácido ni tánico, con un sabor sustancial a cereza negra a pesar de su delicadeza ...” Las flores y las frutas son comúnmente utilizadas como descriptores, destinadas a ayudar a los bebedores a comprender los sabores en una copa de vino. Esta poesía refleja que algunos consideran que la conversión de la fruta en vino es una forma de arte.
Sin embargo, todo el sabor se reduce a compuestos químicos que afectan el sabor de su vino. Detrás de las descripciones amorosas del vino como arte viviente, hay ciencia. Y la regresión estadística puede ayudar.
¿Qué da sabor a un vino?
Por supuesto, el vino comparte muchos de los compuestos químicos naturales que se encuentran en las frutas y las especias, por lo que es comprensible usarlos como descriptores. Los compuestos químicos específicos informarán constantemente a nuestra experiencia de degustación de lo que es dulce, agrio o amargo, por ejemplo.
Luego están los elementos esenciales de un buen vino, para los cuales no hay sustitutos: buenas uvas de buena calidad, prácticas diligentes de elaboración del vino y crianza en barrica. Cada una de las fases de vinificación tendrá un impacto diferente en el sabor.
Los cambios de sabor se producen debido a la presencia de diferentes productos químicos en el vino debido a las ocurrencias en estas etapas del proceso. Todos los sabores del vino provienen de las uvas y del proceso de vinificación, por supuesto, pero la manipulación de estas fases puede dar como resultado un vino que tenga un mejor sabor.
La degustación de vinos puede sonar etérea, pero el sabor se trata de compuestos químicos que afectan al sabor de su vino. Detrás de las descripciones amorosas del vino como arte viviente, hay ciencia. Los ácidos principalmente agregan notas agrias. Los compuestos de alcohol también afectan al sabor. El etanol agrega sabores amargos, dulces y agrios, etc. Si uno quiere poder usar el conocimiento del impacto de ciertos compuestos en el sabor, debe comprender qué fase producirá ese compuesto de forma natural.
Distinguir un buen vino de un mal vino
Es inevitable que los gustos de los vinos varíen de persona a persona y que haya muchos perfiles diferentes de catadores de vinos (De Gustibus non est disputandum: "En cuestiones de gusto, no puede haber disputas"), sin embargo, sabemos que algunos vinos son obviamente mejores que otros, y la mayoría de las personas probablemente reconocerían un buen vino de uno malo.
Cuando se necesita entender situaciones como ésta en las que la variabilidad y el ruido juegan un papel importante, los modelos estadísticos son muy eficientes para identificar las entradas clave de datos en apariencia completamente caóticos.
Este artículo detalla cómo los datos de cata de vinos y las potentes técnicas de modelado permiten conocer las variables que son importantes para un tribunal de catadores de vinos con experiencia.
El análisis ilustra que incluso las preferencias de sabor pueden evaluarse con estadísticas si se elige el análisis correcto.
Estamos interesados en utilizar estadísticas para comprender si un vino que tiene, por ejemplo, más sulfatos o más cloruros tendría mejor sabor. Con ese entendimiento, podría ser posible hacer un mejor vino. Consideraremos muchos predictores potenciales, como la acidez, el dióxido de azufre y el porcentaje de alcohol.
La prueba de sabor
Un jurado de enólogos probó varios tipos de vinos blancos y tintos y proporcionó evaluaciones binarias de calidad (buena (1) o mala (0)) para cada uno. Nuestro objetivo es identificar cuáles de estas muchas variables tienen un efecto significativo en la calidad del vino.
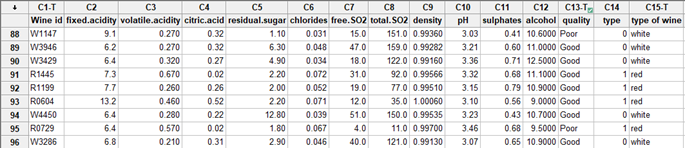
Uso de la regresión para analizar datos del gusto binario
Los gráficos simples no son suficientes para identificar qué variables podrían ser importantes debido a la complejidad y la variabilidad en este conjunto de datos. El análisis de regresión nos permite ver cómo múltiples factores afectan a un resultado, por lo que es un método ideal para observar las variables de cata de vinos.
Sin embargo, nuestro jurado simplemente clasificó cada vino como de alta o baja calidad. Esto significa que tenemos datos de respuesta binarios y no continuos, por lo que debemos proceder con cautela: el uso de una regresión estándar o ANOVA para analizar una respuesta binaria generalmente no es una buena idea.
Debido a que los datos binarios siguen una distribución binomial en lugar de una distribución normal en forma de campana, la regresión estándar puede dar como resultado predicciones de probabilidad negativas o mayores al 100%. Podríamos obtener un modelo innecesariamente complejo, en el que algunas interacciones espúreas parecen ser significativas. Además, la varianza para los datos binarios no es constante.
Afortunadamente, hay una solución simple, ya que tenemos datos de respuesta binarios, simplemente necesitamos usar la herramienta adecuada para esto: regresión logística binaria.
Análisis de regresión de modelo completo
Una práctica estándar en el análisis de regresión es comenzar con el "modelo completo", uno que incluya todos los factores potencialmente significativos para los cuales se recopilaron los datos. En este caso, comenzamos el análisis incluyendo todas las variables y todas las interacciones entre esas variables y los tipos de vino.
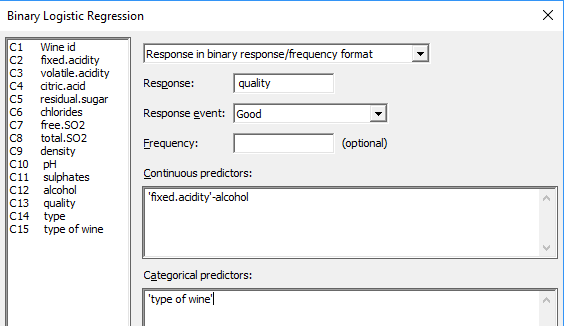
Para incluir interacciones, en Minitab vaya a Estadísticas> Regresión> Regresión logística binaria> Ajustar modelo logístico binario> Modelo> Agregar interacciones.
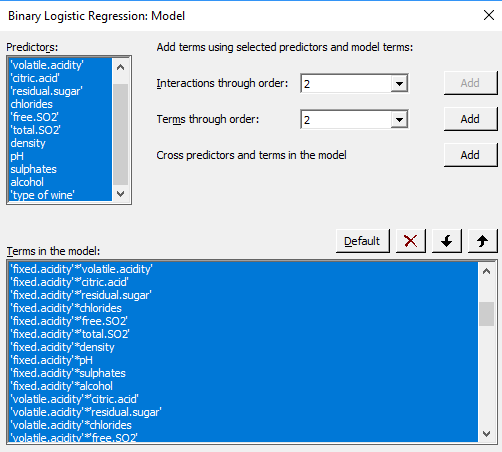
Al introducir interacciones, también es útil estandarizar los predictores continuos en su modelo para evitar efectos de escala perturbadores (Estadísticas > Regresión > Regresión > Ajustar modelo de regresión > Codificación)
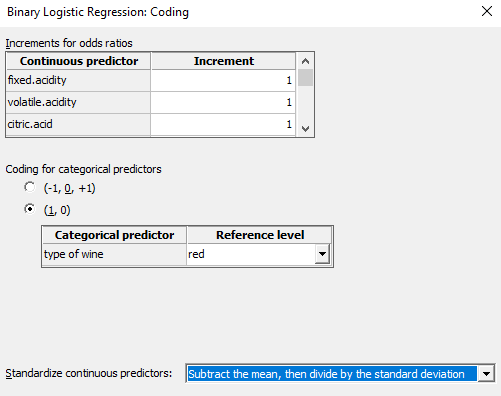
Utilizamos el método paso a paso para construir automáticamente el mejor modelo paso a paso e identificar un subconjunto útil de los términos de un gran número de términos candidatos. Para eso vaya a: Estadística> Regresión> Regresión logística binaria> Ajustar modelo logístico binario> Paso a paso
El criterio que se usó para identificar el mejor modelo basado en este enfoque por pasos fue el Criterio de Información de Akaike (AIC). AIC estima la cantidad relativa de información perdida por un modelo dado, esta estadística se usa para comparar diferentes modelos. Cuanto más pequeño es el AIC, mejor se ajusta el modelo a los datos. AIC incluye una penalización que aumenta con el número de parámetros estimados para desalentar el exceso de ajuste. El objetivo es evitar el sobreajuste pero también el desajuste.
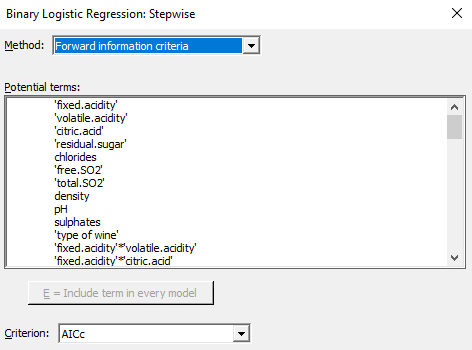
En última instancia, este proceso iterativo nos lleva al siguiente modelo.
Los factores que contribuyen al buen vino.
Con 12 términos, este modelo puede parecer difícil de entender y explicar, pero nos da una pista de cómo podemos profundizar en estos datos para comprender mejor qué factores contribuyen más al buen sabor del vino.
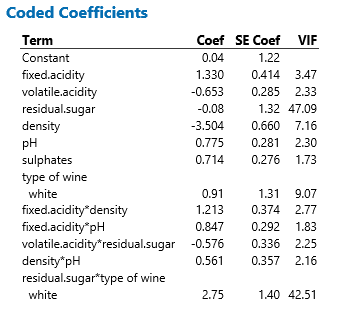
Los coeficientes codificados (estandarizados) son útiles para comprender qué variables son las más importantes:
La densidad tiene el efecto más grande (-3.504), luego el azúcar residual junto con los tipos de vinos (2.75 para la interacción con los tipos de azúcar residual) tiene el segundo efecto más grande, luego viene la acidez fija (1.33) y la interacción acidez fija * la densidad (1.213)
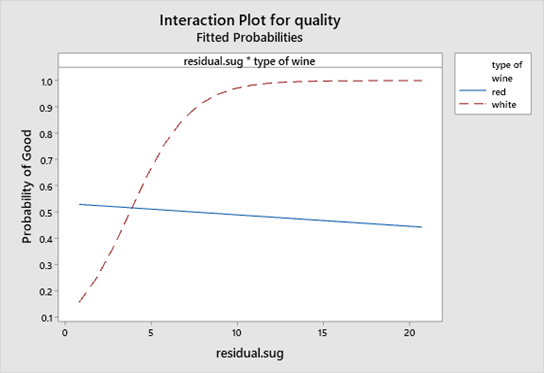
El diagrama de interacción anterior muestra que el efecto del azúcar residual en la calidad del vino es prácticamente inexistente en los vinos tintos, sin embargo, desempeña un papel importante en los vinos blancos.
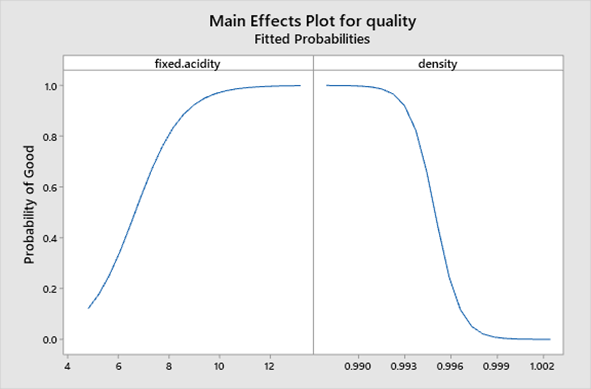
Ahora que tenemos modelos para los vinos, podemos ver qué nos dicen los datos sobre las características del vino que influyeron en las clasificaciones de nuestro jurado. Por ejemplo, esta gráfica de efectos principales resume la relación entre acidez fija, densidad y la probabilidad de hacer un buen vino. Una mayor acidez fija y una menor densidad tienden a mejorar la calidad del vino.
Conclusión
Entonces, cuando se necesita comprender las situaciones que, al menos en la superficie, desafían el análisis de datos o cuando el número de variables candidatas es grande, ¿por qué no profundizar un poco más usando técnicas como la regresión logística binaria?
Puede utilizarse un enfoque similar a lo que hicimos con estos datos de cata de vinos para analizar los datos de marketing o ventas, para comprender mejor las preferencias de los clientes y obtener información sobre los factores que son importantes, incluso si, como las preferencias de sabor, parecen difíciles de entender o medir.
Como conclusión, hemos podido identificar el mejor modelo gracias a una nueva característica de Minitab 19: el enfoque paso a paso basado en los Criterios de información de Akaike (AIC).
- Detalles
- Categoría: Comsol
- Visto: 5495
La actualización COMSOL Multiphysics® versión 5.4 update 4 ya está disponible para su descarga. Esta actualización incorpora mejoras de rendimiento y estabilidad.
La manera más fácil de instalar la actualización es arrancar el progama y seleccionar Check for Product Updates (Buscar actualizaciones del producto). Si utiliza la versión del sistema operativo Windows®, ésta se localiza bajo el menú Archivo > Ayuda. Si utiliza Linux® o macOS, la encontrará en el menú de Ayuda. La actualización aplica únicamente a la versión 5.4.
Si no se ha descargado todavía la versión 5.4, visite el enlace inferior, donde están todas las actualizaciones incluídas.- Detalles
- Categoría: Minitab
- Visto: 6277

Mejor toma de decisiones. Funcionamiento más rápido. Más fácil que nunca.
Minitab 19 ofrece análisis estadístico, visualizaciones, análisis predictivo y análisis de mejora para permitir la toma de decisiones basadas en datos. Independientemente de sus conocimientos estadísticos, Minitab puede ayudar a una organización a predecir mejores resultados, diseñar mejores productos y mejorar el futuro a través de su software fácil de usar o su red de soporte técnico conformada por expertos en estadística.
Analice conjuntos de datos grandes y pequeños con la interfaz simplificada y nuevas características efectivas.
Administre y organice sus proyectos con la flexibilidad que usted necesita: la nueva característica de navegador le permite agrupar los resultados/análisis por hoja de trabajo y ordenarlos alfabéticamente o ejecutarlos en un orden específico.
La nueva característica de vista dividida le permite comparar fácilmente múltiples análisis lado a lado.
Nuevas funciones estadísticas para diseño de experimentos (DOE) y mejoras en la regresión escalonada y el análisis de capacidad normal para facilitar un análisis de datos más exhaustivo.
- Detalles
- Categoría: BIOVIA
- Visto: 6481
Desafío: Reducción de la productividad como resultado del intercambio de datos ineficientes con CROs
Solución: Un cuaderno de nube flexible y fácil de usar
Esta compañía compró el Biovia Notebook para uso de cuatro CRO que trabajan en el área de la síntesis química. El equipo de servicios de Biovia agregó una herramienta especializada (BIOVIA Alliance Manager) que permite a los científicos de la empresa patrocinadora ver los datos de CRO instantáneamente cuando sea necesario. Además, los datos de síntesis química de CRO se transfieren automáticamente al ELN interno de la compañía (BIOVIA Workbook) en el intercambio de datos programado que se realiza por la noche. El sistema altamente personalizado permite a los científicos de la compañía ver datos internos y de CRO sincronizados en un solo lugar. BIOVIA Notebook se puede implementar en un entorno de nube con certificación ISO 27001, y es un ELN fácil de usar que se centra en la captura de IP y el intercambio de información, la documentación del experimento y el menor costo total de propiedad. La interfaz de usuario intuitiva del cuaderno electrónico facilita la planificación, ejecución, captura, búsqueda e intercambio de trabajos científicos de manera conveniente y coherente. Las plantillas de flujo de trabajo configurables mejoran el rendimiento y el mantenimiento de registros . Los científicos pueden agregar fácilmente texto, imágenes, estructuras químicas, datos analíticos y más información desde sus aplicaciones de software favoritas. La capacidad de clonar rápidamente experimentos previos proporciona acceso instantáneo a métodos, protocolos y hojas de datos de resultados de uso frecuente. Las firmas electrónicas y las alertas de flujo de trabajo aseguran que los experimentos se firmen y finalicen de manera eficiente. Los científicos también se benefician de las potentes capacidades de creación que permiten el análisis rápido de datos, la visualización y los informes en el cuaderno.
Resultados: Documentación centralizada de los resultados de investigación, tanto internos como externos