- Detalles
- Categoría: ChemOffice
- Visto: 7605
Para llevar a cabo la selección de un fármaco objetivo será necesario tener en cuenta varios factores determinantes: el diluvio de datos, la activación del receptor, la complejidad que puedan presentar las proteínas terapéuticas, etc.
El gran número de datos de detección que deben procesarse para la elección de un candidato es bien conocido por la industria. Tomar buenas decisiones requiere software para gestionar eficazmente el tamaño el tamaño y la complejidad del conjunto de datos multiparamétricos. Los científicos, además, tienen la tarea de encontrar formas de detectar posibles problemas con moléculas prometedoras lo antes posible.
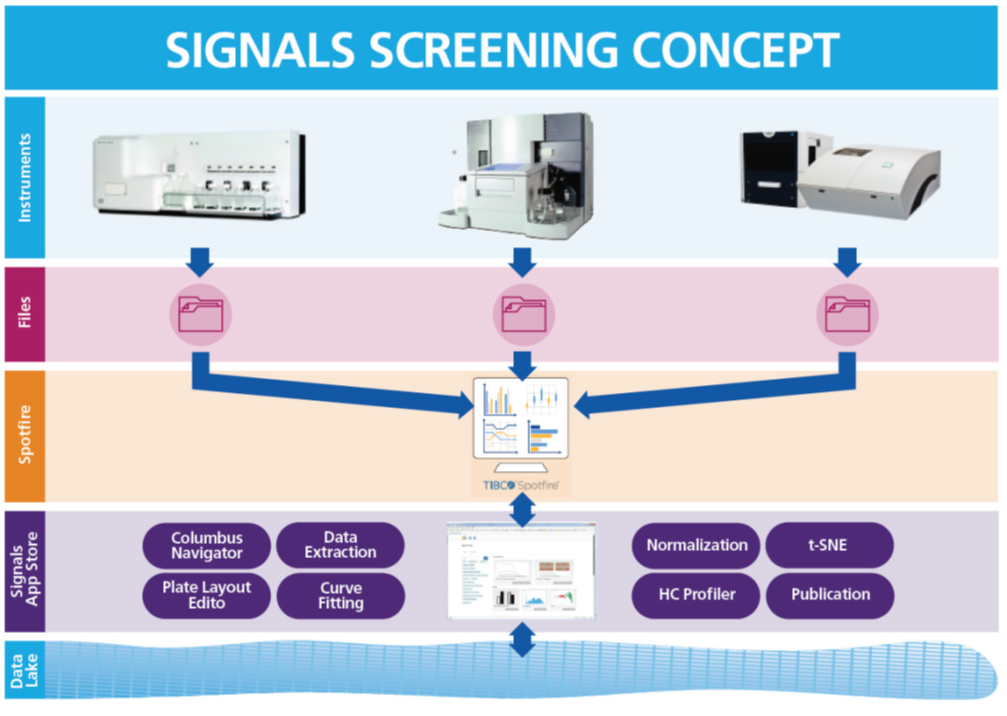
Datos de detección de alto rendimiento
El enfoque más conocido y de mayor duración para acelerar el descubrimiento de fármacos es el cribado de alto rendimiento (HTS), que realiza ensayos en placas de microtitulación de múltiples pocillos de alta densidad con datos procedentes de lectores de microplacas. El objetivo: la producción de grandes cantidades de datos en archivos planos. Los compuestos prometedores, un pequeño número dentro de la cantidad total, se prueban luego para determinar si son dignos del tiempo y el gasto de una evaluación adicional. Este proceso puede generar cuellos de botella en el flujo de trabajo, porque el nivel de detalle requerido para el análisis es inmenso.
Datos de detección de alto contenido
A diferencia de HTS, los datos de detección de alto contenido (HCS) se generan mediante varios microscopios fluorescentes o confocales de alta resolución en lugar de lectores de placa. Si bien el rendimiento general en HCS no es tan bueno como HTS, la información sobre el impacto del compuesto candidato puede conducir a una mejor comprensión de su efecto en las células. Sin embargo, esto tiene un costo en términos de gestión y análisis de datos.
Resonancia de plasmones superficiales
La resonancia de plasmón superficial (SPR) ofrece beneficios sustanciales para las mediciones de unión en estudios bioquímicos y farmacológicos. Las mediciones son sensibles y requieren pequeñas cantidades de reactivos. SPR se diferencia por su capacidad de generar datos de enlace de equilibrio y mediciones de la cinética de las interacciones. Además, con la creciente importancia de las macromoléculas como agentes terapéuticos, particularmente los anticuerpos monoclonales (mAbs), a veces también se desea la caracterización de los epítopos de la unión de mAb al objetivo.
SPR se ha convertido en el estándar de oro para obtener estas medidas. SPR tiene ventajas adicionales sobre otras técnicas. Por ejemplo, SPR no requiere una etiqueta para la detección (las etiquetas moleculares pueden afectar la unión del compuesto al objetivo), y SPR requiere muy poco material objetivo (que puede ser costoso de generar / purificar con moléculas de proteínas). El costo de estas ventajas es que el rendimiento realmente alto, es decir, a los niveles vistos en HTS e incluso HCS no es posible.
Datos más grandes. Mejor flujo de trabajo
Aplicando las metodologías citadas anteriormente, los científicos esperan analizar más muestras en menos tiempo, con menos trabajo, y al mismo tiempo detectar problemas con compuestos prometedores al principio del proceso de descubrimiento.
La compañía ha desarrollado aplicaciones integradas dentro de la potente plataforma de análisis de datos TIBCO Spotfire® que admite los volúmenes de datos que los clientes requieren. Signals Screening es un motor de procesamiento de datos flexible e intuitivo integrado a la perfección en la interfaz familiar TIBCO Spotfire®. Está diseñado para aliviar las restricciones en los flujos de trabajo de análisis de datos en toda la industria biofarmacéutica, acelerando el descubrimiento de fármacos.
Los investigadores no necesitan aprender múltiples paquetes de software para importar y procesar datos de instrumentos. Las tablas de datos subyacentes dentro de TIBCO Spotfire® ayudan a aumentar la integridad de los datos al eliminar la necesidad de cortar y pegar entre programas externos como Excel. TIBCO Spotfire® proporciona análisis estadísticos avanzados, como algoritmos de procesamiento de datos multiparamétricos, que no se proporcionan comúnmente, lo que aumenta el poder de procesamiento de datos disponible para los científicos de descubrimiento de fármacos, ofreciendo una visión más profunda de los datos.
Entradas |
Capacidades de análisis |
Salidas |
|
HTS |
Soporte generalizado de archivos de instrumentos de cualquier archivo de texto y todos los lectores de placas estándar |
Normalización 3PL, 4PL y ajuste de curva lineal Estadísticas de ajuste de curvas Fix asíntotas Eliminar valores atípicos y volver a colocar Reducción de dimensionalidad no lineal: t-SNE |
EC50, IC50, POC R2, coeficiente de Hill, Stdev, Publicar en Signals Lead Discovery Exportar a .ppt, .pdf, .csv, etc. |
HCS |
Sin instrumentos, exportar resultados de instrumentos HCS comunes: Opera Phenix, Operetta CLS, CellnSight, etc. Importación directa de resultados de análisis de imágenes de Columbus desde TIBCO Spotfire®. Plantillas de importación reutilizables y fáciles de definir para traer datos de otro análisis de herramientas de imagen como CellProfiler ™, ImageJ / Fiji, Definiens y todos los demás resultados basados en texto |
Flujo de trabajo automatizado Variedad de opciones de control de calidad Excluir puntos de datos y volver a analizar Normalización Ajuste de curvas Análisis de componentes principales (PCA) Aprendizaje automático no supervisado Análisis unicelular Selección de características Clasificación
|
Selección de golpe Subpoblaciones basadas en similitud fenotípica Puntaje de positividad EC50, IC50, R2 Gráfico de caja y gráfico de densidad para estadísticas de celda única Mapas de calor de placas Exportar a .ppt, .pdf, .csv, etc. |
SPR |
Biacore T200 raw data Biacore 4000 partially ForteBio OctetRED IBIS MX96 |
Alineación Referencia Blanking Interacción 1: 1 con transferencia masiva global análisis de ajuste Análisis de estado estacionario MW Normalización |
ka, kd, KD, Rmax, Kt, x2, stdev Sensorgramas con superposición de ajuste de curva; derechos residuales de autor Diagrama de afinidad iso Selección de golpe Exportar .ppt, .pdf, .csv, etc |
Conclusión
En el pasado, el descubrimiento de drogas involucraba compromisos que causaban cuellos de botella, ineficiencias, pérdida de tiempo y dinero. Entre estos, durante muchos años, las soluciones de detección se encerraron en un enfoque de "caja cerrada" para el procesamiento de datos. Los científicos tuvieron que recurrir a herramientas a medida, estrechamente acopladas a la instrumentación de detección, y con flexibilidad limitada. Signals Screening es un motor de flujo de trabajo de detección intuitivo, configurable y flexible, además de las incomparables capacidades de visualización y análisis de datos de TIBCO Spotfire®. La detección de señales actualmente aborda tres tipos de ensayos:
1. Detección de alto rendimiento
2. Cribado de alto contenido
3. Resonancia de plasmón superficial
- Detalles
- Categoría: BIOVIA
- Visto: 5902
El conjunto de aplicaciones alojadas y seguras de ScienceCloud admite una amplia gama de flujos de trabajo científicos:
Gestión segura de datos colaborativos estructurados y no estructurados.
Sciencecloud Projects es una aplicación para capturar, organizar, buscar y analizar toda la información científica generada durante los programas de investigación internos y externos. ScienceCloud Projects incluye las siguientes capacidades:
Datos del proyecto
Un sistema colaborativo para almacenar y rastrear datos científicos estructurados:
- Sistema de registro de productos químicos flexible y completo
- Cálculo automático de propiedades fisicoquímicas.
- Seguimiento de información logística para compuestos
- Diccionario biológico para garantizar la calidad y estandarización de los datos.
- Carga y control de calidad de los resultados del ensayo.
- Capacidades interactivas de SAR
- Seguimiento de trazas analíticas (espectros de RMN, protocolos de ensayo, curvas IC50)
- Combina búsquedas químicas y búsquedas biológicas.
- Dibujante de química de huella cero para registro o búsqueda.
- Informes flexibles (por ejemplo, PDF, SDF o Excel)
- Alertas para informar a los miembros del proyecto sobre la información disponible recientemente.
- Pipeline Pilot collection API para carga automatizada y servicios personalizados (por ejemplo, reglas comerciales).
Documentos del proyecto
Un sistema colaborativo para almacenar y rastrear documentos ('datos no estructurados'):
- Notificaciones automatizadas para cargar y editar documentos
- Búsqueda rápida basada en palabras clave y química
- Pipeline Pilot Collection API para la carga y descarga automática de documentos.
Proyecto de colaboración
Para resolver el desafío de comunicación inherente al modelo de I+D en red, ScienceCloud utiliza un marco social que mantiene a todos en contacto, informados rápidamente del progreso realizado dentro del proyecto y permite interactuar con sus socios con un clic en su navegador web o con un toque en tu dispositivo móvil. Cada miembro puede anotar fácilmente cualquier información para agregarle contexto y contenido no estructurado.
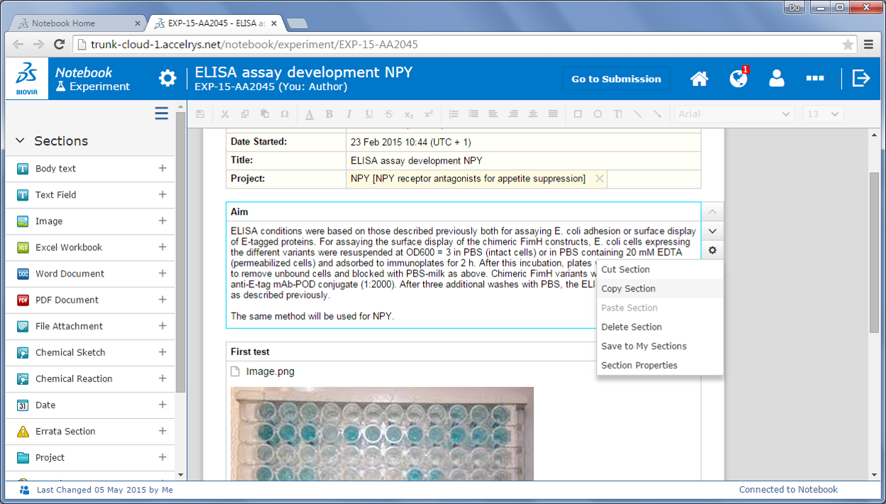
Documente su trabajo científico con el cuaderno de laboratorio electrónico de BIOVIA
ScienceCloud incluye una capacidad portátil flexible y multidisciplinaria que le permite capturar, acceder y compartir información experimental. Para hacer esto de manera efectiva en proyectos externalizados, debe registrar experimentos y almacenarlos en un lugar seguro y de búsqueda que esté integrado con otros recursos del proyecto. Tanto los experimentos como los datos del proyecto ahora se pueden buscar juntos, y un equipo del proyecto puede tener una sola conversación con referencias a cualquiera de estas fuentes de datos, ya que todos sus datos viven en ScienceCloud.
ScienceCloud Experiments proporciona todo lo que necesita para ejecutar sus registros de experimentos y, al mismo tiempo, lograr una colaboración fácil dentro y entre laboratorios y equipos, cuando y donde sea.
- Sistema ELN fácil de usar con entrenamiento mínimo necesario
- Comparta resultados instantáneamente con sus colegas y colaboradores.
- Grabe experimentos de forma más rápida y conveniente con un editor de experimentos flexible
- Apropiado para científicos de todas las disciplinas.
- Los flujos de trabajo de firmas electrónicas incorporados le brindan la máxima protección de IP y cumplimiento normativo
- Con licencia como cualquiera de las otras aplicaciones de ScienceCloud
- Configuración del sistema de acuerdo con sus propios requisitos.
- Utilice plantillas de experimentos para garantizar una buena calidad de documentación y un registro preciso de toda la información crítica.
ScienceCloud Experiments se integra directamente con el portal social ScienceCloud para notificaciones y comentarios.
Seguimiento e informes químicos precisos y eficientes en cualquier momento y en cualquier lugar
ScienceCloud Inventory utiliza nuestras mejores prácticas de la solución CISPro Cloud, lo que le permite mantener una lista de todos los productos químicos en sus instalaciones, realizar un seguimiento de dónde están en cantidad en tiempo real y controlar el uso. Los informes son fáciles de generar, lo que permite que los productos químicos se enumeren por ubicación, proveedor, nombre, número CAS, fórmula, etc. La utilización de CISPro a través de la nube le permite mantener su inventario de productos químicos actualizado y sus costos bajos.

Para las compañías multinacionales y multisitio, la colaboración con colegas en laboratorios de investigación y sitios de negocios puede permitir el intercambio eficiente de materiales y suministros, asegurando así que los productos químicos se utilicen antes del vencimiento y que la investigación no esté inactiva por falta de materiales que la organización ya posee en un ubicación diferente El acceso a los datos de inventario a través de la nube mejora la productividad del laboratorio y la rentabilidad. El cumplimiento normativo en un sistema globalmente compartido puede adaptarse con el etiquetado compatible con GHS y el acceso a la hoja de datos de seguridad (SDS).
- Gestione los productos químicos desde su recepción hasta su eliminación de manera más eficiente.
- Rastree el inventario de reactivos mientras colabora con CRO externos
- Garantice datos de inventario y seguridad química precisos en tiempo real
- Integrar inventario químico con SDS
- Monitorear fechas de vencimiento y vida útil química
- Descubra oportunidades para la minimización de residuos y la reducción de costos
- Abordar los requisitos reglamentarios
Análisis y gestión de datos de cribado basados en placas
ScienceCloud Assay es un entorno completo, liviano y fácil de usar para el análisis y la gestión de datos de cribado basados en placas. Assay permite una personalización rápida siguiendo un flujo de trabajo guiado y configurable para que pueda identificar y seleccionar más fácilmente candidatos óptimos para futuras investigaciones y análisis. Integrado con Pipeline Pilot, Assay le permite diseñar y administrar sus campañas de detección. Su plataforma basada en Oracle cubre el análisis de detección celular, molecular y de alto contenido. Totalmente integrado con su equipo de laboratorio, Assay puede adaptarse a sus necesidades y, por lo tanto, extenderse a tipos de análisis muy específicos.
Características clave
- Control dinámico y dilución para diseño de datos de placa.
- Integrado con los datos del proyecto ScienceCloud para compartir resultados e integrar datos
- Cálculos y estadísticas automatizadas.
- Análisis cruzado y de perfiles
- Integración del modelo de estadísticas R
- Integración con Pipeline Pilot y Tibco Spotfire
Tipos de datos
El ensayo puede procesar una amplia variedad de diferentes tipos de datos basados en placas de varios dominios, incluidos productos biológicos, moléculas pequeñas, agricultura y más. Los tipos de experimentos de cribado comunes incluyen punto final único, respuesta a la dosis, cinética, alto contenido, citometría, QPCR, cromatografía líquida de alto rendimiento, canal iónico y resonancia de plasmón superficial.
Seguimiento y gestión de muestras
ScienceCloud Sample proporciona una solución intuitiva basada en la web para el manejo de muestras biológicas y químicas de bajo a alto volumen relacionadas con placas. Realiza un seguimiento eficaz de grandes cantidades de muestras y los pasos necesarios para prepararlas, incluidas divisiones, agrupaciones, réplicas, reformateos, diluciones, alícuotas y más. Su diseño flexible es compatible con computadoras de escritorio, tabletas y dispositivos móviles, lo que permite a los usuarios llevar su trabajo sin problemas desde su escritorio al banco de laboratorio.
Junto con el Ensayo ScienceCloud, estas soluciones integradas pueden ayudar a los investigadores a rastrear y administrar los datos que provienen de ensayos basados en placas de alto rendimiento para el trabajo y los materiales que lo crearon. Ayuda a los equipos de investigación distribuidos a compartir más rápidamente sus datos y colaborar, agilizando las campañas de detección.
ScienceCloud Sample ayuda a los científicos a automatizar tareas sin valor agregado en el manejo de muestras basadas en placas, simplificando las operaciones de laboratorio y reduciendo los errores manuales.
Características clave
- El sistema basado en el trabajo garantiza una fácil trazabilidad de la muestra.
- Entorno unificado para monitorear el inventario de muestras líquidas y sólidas
- Flujos de trabajo de preparación administrados por el usuario.
- Gestión centrada en el usuario de entidades y diccionarios.
Un nuevo enfoque para el análisis científico colaborativo
Pipette Analysis ofrece un enfoque basado en navegador para responder rápidamente preguntas científicas, presentando un paradigma de interfaz de usuario único y novedoso para análisis y visualización científicos avanzados para científicos que trabajan en el descubrimiento de fármacos. Basado en la aplicación de autoría científica Pipeline Pilot estándar de la industria, Pipette Analysis está disponible ahora en ScienceCloud, el entorno de colaboración y gestión de la información de BIOVIA para investigadores conectados en red a nivel mundial.

Beneficios clave
- Simple de recoger y usar
- Fomenta el análisis colaborativo
- Admite los dispositivos que usan sus científicos
- Se integra con sus datos y aplicaciones.
- Extensible a través de Pipeline Pilot
- Ejecutar en la nube o en su servidor local Pipeline Pilot
Creación de servicios científicos con Pipeline Pilot
Con Pipeline Pilot puede crear y administrar protocolos científicos e implementar reglas comerciales estándar para los socios. Puede integrar sistemas en las instalaciones con las API web de ScienceCloud para que los datos se intercambien fácilmente entre las instalaciones y la nube, lo que facilita la migración por etapas a la nube.
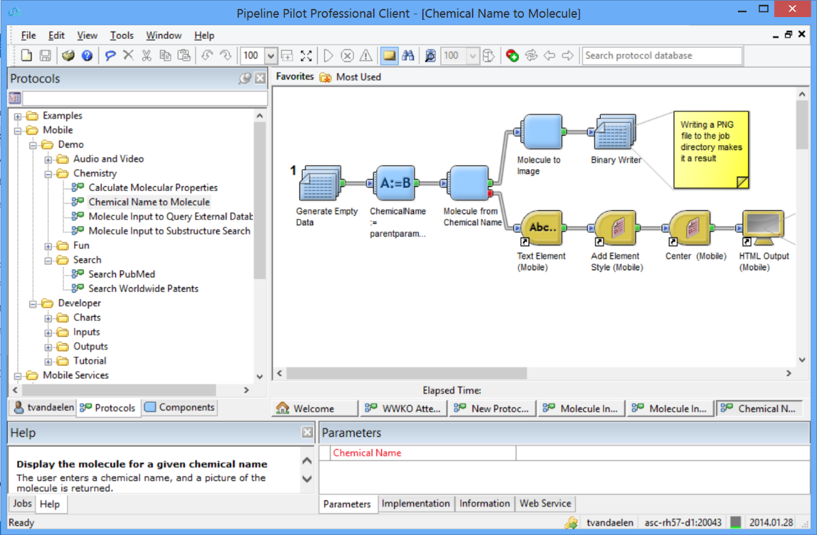
Cree protocolos en Pipeline Pilot e impleméntelos en sus dispositivos móviles
La investigación de descubrimiento ya no es una actividad de 9 a 5 y se extiende mucho más allá de su oficina habitual. ¡Colaboras con personas de diferentes continentes y quieres estar al tanto de las cosas, estés o no en el laboratorio, en un tren o en Starbucks! Con Pipeline Pilot Mobile Collection, puede crear protocolos e implementarlos como tareas en dispositivos móviles
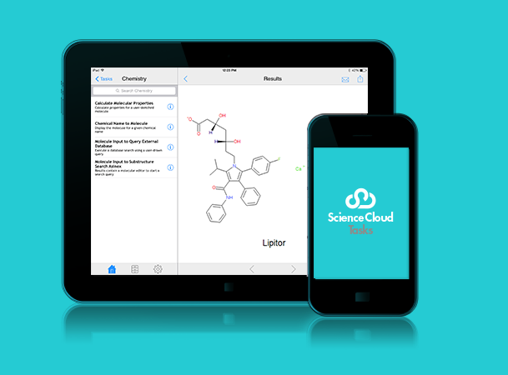
Beneficios clave
- Cree e implemente rápidamente protocolos listos para dispositivos móviles con Pipeline Pilot
- Produzca cuadros de mando, cuadros y gráficos optimizados para dispositivos móviles.
- Aproveche la captura de imágenes, los servicios de ubicación, el bosquejo de productos químicos y el manejo de audio / video / habla para tareas especiales
- Implemente tareas específicas para audiencias de usuarios específicas, en cualquier lugar y en cualquier momento.
El intercambio de protocolos de ScienceCloud: Compartir. Descargar. ¡Innovar!
ScienceCloud Protocol Exchange es un nuevo sitio para que los usuarios de Pipeline Pilot compartan servicios de protocolo creados con Pipeline Pilot. El intercambio ayudará a fomentar la rápida adopción de métodos y enfoques científicos innovadores desarrollados por la comunidad en general. Los servicios de intercambio incluyen aquellos que se ejecutan en Pipeline Pilot, pero también incluyen servicios que se pueden implementar en otras aplicaciones basadas en plataformas como Discovery Studio, Materials Studio, Pipette Analysis, Web Port y Notebook.
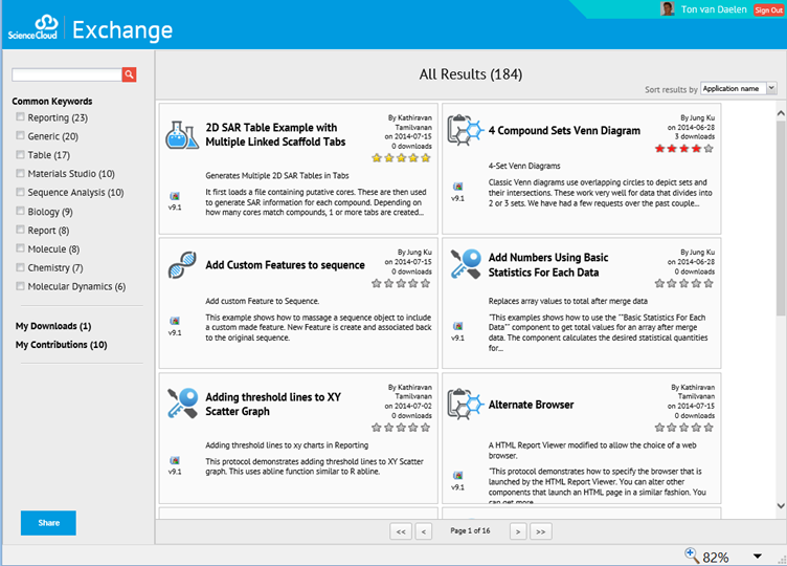
Una vez que se publica un servicio, la comunidad puede calificar, revisar y comentar un protocolo. Puede compartir su idea para una nueva función, sugerir una mejor manera de hacer algo o hacerle una pregunta al autor. Este intercambio entre autores y usuarios aumentará rápidamente la calidad y diversidad de los servicios que se ofrecen y traerá nuevas ideas, enfoques y soluciones a la comunidad de usuarios en general.
- Detalles
- Categoría: Minitab
- Visto: 8857
Por Evan McLaughlin.
Ya sea que esté en el modo "limpieza de primavera", finalmente trabajando en su novela, probando los podcasts o echando un vistazo a la serie de Netflix que aún no había podido ver, muchos de nosotros últimamente estamos quedándonos en casa. En Minitab estamos trabajando de forma remota en este momento, y en realidad estamos descubriendo que no hay mejor momento para aprender algunas cosas nuevas.
En este momento, nos pusimos en marcha para buscar algunos trucos que quizás no conozcas de Minitab Statistical Software. En realidad empezamos esta lista a principios de 2020 (puedes echarle un vistazo aquí) cuando preguntamos a los clientes, nuevos y antiguos, usuarios nuevos y experimentados, ¿dónde empezar cuando se tiene una interfaz fácil de usar y todas las herramientas a tu alcance para analizar rápidamente los datos y tomar decisiones sobre sus problemas de negocio más desafiantes?
Algunos de nuestros expertos en Minitab desarrollaron el nuevo recurso de aprendizaje electrónico gratuito Minitab Quick Start™ teniendo esto en cuenta. Esperamos que estos 5 consejos resumidos a continuación le muestren algo nuevo que pueda ayudarle a analizar sus datos de manera más rápida y eficiente. Y si está interesado en obtener un recorrido por ellos, asegúrese de inscribirse en Minitab Quick Start.
![]()
1. Utilice la función "Transponer columnas" para cambiar filas por columnas
Ya sea que se introduzcan datos manualmente, se importen desde una hoja de cálculo CSV o Excel que puede haber sido formateada de manera diferente, o copiándolos y pegándolos, a veces los datos se introducen en filas cuando se supone que deben introducirse en columnas. La función Transponer columnas le permite cambiar rápida y fácilmente filas por columnas en su hoja de trabajo. Para acceder a esta función en Minitab, seleccione Datos > Transponer columnas. Luego, introduzca el rango de valores de todas las filas que contienen lo que desea transponer en columnas.
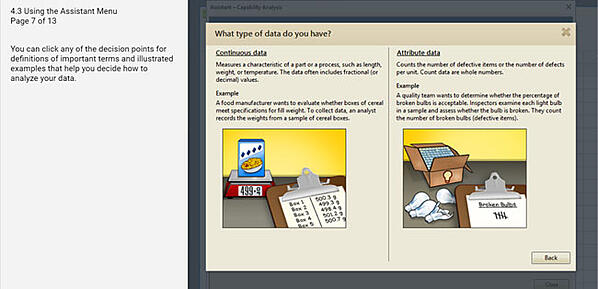
2. Use el menú Asistente para orientarse al seleccionar las mejores herramientas
El menú Asistente es una función única en Minitab que es extremadamente útil cuando necesita orientación para seleccionar las mejores herramientas estadísticas para usar en los problemas que está tratando de resolver.
Entonces, ¿cómo funciona el menú Asistente? Incluye muchos de los análisis y gráficos que se encuentran en otros menús de Minitab. Sin embargo, el menú Asistente es especialmente útil en situaciones específicas y comunes. Por ejemplo, si usted:
- Necesita ayuda para decidir qué análisis estadístico ejecutar
- Desea que Minitab verifique los supuestos estadísticos de su análisis
- Desea una salida que sea más gráfica y que explique cómo interpretar sus resultados en detalle

3. Utilice la herramienta de destacado para concentrarse en puntos de datos específicos
La herramienta Pincel es un gran activo para muchos gráficos en Minitab. Con la herramienta Pincel, puede seleccionar uno o más puntos de datos para identificar fácilmente la información correspondiente de la hoja de trabajo del punto de datos. Como ejemplo, si observa un valor atípico en su diagrama de dispersión, puede usar esta herramienta para obtener más información sobre este punto de los datos.
Para acceder a la herramienta de pincel , haga clic derecho en el gráfico y elija Destacar de pincel . Aparecerá un panel al lado del gráfico. Haga clic en un punto de datos o arrastre el mouse sobre varios puntos para obtener datos sobre estos puntos. Si los puntos individuales no están adyacentes entre sí, puede presionar y mantener presionada la tecla Mayús y hacer clic en los puntos deseados.
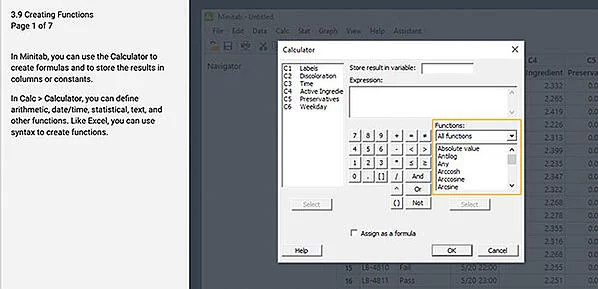
4. Utilice la calculadora para crear y almacenar fórmulas
Puede usar la Calculadora en Minitab (Calc > Calculadora...) para crear fórmulas y almacenar los resultados en columnas o constantes. Con la herramienta Calculadora, puede definir fecha/hora, aritmética, estadística, texto y otras funciones. Cuando abra el cuadro de diálogo Calculadora, verá las funciones que están disponibles en Minitab. La sintaxis que necesita usar se mostrará en el cuadro de diálogo cuando elija una función. Al seleccionar la opción Asignar como fórmula, se permitirán actualizaciones automáticas de las celdas calculadas.
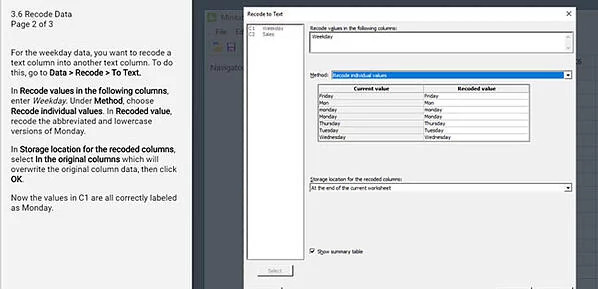
5. Recodificar datos incorrectos
Cuando los datos en su hoja de cálculo estén etiquetados incorrectamente o necesiten editarse, los valores se pueden cambiar fácilmente en una o más columnas usando la función Recodificar (Datos> Recodificar...). Esta característica le permite recodificar rangos de valores, un solo valor o un conjunto de valores individuales. Además, puede volver a codificar sus datos en formato numérico, de texto o de fecha/hora o utilizar una tabla de conversión. Usar una tabla de conversión es una forma rápida y fácil de recodificar muchos valores individuales.
Ahora no nos malinterpreten. Incluso los usuarios experimentados de Minitab a menudo recurren a nuestro soporte técnico de clase mundial para ayudarles a guiarse en su camino a veces (¡para eso están!). Sin embargo, el uso de estos trucos puede ayudarlo a navegar por Minitab de manera más rápida y eficiente antes de que necesite levantar el teléfono. Si está interesado en obtener más lecciones gratuitas sobre el uso de la interfaz del software estadístico Minitab, consulte estas y más en nuestro nuevo módulo de aprendizaje electrónico Minitab Quick Start.
- Detalles
- Categoría: Addlink
- Visto: 5377

Addlink Software Científico le informa que se adhiere a las iniciativas de teletrabajo, como medio de lucha contra COVID-19, y que permanece completamente operativo para todos nuestros clientes.
Pueden contactar con nosotros mediante correo electrónico o por teléfono 93 415 49 04 (Barcelona) - 91 515 82 76 (Madrid).
Desde hace ya unos días empezamos a reconfigurar todos nuestros eventos para ofrecerlos de forma virtual. Puede consultar nuestra agenda si está interesado en registrarse en cualquiera de los seminarios web que ofrecemos periódicamente.
https://www.addlink.es/eventos
Un cordial saludo,
El equipo de Addlink Software Científico
- Detalles
- Categoría: Maple
- Visto: 4999

Maple 2020 ofrece una vasta colección de mejoras tanto para los usuarios experimentados como para aquellos que utilicen Maple por primera vez. Además de un motor matemático todavía más potentes, Maple 2020 también proporciona nuevas y mejoradas herramientaspara la resolución interactiva de problemas, el desarrollo de aplicaciones, el aprendizaje de los estudiantes, la creación de documentos, la programación, y mucho más.
Mientras más matemática, mejor
Temas nuevos, cobertura más amplia y profunda, nuevos algoritmos y técnicas: en Maple 2020 el motor matemático sigue siendo más potente para que pueda resolver más problemas.
Resolviendo más ODE y PDE
Maple es el líder mundial en la búsqueda de soluciones exactas para ecuaciones diferenciales ordinarias y parciales, y Maple 2020 amplía esa ventaja aún más con nuevos algoritmos y técnicas de resolución.
¡Eso probablemente es un problema de teoría de grafos!
Además de tratarse de un tema interesante en sí mismo, la teoría de grafos también tiene aplicaciones en ciencias, ingeniería, lingüística, sociología, informática y más, y el extenso paquete de teoría de grafos de maple brinda las herramientas necesarias para resolver esos problemas.
Transformaciones difíciles (del tipo integral)
Las Transformaciones integrales en Maple se han ampliado para que sean más útiles para una variedad de aplicaciones en física matemática, ingeniería y más.
Ayuda para nuevos usuarios
Con recurso de iniciación (Getting Started) nuevos y más fácilmente accesibles, advertencias integradas para ayudar a los usuarios a evitar errores, y más, Maple 2020 está diseñado para ayudar a los nuevos usuarios a ser productivos más rápido que nunca.
Aprender álgebra lineal
Más herramientas de matemática "clicable", tutores mejorados y un paquete ampliado para estudiantes ofrecen aún más apoyo para enseñar y aprender álgebra lineal.
Por tanto la matemática tan solo se clica
Maple 2020 incluye mucha herramientas nuevas y mejoradas de Clickable Math™, que incluyen aplicaciones matemáticas, tutores y menús contextuales, para facilitar aún más el aprendizaje de conceptos matemáticos y la realización de operaciones matemáticas.
Impresión y exportación
Más flexibilidad y resultados mejorados para imprimir, exportar a PDF, y la exportación de LaTeX hace que su contenido sea más fácil de compartir y usar fuera de Maple.
Procesado de señal
Las capacidades de procesado de señal de Maple se han mejorado aún más para admitir la exploración de señales de todo tipo, incluidos el procesado de datos, imágenes y audio.
Trazado de errores
Herramientas de programación mejoradas ayudan a encontrar y solucionar problemas en tu propio código.
- Detalles
- Categoría: Minitab
- Visto: 90213
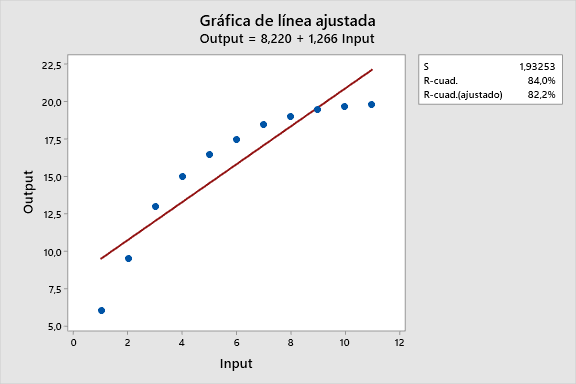
A menudo pensamos en una relación entre dos variables como una línea recta. O sea, si se incremente un predictor en 1 unidad, la respuesta siempre crece en X unidades. Sin embargo, no todos los datos tienen una relación lineal, y el modelo debe de ajustarse a las curvas que presentan los datos.
¡Este gráfico de línea ajustada muestra la tontería de utilizar una línea para ajustar una relación curva!
¿Cómo ajustamos una curva a los datos? Afortunadamente, Minitab Statistical Software incluye una variedad e métodos de ajuste de curvas tanto en regresión lineal como no lineal.
Para comparar estos métodos, ajustaremos modelos a la algo complicada curva del gráfico de línea ajustada. Para otros propósitos, consideraremos que estos datos vienen de un proceso físico de bajo ruido que tiene una función curva. Queremos predecir con precisión la salida dada la entrada.
Ajustar curvas con términos polinomiales en regresión lineal
La forma más común de ajustar curvas a los datos utilizando la regresión lineal es incluir términos polinomiales, como predictores cuadráticos o cúbicos.
Típicamente, se escoge el orden del modelo por el número de curvas que se necesitan en la línea. Es muy raro utilizar más que un término cúbico.
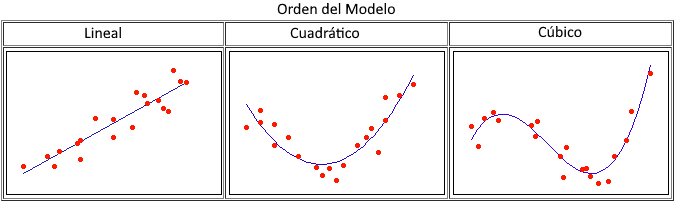
El gráfico de los datos parece tener una curva, por lo que intentaremos ajustar un modelo lineal cuadrático utilizando Estadística > Regresión > Gráfica de línea ajustada
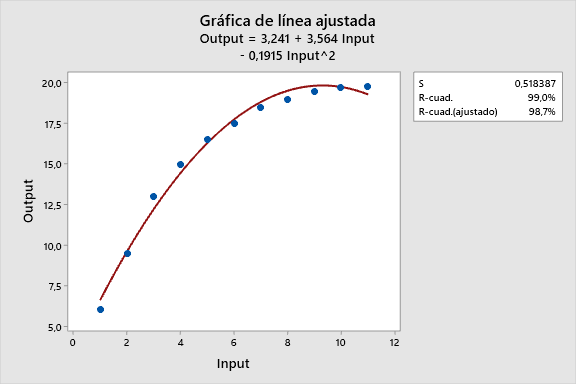
Mientras el coeficiente de determinación R-cuadrado (R2) es alto, el gráfico de línea ajustada muestra que la línea de regresión sistemáticamente sobre- e infra- predice los datos en diferentes puntos de la curva. Esto muestra que uno no siempre se puede fiar de un R-cuadrado alto.
Veamos si podemos hacerlo mejor.
Ajuste de curvas con términos recíprocos en regresión lineal
Si los datos de respuesta descienden a un suelo, o ascienden a un techo a medida que la entrada crece (por. ej., se aproximan a una asíntota), se puede ajustar este tipo de curva en una regresión lineal incluyendo el recíproco (1/X) de una variable predictora más en el modelo. De forma más general se desea utilizar esta forma cuando el tamaño del efecto para una variable predictora decrece cuando su valor crece.
Como la pendiente es una función de 1/X, la pendiente se hace más plana cuando crece X. Pare este tipo de modelo, X nunca puede ser igual a 0 porque no se puede dividir por cero.
Observando los datos, parece que se aplanana y se aproximan a una asíntota en algún punto alrededor de 20.
Utilizando Calc > Calculadora para crear una columna 1/Input (InvInput). ¡Veamos cómo funciona! Lo ajustamos tanto con un modelo lineal (arriba) como con uno cuadrático (abajo).
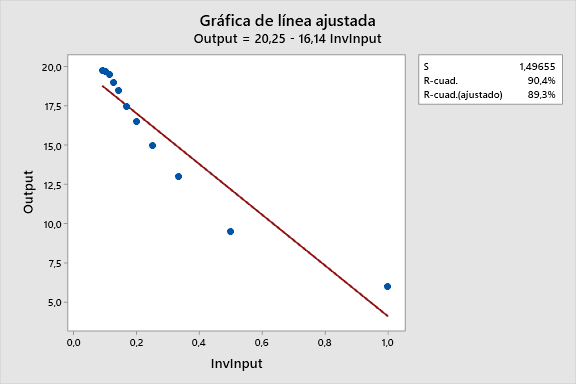
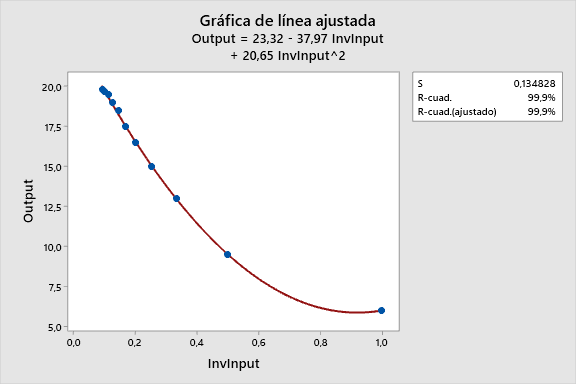
Para este ejemplo en particular, el modelo recíproco cuadrático se ajusta a los datos mucho mejor. El gráfico de línea ajustada cambia el eje X a 1/Input, por lo que es difícil de ver la curvatura natural de los datos.
En la gráfica de dispersión inferior, se utilizan las ecuaciones para dibujar los puntos ajustados para ambos modelos en la escala natural. Los puntos de datos verdes claramente se acercan más a la línea cuadrática
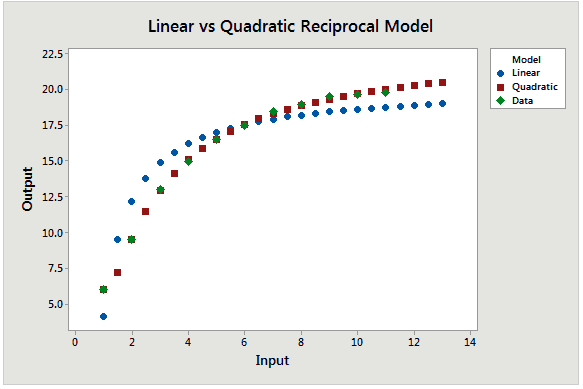
Comparado con el modelo cuadrático, el modelo recíproco con el término cuadrático tiene un valor S más bajo (bien), mayor R-cuadrado (bien), y no muestra predicciones desviadas. Así que hasta ahora este es nuestro mejor modelo.
Transformar las variables con funciones logarítmicas en regresión lineal
Una transformación logarítmica es un método relatívamente común que permite a la regresión lineal realizar ajustes de curvas que de otra forma solo serían posibles con regresión no lineal.
Por ejemplo, la función no lineal:
Y=eB0X1B1X2B2
puede expresarse en forma lineal como:
Ln Y = B0 + B1lnX1 + B2lnX2
Se puede tomar el logaritmo de ambos lados de la ecuación, como arriba, lo que se conoce como la forma doble logaritmo. O se puede tomar el logaritmo de solo un lado, conocida como la forma semilogaritmo. Si se toman los logaritmos en el lado del predictor, puede ser para todos o solo algunos de los predictores.
Las formas funcionales logarítmicas pueden ser bastante potentes, pero existen demasiadas combinaciones para entrar en detalles en esta visión general. La elección de doble logaritmo versus semilogaritmo (para la respuesta o los predictores) depende de la especificidad de los datos y del conocimiento del área temática. En otras palabras, si se coge este camino se necesitará investigar un poco.
Volviendo al ejemplo. Para datos donde la curva se aplana a medida que el predictor crece, un modelo semilogarítmico de los predictores puede ajustar. ¡Intentémoslo!
El gráfico de línea ajustada de Minitab dispone convenientemente de la opción para transformar logarítmicamente uno o ambos lados del modelo. Así que se ha transformado solo la variable predictora en el gráfico de línea ajustada inferior.
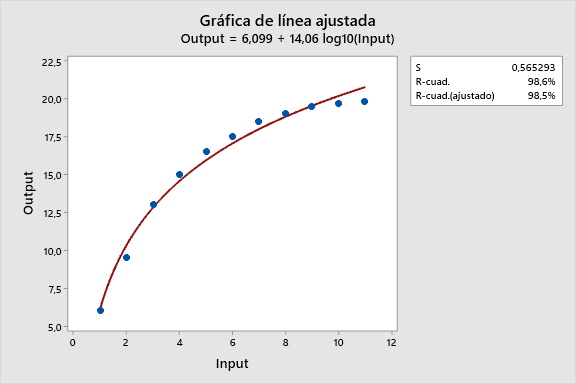
Visualmente podemos ver que el modelo semilogarítmico sistemáticamente sobre- e infra- predice los datos en diferentese puntos de la curva, igual que el modelo cuadrático. Los valores S y R-cuadrado también son virtualmente idénticos a los de ese modelo.
Hasta aquí, el modelo lineal con los términos recíprocos todavía proporcionan el mejor ajuste para los datos curvos.
Ajuste de curvas con regresión no lineal
La regresión no lineal puede ser una potente alternativa a la regresión lineal porque proporciona la funcionalidad de ajuste de curvas más flexible. El truco es encontrar la función no lineal que mejor se ajusta a la curva específica de los datos. Afortunadamente Minitab proporciona herramientas para facilitarlo.
En el cuadro de diálogo Regresión no lineal (Estadísticas > Regresión > Regresión no lineal), entrar Output para Respuesta. Después haga clic en Usar catálogo para escoger entre las funciones no lineales que Minitab proporciona.
Sabemos que nuestros datos se aproximan a una asíntota, así que podemos seleccionar en las dos funciones de Regresión Asintótica. La versión cóncava se ajusta más a nuestros datos. Seleccionamos esta función y hacemos clic en Aceptar.
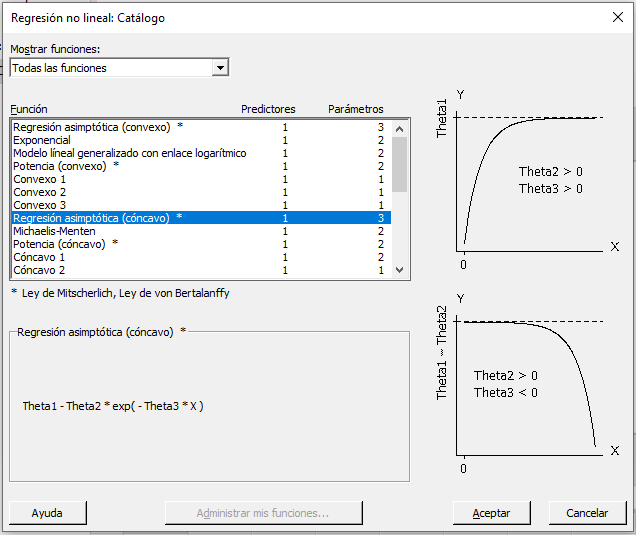
Después Minitab muestra un diálogo donde escogemos nuestro predictor.
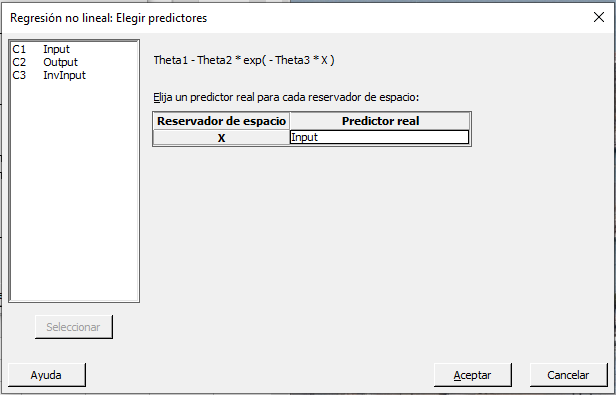
Entre Input, clique Aceptar, y volvemos al diálogo principal.
Si hacemos clic en Aceptar del diálogo principal, Minitab muestra el siguiente cuadro de diálogo:
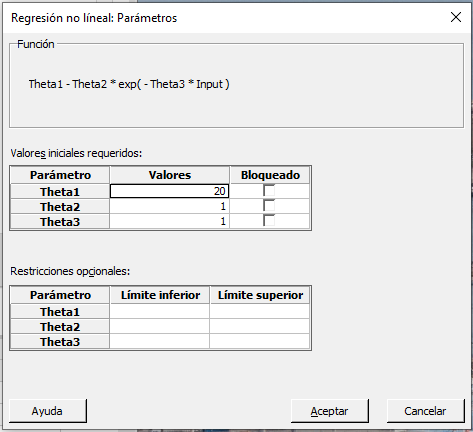
A diferencia de la regresión lineal, la regresión no lineal utiliza un algoritmo para encontrar el mejor ajuste paso a paso. Se necesita proporcionar los valores de arranque para cada parámetro de la función. ¡Vaya, no tengo ni idea! Por suerte Minitaba lo facilita.
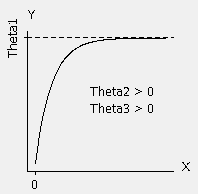
Volvamos a la función que escogimos. ¡La figura lo facilita!
Nótese que Theta1 es la asíntota, o el techo, al que nuestros datos se aproximan. A la vista del primer gráfico de dispersión, eso ocurre aproximadamente en 20 para nuestros datos. Par un caso como el nuestro, donde la respuesta se aproxima a un techo cuando el predictor crece, Theta2 > 0 y Theta3 > 0.
Consecuentemente entramos lo siguiente en el cuadro de diálogo:
- Theta1: 20
- Theta2: 1
- Theta3: 1
Después de entrar esos valores, volvemos al diálogo principal, clicamos Aceptar, y ¡voila!
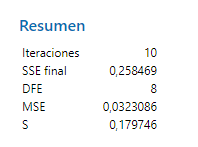
Es imposible calcular R-cuadrado para la regresión no lineal, pero el valor S para el modelo no lineal (0.179746) es prácticamente tan pequeño como el del modelo recíproco (0.134828). Queremos un valor S pequeño porque significa que los puntos de los datos caen más cerca de la línea curva de ajuste. El modelo no lineal tampoco tiene una desviación sistemática.
Comparación de la efectividad del ajuste de curvas de los diferentes modelos
| Modelo | R-cuadrado | S | Ajuste desviado |
| Recíproco-cuadrático | 99.9 | 0.134828 | No |
| No lineal | N/A | 0.179746 | No |
| Cuadrático | 99.0 | 0.518387 | Sí |
| Semilogarítmico | 98.6 | 0.565293 | Sí |
| Recíproco-lineal | 90.4 | 1.49655 | Sí |
| Lineal | 84.0 | 1.93253 | Sí |
Tanto el modelo lineal con el término recíproco cuadrático como el modelo no lineal vencen a los otros modelos. Estos dos modelos superiores producen predicciones igualmente buenas para la relación curva. Sin embargo, el modelo de regesión lineal con los términos recíprocos también produce valores-p para los predictores (todos significativos) y un R-cuadrado (99.9%), ninguno de los cuales puede obtenerse para un modelo de regresión no lineal.
Para este ejemplo, estas estadísticas extra pueden ser convenientes para un informe, aunque los resultados no lineales sean igual de válidos. Sin embargo, en casos donde el modelo no lineal proporciona el mejor ajuste, se debería de proceder con el mejor ajuste.
Últimos pensamientos
Si se tiene una curva difícil de ajustar, encontrar el modelo correcto puede parecer una tarea inmensa. Sin embargo, después de todo el esfuerzo para obtener los datos, vale la pena encontrar el mejor ajuste posible.
Al especificar cualquier modelo, debería permitir que la teoría y el conocimiento sobre el área temática le guíe. Algunas áreas tienen prácticas y funciones estándar para modelar los datos.
Si bien se desea un buen ajuste, no se desea inflar artificialmente el R-cuadrado con un modelo demasiado complicado. Hay que ser consciente que:
- R-cuadrado puede ser engañoso
- Los modelos demasiado complicados pueden producir resultados engañosos
- Verificar los gráficos residuales evita resultados engañosos (no se han mostrado en este artículo, pero el autor los revisó).
- Detalles
- Categoría: Comsol
- Visto: 8585
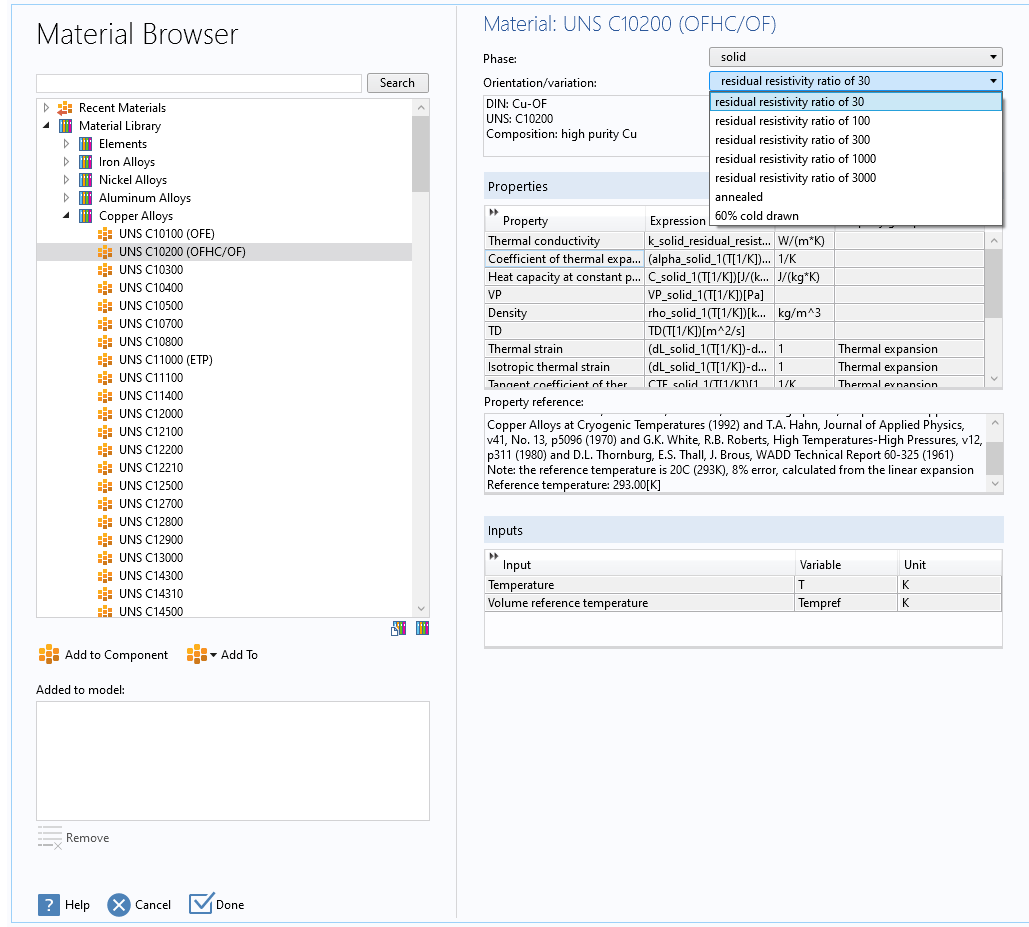
Toda simulación requiere el uso de un conjunto de materiales y, por tanto, de la definición de una serie de parámetros de los mismos que nos permitan emular el comportamiento de los fenómenos físicos sobre estos materiales.
COMSOL Multiphysics y la mayoría de sus módulos incluyen bibliotecas de materiales integradas. Cada biblioteca de materiales consiste en una base de datos de materiales y sus propiedades asociadas. Además de estas librerías de materiales incluídas con los módulos existe un producto adicional Material Library Module, que contiene hasta 24 propiedades de materiales para más de 3800 materiales (versión 5.5).
En la entrada del blog de COMSOL "Using the Materials Libraries in COMSOL Multiphysics®", Magnus Ringh hace un repaso sobre las librerías de materiales incluídas en los módulos y del módulo Material Library, y de cómo utilizarlas en las simulaciones.