- Detalles
- Categoría: Maple
- Visto: 657

Este vídeo muestra tres maneras en que Maple Flow puede mejorar los cálculos de diseño de ingeniería rutinarios que requieren mucho tiempo para completar.
Esto incluye ofrecer opciones flexibles de diseño y formato, aumentar la confiabilidad de los cálculos (mediante el seguimiento de unidades y realizar funciones matemáticas avanzadas) y promover un flujo de trabajo estandarizado para plantillas de proyectos y hojas de trabajo de diseño.
- Detalles
- Categoría: NAG
- Visto: 973
En Mark 29.3, NAG presenta un resolvedor de vanguardia (nag_mip_handle_solve_milp) diseñado específicamente para abordar problemas de programación lineal entera mixta (MILP) a gran escala. Esto marca un paso significativo en el compromiso de NAG de mejoar y ampliar sus ofertas en el campo de la optimización matemática.
MILP encuentra una aplicación generalizada en diversas industrias, incluidas, entre otras, la fabricación, la logística, el transporte y las telecomunicaciones. Al acomodar variables de decisión tanto continuas como discretas, el resolvedor permite a las organizaciones modelar problemas prácticos y complejos, incluyendo la asignación de recursos, la programación y el flujo de red.
Problemas MILP a gran escala de la forma
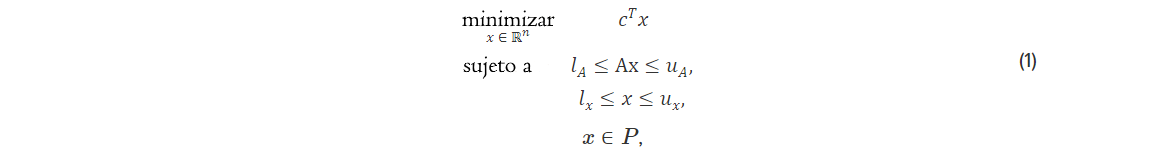
dónde 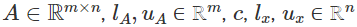 son los datos del problema y
son los datos del problema y 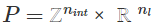 son bastante omnipresentes en aplicaciones de la vida real. Es importante resaltar que resolver problemas MILP plantea un desafío considerable debido a su naturaleza combinatoria y, en muchos escenarios prácticos, encontrar una solución exacta en un tiempo razonable puede resultar muy difícil. Nos complace presentar la última incorporación a la librería NAG y nuestro objetivo es ayudar a los usuarios a tomar decisiones de manera eficiente y precisa.
son bastante omnipresentes en aplicaciones de la vida real. Es importante resaltar que resolver problemas MILP plantea un desafío considerable debido a su naturaleza combinatoria y, en muchos escenarios prácticos, encontrar una solución exacta en un tiempo razonable puede resultar muy difícil. Nos complace presentar la última incorporación a la librería NAG y nuestro objetivo es ayudar a los usuarios a tomar decisiones de manera eficiente y precisa.
Modelado y resolución MILP
El modelo (1) cubre muchos casos de uso práctico. Una de las características distintivas de MILP es su capacidad para modelar condiciones lógicas como implicaciones o dicotomías.
Tomemos como ejemplo el modelado de carga fija. Las actividades económicas frecuentemente implican costes tanto fijos como variables. En estos casos, un coste fijo fix solo ocurre cuando variable y es positiva. Dado un coste variable cvar, el coste total cuando y>0 es cfix+cvary y 0 en caso contrario. Es fácil observar que la función de costes no es lineal. Introduciendo una variable binaria x podemos modelarlo como la expresión lineal
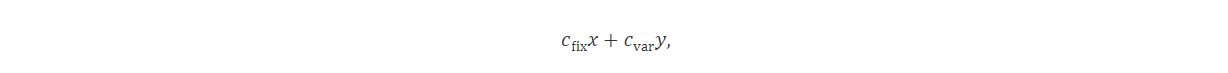
Donde añadimos restricciones
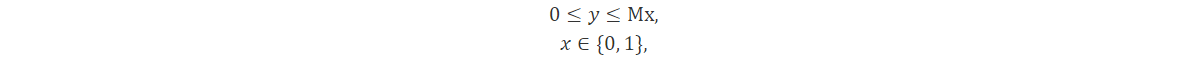
Donde M es un límite superior de y y debe elegirse como el límite más estricto conocido, en lugar de un límite arbitrariamente grande M. Esta técnica de modelado aparece en aplicaciones como la ubicación de instalaciones y el diseño de redes.
Otro gran uso de MILP es modelar disyunciones. Por ejemplo, al programar trabajos en una máquina, es posible que deseemos permitir el trabajo i para ser programado antes del trabjo j o viceversa. Consideremos que pi y pj denotan el tiempo de procesamiento del trabajo i y j, mientras que ti y tj representan sus tiempos de inicio. Entonces requeriremos que se cumpla al menos una de las siguiente restricciones.
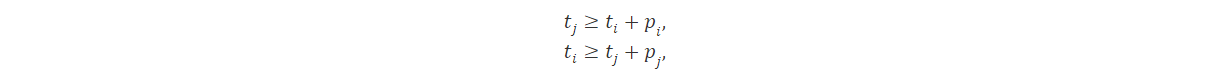
Introduciendo variables binarias x1 y x2 el problema se puede modelar como
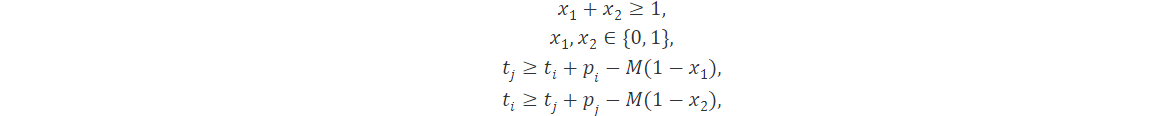
donde M nuevamente es positivo y sirve como límite conocido.
Hay muchos otros tipos de restricciones que son muy útiles en el campo de la investigación de operaciones, incluidas, entre otras,
- Variables semicontinuas donde una variable x es 0 o está en un intervalos [a,b],
- variables que solo toman valores de un conjunto, por ejemplo
 ,
, - funciones lineales continuas por partes, que pueden verse como una combinación de funciones lineales.
Consulte [1,2] para conocer más técnicas de formulación y su uso en la programación.
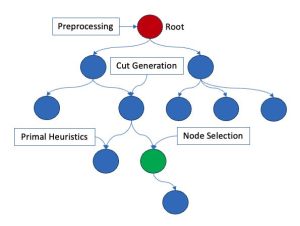
Figura 1: Ilustración de un árbol de ramificación y acotamiento
Para resolver (1) de manera eficiente, el algoritmo de ramificación y acotamiento sirve como marco fundamental, que está equipado con técnicas MILP modernas como preprocesamiento, generación de cortes y diversas heurísticas. En la Figura 1 se muestra una parte de un árbol de ramificación y acotamiento. A partir del problema original, denominado nodo raíz, el algoritmo genera varios nodos secundarios dando forma a la región factible mediante la adición de más restricciones, como el corte fraccional de Gomory. Cada nodo se resuelve como una programación lineal continua mediante un método simplex dual eficiente. Se adoptan varias heurísticas para obtener un mejor límite inferior. Al poder con éxito el árbol de búsqueda y seleccionar los nodos de búsqueda, aumenta en gran medida la posibilidad de que un algoritmo de ramificación y enlace encuentre la solución óptima en un tiempo razonable. Consulte [3] para obtener más detalles sobre algortimos para resolver MILP.
El resolvedor MILP nag_mip_handle_solve_milp está completamente integrado en NAG Optimization Modelling Suite, que permite a los usuarios expresar mejor los problemas del mundo real en el modelo matemático, mejorando la comprensión del funcionamiento interno del modelo. Durante el proceso de modelado, los usuarios pueden
- ver el efecto de una restricción o variable particular eliminándolas temporalmente y luego recuperándolas;
- modificar coeficientes individuales del objetivo lineal o de las restricciones lineales;
- fijar una variable a una constante dada, lo que da como resultado la eliminación de una variable en toda la formulación y la disminución de la dimensión del problema.
El resolvedor está disponible para múltiples lenguajes y entornos, incluyendo C y C++, Python, Java, .NET y Fortran, en Windows, Linux y MacOS.
Referencias
[1] Vielma JP. Mixed integer linear programming formulation techniques. Siam Review. 2015;57(1):3-57.
[2] Floudas CA, Lin X. Mixed integer linear programming in process scheduling: Modeling, algorithms, and applications. Annals of Operations Research. 2005 Oct;139:131-62.
[3] Conforti M, Cornuéjols G, Zambelli G, Conforti M, Cornuéjols G, Zambelli G. Integer programming models. Springer International Publishing; 2014.
- Detalles
- Categoría: Comsol
- Visto: 721
Introduccion
La simulación acoplada es una característica clave en COMSOL Multiphysics que permite a los ingenieros modelar interacciones complejas entre múltiples fenómenos físicos. En este artículo, exploraremos las aplicaciones prácticas de la simulación acoplada en diversas industrias y cómo COMSOL simplifica la resolución de problemas multidisciplinarios.
Simulación acoplada
La simulación acoplada implica la resolución simultánea de múltiples fenómenos físicos interrelacionados en un sistema o proceso. En el contexto de software de simulación como COMSOL Multiphysics, permite modelar fenómenos como transferencia de calor, mecáncia de fluidos y electromagnetismo de manera conjunta. Esto es esencial cuando los diferentes aspectos físicos de un sistema están estrechamente vinculados y afectan mutuamente, permitiendo así una representación más precisa y completa de situaciones del mundo real.
Aplicaciones
La simulación acoplada en COMSOL Multiphysics ofrece una potente capacidad para modelar la interacción simultánea de diversos fenómenos físicos en sistemas complejos. Desde el diseño mecánico con transferencia de calor hasta la investigación de materiales y la bioingeniería, esta funcionalidad permite abordar de manera integrada desafíos multidisciplinarios. Al acoplar fenómenos como electromagnetismo y estructuras mecánicas, COMSOL posibilita la simulación realista de dispositivos electrónicos, mientra que, en la eficiencia energética, la consideración conjunta de aspectos térmicos, mecánicos y fluidodinámicos lleva a soluciones más eficientes. Este enfoque integral proporciona una visión más completa y precisa de la realidad, impulsando avances de campos ingenieriles y científicos. A continuación mostramos 2 ejemplos representativos. En un primer caso (el busbar) se utilizan interfaces de los módulos de AC/DC, Heat Transfer, CFD y Structural Mechanics. En el segundo caso (dielectroforesis) se utilizan interfaces de los módulos AC/DC, CFD y Particle Tracing for Fluids.
Ejemplo 1: Descripción más integral del modelo
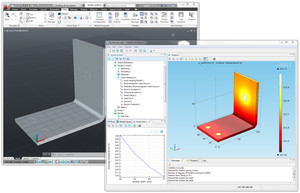
Uno de los ejemplos clásicos aportados por COMSOL es el modelo del "Busbar". En dicho dispositivo se aplica una diferencia de potencial por el que fluye una corriente eléctrica. Debido al Efecto Joule el dispositivo se caliente y disipa energía en forma de calor. Primeramente, el ejemplo de COMSOL modela la convección natural a través del coeficiente de transferencia de calor h. En este caso hemos cambiado la configuración para implementar un "single phase flow" y con ello estudiar en detalle la convección. Finalmente, hemos añadido otro acoplamiento para dar cuenta de la expansión térmica del dispositivo. Así, los nodos de Multifísica son Elecgtromagnetic Heat Source y Thermal Expansion. No obstante, el acoplamiento entre la Transferencia de calor y Fluidodinámica se ha hecho de manera manual. Para visualizar el resultado, véase la Figura 1. Se puede apreciar en las paredes del bloque y del busbar la distribución de temperatura. En los cantos del dispositivo se puede ver el desplazamiento debido a la expansión térmica. Además las líneas de corriente representan la magnitud de la velocidad del aire, cuando éste entra por el contorno de la derecha hacia la izquierda.
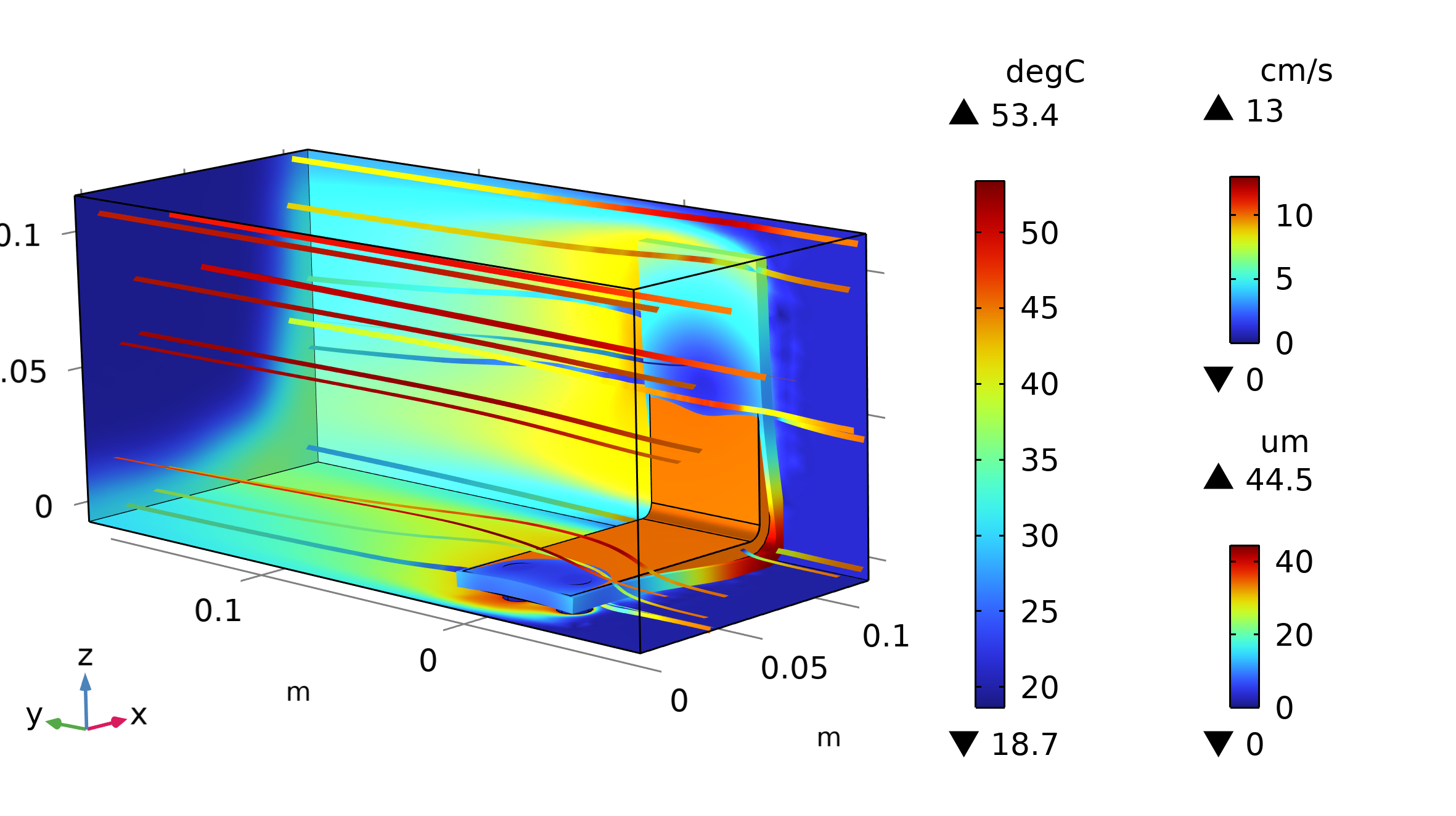
Figura 1: Visualización de la distribución de temperatura (paredes), magnitud de la velocidad del aire (líneas de corriente) y desplazamiento del busbar debido a la expansión térmica.
Ejemplo 2: Dielectroforesis
Otro ejemplo con más de un acoplamiento es el modelo "Dieletrophortic separation" [2]. La dielectroforesis (DEP) se produce cuando una fuerza actúa sobre una partícula dieléctrica sometida a un campo eléctrico no uniforme. Con aplicaciones en dispositivos biomédicos para biosensores, diagnósticos y manipulación de partículas, la DEP se aprovecha de las diferencias en tamaño y propiedades dieléctricas para separar células en mezclas. En el dispositivo DEP de filtrado, las células más grandes, como los glóbulos rojos, se desvían más debido a una fuerza mayor, permitiendo su separación de otras partículas. La aplicación ofrece la posibilidad de ajustar características como el campo eléctrico y propiedades de las células. La descripción de los fluidos requiere el uso de la interfaz de Creeping Flow en CFD. La visualización final de la separación se hace por medio de la interfaz Particle Tracing in Fluids. Ver Resultados en Figura 2.
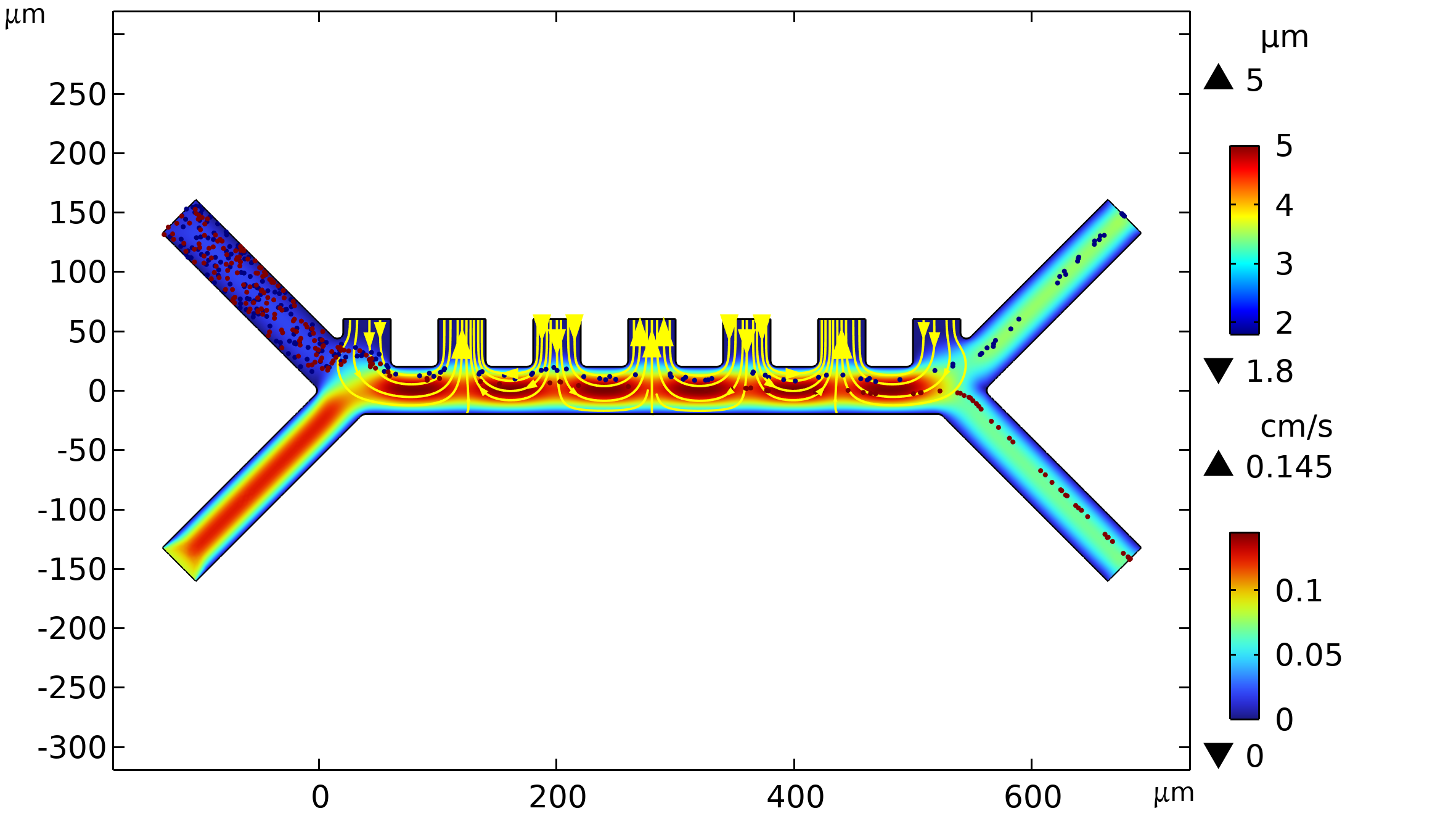
Figura 2: Visualización de la magnitud de la velocidad, partículas (glóbulos rojos y plaquetas en azul) cuya leyenda muestra el diámetro y líneas de campo eléctrico (color amarillo).
Conclusión
La simulación acoplada en COMSOL Multiphysics es un elemento clave, permitiendo la modelación integral de fenómenos físicos interrelacionados. Desde el diseño de dispositivos electrónicos hasta la eficiencia energética y la investigación biomédica, esta capacidad de abordar problemas multifísicos ha llevado a avances en el proceso de diseño y desarrollo. A medida que la tecnología avanza, la simulación acoplada en COMSOL seguirá siendo esencial para enfrentar desafíos multidisciplinarios, transformando la forma en que abordamos problemas complejos.
Referencias
[1] Galería de aplicaciones de COMSOL: Electrical Heating in a Busbar
[2] Galería de aplicaciones de COMSOL: Dielectrophoretic Separation of Platelets from Red Blood Cells
- Detalles
- Categoría: Minitab
- Visto: 771

Por Óliver Franz.
Un departamento de Tecnologías de la Información (TI) con una importante acumulación de tickets puede indicar varios problemas subyacentes. A los efectos de este artículo, definamos un ticket como un problema planteado por un usuario para notificar a la empresa que su tecnología no funciona como se esperaba.
Independientemente de la causa, el resultado son clientes insatisfechos. De hecho, el problema puede incluso agravarse a medida que los clientes envían varios tickets con la esperanza de una respuesta más rápida, lo que genera un mayor retraso. Al aprovechar Minitab Statistical Software y el Módulo de analítica predictiva, los departamentos de TI pueden identificar la causa raíz del problema y abordarla, lo que resulta en una acumulación de pedidos menor (¡o nula!) y clientes más satisfechos.
UN EJEMPLO DE LA VIDA REAL
Un gran departamento de TI tenía como objetivo reducir el tiempo necesario para cerrar tickets de servicio a medida que crecía el trabajo pendiente. Para lograr esto, el líder del equipo buscó identificar los escenarios (es decir, variables) que tuvieron el impacto más significativo en el cierre de tickets. Comprender las causas detrás de la velocidad del cierre de tickets podría revelar la causa raíz del retraso.
Para abordar el problema, el departamento decidió examinar los tickets que se cerraron más rápido para comprender las razones subyacentes. Al aplicar estos conocimientos, podrían acelerar el cierre de otros tickets. Reunieron datos de los últimos diez meses de resolución de tickets y los introdujeron en Minitab Statistical Software, que incluía información sobre los niveles de dotación de personal (es decir, el tamaño del equipo), la cantidad de tareas completadas, encuestas de satisfacción del cliente posteriores a la resolución del ticket y el tamaño del proyecto (medido en una escala del 1 al 5).
LOS RESULTADOS
Tomaron sus datos y los ejecutaron a través del Módulo de analítica predictiva de Minitab para aclarar qué variables tuvieron el impacto más significativo en los resultados. Como no eran científicos de datos, utilizaron el aprendizaje automático automatizado, que está convenientemente ubicado dentro del módulo. Esta herramienta les ayudó a construir un modelo predictivo en cuestión de segundos y les permitió identificar el modelo más preciso a utilizar, identificando de manera efectiva los factores clave en el cierre de tickets. Sin la necesidad de mirar ecuaciones, la observación inicial del equipo se centró en el gráfico de importancia relativa de las variables, que se muestra aquí:
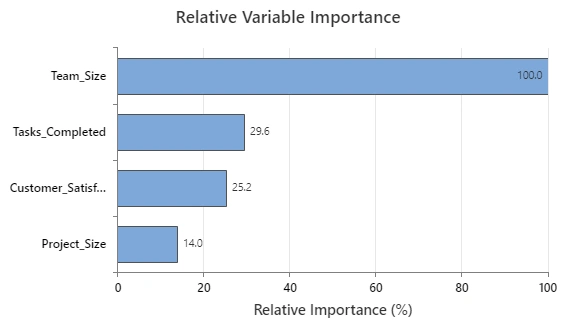
La variable importancia mide la mejora del modelo cuando se realizan divisiones en un predictor. La importancia relativa se define como el % de mejora con respecto al predictor principal.
Estos datos iniciales mostraron que el factor más importante para la velocidad de resolución de tickets es el tamaño del equipo (es decir, el nivel de personal). Curiosamente, las tareas completadas ocuparon un distante segundo lugar, mientras que ni las encuestas de satisfacción del cliente ni el tamaño del proyecto parecieron tener un impacto significativo.
A primera vista, estos datos tenían perfecto sentido para el líder del equipo: cuanto más grande fuera el equipo, más rápido resolvería los problemas.
APROVECHAR EL ANÁLISIS PARA OBTENER CONOCIMIENTOS MÁS PROFUNDOS
Armado con esta información, el equipo ahora tenía motivos suficientes para abogar por personal adicional, pero ¿cuánto? ¡Lo último que querían hacer era contratar a otra persona y no obtener ninguna mejora! Necesitaban entender cómo desplegar sus recursos de manera eficiente y efectiva.
Afortunadamente, la herramienta de aprendizaje automático automatizado de Minitab también equipó al equipo con otro recurso valioso: los gráficos de dependencia parcial de un predictor. Dado que el equipo identificó el tamaño del equipo como el predictor más influyente, podrían dedicar más tiempo a analizar un gráfico de ese factor. Minitab produjo los siguientes resultados:
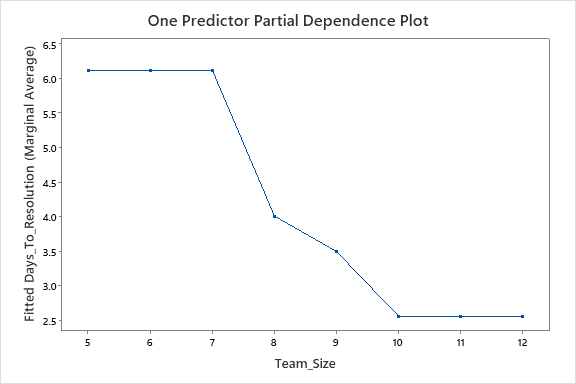
Vemos los resultados promedio de tareas anteriores según el tamaño del equipo. Los datos nos muestran que hay una diferencia significativa en el tiempo que le tomó al equipo resolver problemas en un equipo de siete (aproximadamente 6 días) versus un equipo de diez (aproximadamente 2,5 días), más del doble, de hecho.
Pero los datos también nos muestran que no hay una diferencia aparente entre el tiempo que llevó resolver los tickets en un equipo de diez versus uno de doce. Entonces, en este caso, tiene más sentido dedicar un equipo de diez profesionales de TI a realizar tickets y resolver problemas para lograr la máxima eficiencia. Igualmente importante es que demuestra que, a menos que se haga una inversión sustancial en los niveles de personal, hay poca diferencia entre cinco y siete profesionales, por lo que contratar a un miembro adicional del equipo producirá un impacto mínimo.
Descárguese el artículo "Common Problems Solved by Predictive Analytics", para obtener más información.
PARA LLEVAR
Este resultado es crucial porque, fundamentalmente, ofrece una hoja de ruta para la mejora y una explicación del problema actual. Existe una solución clara para reducir la acumulación de tickets y mejorar rápidamente la satisfacción del cliente.
Además, las visualizaciones generadas cuentan una historia convincente para los tomadores de decisiones de la alta dirección, no solo enfatizando la necesidad de invertir en personal, sino también cuánto personal se necesita para rectificar el problema.
- Detalles
- Categoría: Comsol
- Visto: 724

El grafeno, el material bidimensional de carbono, se encuentra a la vanguardia de la nanotecnología, ofreciendo propiedades que despiertan la innovación en diversas industrias. En el ámbito de la plasmónica, donde la manipulación de la luz a escala nanométrica tiene un inmenso potencial, las características del grafeno toman el protagonismo.
Un reciente estudio innovador, " Hybrid Approach for Graphene Modeling in Numerical Simulations of Graphene-Based Plasmonic Devices with COMSOL" [1], profundiza en metodologías para modelar dispositivos plasmónicos basados en grafeno utilizando las capacidades de COMSOL Multiphysics.
Esta investigación lidera una estrategia de modelado híbrido, amalgamando diversos marcos teóricos dentro del marco de COMSOL. Al sincronizar la mecánica cuántica, los principios electromagnéticos y modelos basados en la física clásica, el estudio tiene como objetivo desentrañar la interacción entre la luz y el grafeno en estos dispositivos.
En su núcleo, este enfoque promete descubrir comportamientos matizados del grafeno dentro de sistemas plasmónicos. Al aprovechar la capacidad de simulación de COMSOL, desbloquea vías para optimizar diseños de dispositivos, impulsando aplicaciones en sensores de alto rendimiento, fotodetectores ultrarrápidos y dispositivos optoelectrónicos.
La integración de COMSOL en esta investigación no solo conecta aspectos teóricos con aplicaciones prácticas, sino que también impulsa el esfuerzo hacia aprovechar de manera más efectiva las capacidades del grafeno. Esto podría impactar en las telecomunicaciones, avanzar en la detección biomédica y mejorar las tecnologías de captación de energía.
La imagen de cabecera procede del modelo "Graphene Metamaterial Perfect Absorber", que se puede encontrar en la Application Gallery de COMSOL.
Referencias
[1] Kum-Dong Kim et al. Hybrid approach for graphete modeling in numerical simulations of graphene based plasmonic devices with COMSOL. AIP Advances 13, 075230 (2023); doi:https://doi.org/10.1063/5.0153032- Detalles
- Categoría: Lakes
- Visto: 904
Anteriormente ya discutimos una limitación fundamental de el sistema de modelado CALPUFF que ponía límites finitos en el número de objetos y cálculos que varios ejecutables del sistema podían manejar en un único proyecto. Un área donde los modeladores pueden encontrar esa limitación es la definición de valores de salidad en el modelo CALPOST para el postprocesado de los resultados del modelo de CALPUFF.
CALPOST se utiliza para extraer las concentraciones mejor clasificadas para compararlas con los estándares de calidad del aire ambiental. En los Estados Unidos, los estándares generalmente se basan en valores clasificados (por ejemplo, 1º más alto, 2º más alto, etc.). Otros países, sin embargo, tienen estándares basados en percentiles (por ejemplo, 99.8, 99, 90, etc.). Dado qeu CALPOST no admite percentiles de forma nativa, el modelador debe calcular primero un valor máximo equivalente. Por ejemplo, si se le pide a un modelador que encuentre el percentil 98 de un promedio de 24 horas durante 1 año de datos modelados:
- 1 año de datos modelados = 365 días
- Promedio de 24 horas = 1 valor de salida por receptor por día
- 98% de 365 = 7,3
- Dado que los valores clasificados deben ser enteros, 7,3 se redondea a 8
Por lo tanto, el percentil 98 de un promedio de 24 horas durante un año se convierte en el octavo valor mejor clasificado cuando se usa CALPOST. ¿Qué pasa si el modelador quiere el percentil 98 para un promedio de 1 hora?
- 1 año de datos modelados = 8.760 horas
- Promedio de 1 hora = 1 valor de salida por receptor por día
- 98% de 8.760 = 175,2
- Dado que los valores clasificados deben ser enteros, 175,2 se redondea a 176
Desafortunadamente, el modelo nativo de CALPOST no puede aceptar un rango máximo superior a 10. Los modeladores podrían recompilar CALPOST para aceptar un rango alto, pero esto requiere un conocimiento práctico de FORTRAN y práctica en la compilación de código. Para resolver este problema, Lakes Environmental desarrolló una utilidad para manejar percentiles directamente en el sistema de modelado CALPUFF: la utilidad Percentiles que se encuentra en el asistente CALPOST Wizard de CALPUFF View.
Esta utilidad omite CALPOST por completo y analiza los datos por hora en los archivos de salida de flujo de deposición y concentración directa de CALPUFF (por ejemplo, CONC.DAT, DFLX.DAT, etc.). Después de calcular los percentiles definidos por el usuario, se crea un conjunto de archivos de gráficos de curvas de nivel para su visualización en CALPUFF View. Siga los pasos a continuación para utilizar esta utilidad.
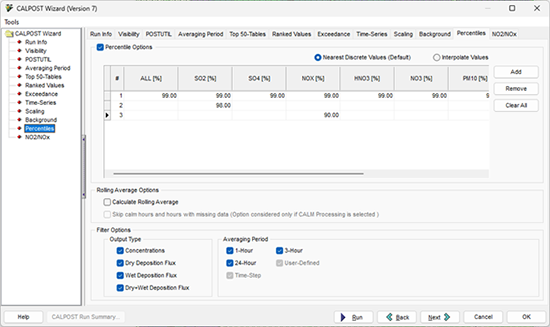
Paso 1: Abra el asistente CASLPOST Wizard y vaya a la pestaña Percentiles.
Paso 2: Active la casilla de verificación  para activar la utilidad.
para activar la utilidad.
Paso 3: Elija si desea generar el valor clasificado más cercano al percentil especificado (Nearest Discrete Values) o si desea que el modelo interpole entre valores clasificados (Interpolate Values). Por ejemplo, el promedio de 1 hora del percentil 98 descrito anteriormente extraería el valor clasificado número 176 si los valores discretos más cercanos están habilitados. La configuración Interpolate Values interpolaría las concentraciones entre los valores clasificados 175 y 176.
Paso 4: Haga clic en el botón  para añadir un nuevo percentil.
para añadir un nuevo percentil.
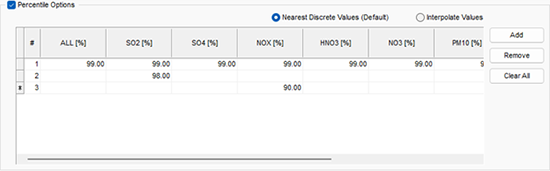
Paso 5: Intoduzca sus percentiles. Utilice la columna ALL para especificar el mismo valor de percentil para cada especie modelada. Para percentiles específicos de la especie, introduzca un valor en la columna de la especie deseada. El siguiente ejemplo produciría una salida del percentil 99 para todas las especies, una producción de percentil 98 solo para SO2 y una salida de percentil 90 para NOX.
Paso 6: Elija el tipo de salida, Output Type, al que desea aplicar los percentiles: Concentration, Dry Deposition, Wet Deposition, y/o Total (Dry+Wet) Deposition.
Paso 7: Seleccione el/los periodo(s) de promediación(es) de interés. Si algún periodo no está disponible, vaya a la pestaña Averaging Period de CALPOST Wizard para habilitar otros períodos deseados.
Paso 8: Una vez que haya especificado su configuración, haga clic en el botón  para generar los archivos de diagrama de percentiles. Estos archivos están disponibles en la carpeta Percentile Plots que se muestra en la pestaña CALPOST de la vista Tree View.
para generar los archivos de diagrama de percentiles. Estos archivos están disponibles en la carpeta Percentile Plots que se muestra en la pestaña CALPOST de la vista Tree View.
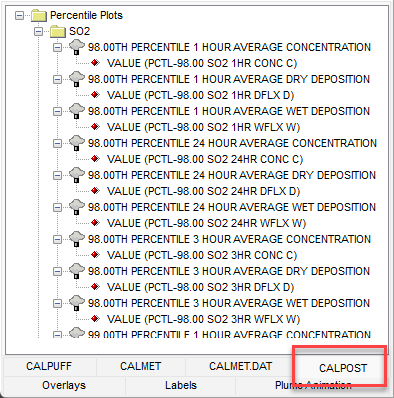
Para ver el archivo de texto de resultados, haga doble clic en el título del archivo de gráfico de percentil/promedio móvil junto al icono  .
.
- Detalles
- Categoría: Minitab
- Visto: 782

Por Josué Zable.
Anteriormente escribí que los especialistas en marketing deben conocer (al menos) un método estadístico básico para realizar correctamente las pruebas A/B. Con suerte, con algunos conocimientos en su haber, dejará de permitir que la ansiedad por las estadísticas le frene en su carrera de marketing y emprenderá una tarea un poco más desafiante: las pruebas A/B/C.
¿QUÉ SON LAS PRUEBAS A/B/C?
Las pruebas A/B/C, al igual que las pruebas A/B, son una forma de experimento controlado. En el caso de A/B/C, está probando más de dos versiones (por lo tanto, agrega la “C” a A/B) de una variable (página web, elemento de página, correo electrónico, etc.). Esto se puede usar para comparar 3 o más versiones de algo para determinar qué versión funciona mejor, como enviar varios correos electrónicos para ver cuál genera más participación o usar diferentes anuncios para medir las tasas de clics. Un caso de uso común es desafiar un grupo estándar o de control contra múltiples variantes. Por ejemplo, probar una página web actual con dos diseños de página web alternativos para ver qué diseño genera más conversiones, el original o los dos rivales.
Como escribimos antes, hay muchas pruebas diferentes que puedes ejecutar, incluidas herramientas que prueban múltiples componentes al mismo tiempo. Hoy veremos una prueba A/B/C simple, comparando tres versiones en una sola medición. Podrían ser tasas de apertura o tasas de clics en correos electrónicos, anuncios o páginas web.
INTRODUCCIÓN A LA REGRESIÓN LOGÍSTICA BINARIA
El análisis de regresión logística binaria se utiliza para describir la relación entre un conjunto de predictores y una respuesta binaria. Una respuesta binaria tiene dos resultados, como aprobado o reprobado. En marketing, esto a menudo se traduce en clics, aperturas o conversiones. Cuando solo se comparan dos enfoques, existen métodos más simples, como la prueba de dos proporciones.
UN EJEMPLO DE PRUEBA A/B/C
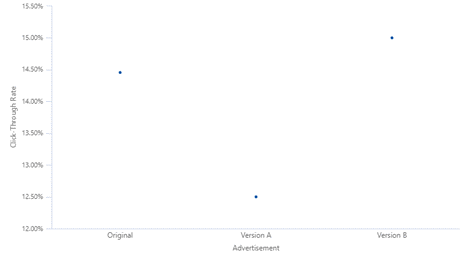
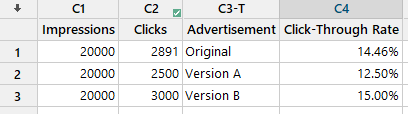
Imagine que un especialista en marketing ejecuta una campaña publicitaria periódica en las redes sociales para atraer visitantes a su sitio web. Deciden ejecutar una prueba A/B/C con diferentes versiones del anuncio para ver qué anuncio generará más clics. Apuntan a 20.000 impresiones para cada anuncio y realizan su prueba. Recopilan sus resultados y los grafican. Según el gráfico de valores individuales, está claro que la Versión A tuvo un peor desempeño que la Original y la Versión B. La pregunta sigue siendo: ¿son las diferencias estadísticamente significativas para alejarse del original?
REGRESIÓN LOGÍSTICA BINARIA PARA ANALIZAR LA PRUEBA
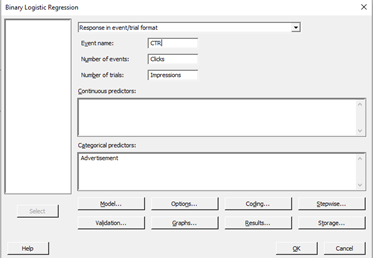
Con los datos recopilados, puedo usar Minitab para ajustar un modelo de regresión logística binaria.
Al ir a Estadísticas > Regresión > Regresión logística binaria > Ajustar modelo logístico binario, Minitab presenta una ventana de diálogo para que seleccione “Respuesta en formato de evento/ensayo” y complete mis eventos (clics) y ensayos (impresiones). ¡También selecciono Publicidad como elemento que estoy probando y dejo que Minitab cree mi modelo!
CONCLUSIONES DEL ANÁLISIS DE LOS RESULTADOS
Ahora necesitamos profundizar un poco en las estadísticas (¡no mucho, solo un poco! Estás aquí para aprender algo, ¿no?). Mirando la tabla a continuación, vemos el Odds Ratio que compara las probabilidades de dos eventos, en nuestro caso haciendo clic en los diferentes anuncios. Minitab configura la comparación enumerando los niveles en 2 columnas, Nivel A y Nivel B. El nivel B es el nivel de referencia para el factor. Los índices de probabilidad superiores a 1 indican que el evento, en nuestro caso los clics, es más probable en el nivel A. Los índices de probabilidad inferiores a 1 indican que es menos probable que se produzca un clic en el nivel A.
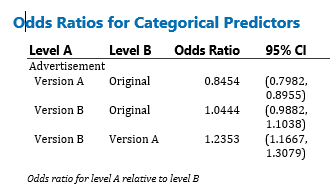
Con respecto a nuestra tabla, al comparar la Versión A con la Original, un Odds Ratio inferior a 1 significa que es menos probable que se produzca un clic en la Versión A. Al seguir la tabla, vemos que es más probable que la Versión B obtenga un clic que la Versión B. tanto el original como la Versión A. Esto valida lo que graficamos y comparamos, pero ¿dónde está la información adicional?
Al observar la segunda columna, Intervalo de confianza del 95 %, obtenemos información adicional sobre nuestros datos. En este tipo de análisis, los intervalos de confianza que contienen 1 dentro de su rango (como la versión B frente a la original, donde el IC del 95 % es 0,9882,1,1038) indican que las probabilidades de hacer clic o no hacer clic son esencialmente las mismas para los dos grupos.
Como resultado, esta prueba nos ha enseñado que, sin lugar a dudas, la Versión A es el anuncio con peor rendimiento y no vale la pena conservarlo. Sin embargo, sería un error sustituir automáticamente la versión B por la original. Nuestros próximos pasos deberían ser a) refinar nuestra prueba a una prueba A/B comparando el Original con la Versión B o b) seleccionar el Original o la Versión B por razones cualitativas como "seguir con nuestro mensaje consistente" o "actualizar nuestro mensaje". sin preocuparse por comprometer los resultados.