- Detalles
- Categoría: Noticias
- Visto: 1369

Grafiti acaba de comunicar la discontinuidad de sus productos AISN: TableCurve 2D, TableCurve 3D y PeakFit.
Los usuarios con licencias actualizadas seguirán disponiendo de su servicio de soporte. El fin del servicio de soporte definitivo de estos productos será el próximo 31 de marzo de 2026.
Consulte con nuestro departamento comercial si quiere encontrar alternativa a esa línea de productos para solucionar sus problemas matemáticos y gráficos.
- Detalles
- Categoría: Lakes
- Visto: 2277

Con la reciente publicación de la Guideline on Air Quality Models (Apéndice W del Título 40 del Código de Regulaciones Federales, Parte 51), la EPA de EE.UU. incorporó los algoritmos del Experimento de Respuesta Acoplada Océano-Atmósfera (Coupled Ocean-Atmosphere Response Experiment o, en adelante COARE) a AERMET. La incorporación de COARE permite a AERMET calcular sin problemas las condiciones de la capa límite para entornos marinos sobre el agua, y la promulgación de COARE como opción de modelo regulatoria por defecto elimina la necesidad de demostraciones de modelos alternativos.
En AERMET View V13.0, los usuarios pueden invocar los algoritmos COARE a través de las entradas de Sectors:
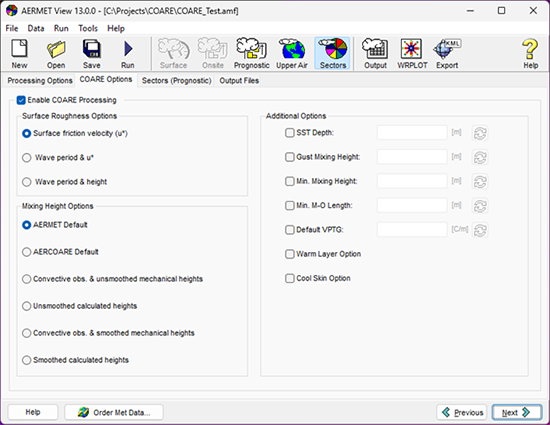
Opciones de COARE en AERMET View V13.0
Las entradas de COARE constan de tres selecciones principales: Rugosidad de la superficie (Surface Roughness), Altura de mezcla (Mixing Height) y Opciones adicionales (Additional Options).
Rugosidad de la superficie
Esta opción es obligatoria para procesar COARE. La opción predeterminada, Velocidad de fricción superficial (Surface friction velocity, u*), se considera la opción predeterminada. Las opciones alternativas utilizan mediciones directas de oleaje o las calculan basándose en relaciones para un estado del mar bien desarrollado.
Altura de mezcla
Los modeladores deben seleccionar una de las seis opciones para calcular las alturas de mezcla. La Guía del Usuario AERMET de la EPA de EE.UU. ofrece descripciones completas de estos métodos (véase la Sección 3.7.7.6 ).
Opciones adicionales
Las demás selecciones de COARE son opcionales y deben basarse en las características de los datos de entrada. Estas incluyen:
- Definición de la profundidad precisa de las mediciones de temperatura de la superficie del mar
- Anulación de la altura de mezcla predeterminada para los cálculos de ráfagas de viento
- Establecimiento de valores mínimos permitidos para la altura de mezcla y la escala de longitud Monin-Obukhov
- Modificar el gradiente de temperatura potencial vertical predeterminado
- Invocar las opciones de capa cálida o piel fría
- Se recomienda a los modeladores que revisen las pautas actuales de la EPA de EE.UU. sobre el uso de estas opciones, ya que algunas no se recomiendan explícitamente para aplicaciones regulatorias.
Hay más información sobre las pruebas y la evaluación de COARE disponible en el sitio web de la EPA de EE.UU.: https://www.epa.gov/scram/2024-appendix-w-final-rule.
- Detalles
- Categoría: Minitab
- Visto: 1490
Por Oliver Franz.
Necesita respuestas, pero sus datos no son claros.
Quizás esté extrayendo informes de tres plataformas diferentes, intentando conciliar cifras que no coinciden del todo. Quizás esté copiando y pegando manualmente datos de varias hojas de cálculo, con la esperanza de no haber cometido ningún error. O quizás esté esperando a que el departamento de TI limpie, prepare los datos y fusione los conjuntos de datos antes de poder siquiera empezar a analizar tendencias.
Si esto le suena familiar, no está solo. Para muchas organizaciones, el mayor desafío con los datos no es la falta de información, sino el enorme esfuerzo que requiere recopilarla. Y ese esfuerzo le está costando más de lo que cree.
Los costes ocultos de la compilación manual de datos
Los datos erróneos no siempre implican cifras incorrectas. A veces, el problema radica simplemente en cómo se recopilan, almacenan y combinan los datos. Cuando los equipos dependen de la agregación y conciliación manual, esto conlleva:
- Tiempo perdido: los analistas, los equipos financieros y los gerentes de operaciones pasan horas extrayendo datos de diferentes fuentes, corrigiendo inconsistencias de formato y verificando la precisión en lugar de analizar información.
- Informes inconsistentes: Si los departamentos de ventas, marketing y finanzas presentan cada uno su propia versión de los ingresos del último trimestre, es probable que obtengan cifras ligeramente diferentes. Sin una única fuente de información veraz, la toma de decisiones se convierte en un juego de adivinanzas.
- Decisiones retrasadas: cuando se finaliza un informe compilado manualmente, es posible que los datos ya estén desactualizados, lo que lleva a tomar decisiones basadas en la realidad de ayer en lugar de las tendencias de hoy.
- Mayor riesgo de errores: cuantas más manos pase un conjunto de datos, mayor será la probabilidad de que aparezcan entradas duplicadas, valores faltantes o formatos desalineados.
Por qué la agregación de datos tradicional no funciona
La mayoría de las organizaciones utilizan una combinación de herramientas, como Excel, bases de datos, plataformas en la nube y software específico del sector, cada una de las cuales almacena datos en diferentes formatos. Reunir todos esos datos suele ser un desafío, ya que requiere exportar y reformatear archivos CSV, lo que puede generar errores y problemas de control de versiones. Muchos equipos recurren a copiar y pegar manualmente entre hojas de cálculo, un proceso lento y propenso a errores. Otros crean scripts personalizados o confían en el departamento de TI para preparar los datos y fusionar los conjuntos de datos, lo que ralentiza el análisis y crea cuellos de botella.
Estos métodos no solo desperdician tiempo, sino que también generan más oportunidades de error. Y cuando el liderazgo toma decisiones estratégicas basándose en esos datos, incluso una pequeña discrepancia puede tener grandes consecuencias.
Un enfoque más inteligente para la preparación de datos y la preparación automatizada de datos
Solucionar estos problemas no requiere un equipo más grande ni más horas, sino un mejor sistema de preparación e integración de datos. Los mejores equipos basados en datos siguen estos pasos clave:
1. Automatizar la agregación de datos
En lugar de extraer manualmente informes de varias plataformas, conecte sus fuentes de datos directamente. La integración automatizada garantiza que sus conjuntos de datos estén siempre actualizados y alineados sin esfuerzo manual.
2. Estandarizar el formato y la estructura
Las distintas plataformas almacenan datos de distintas maneras. Un sistema puede rastrear a los clientes por nombre, otro por número de identificación. Las fechas, las monedas y las categorías pueden tener formatos distintos. Establecer estructuras de datos consistentes previene las discrepancias antes de que ocurran.
3. Validar y limpiar datos en tiempo real
La conciliación manual implica que los errores suelen pasar desapercibidos hasta que es demasiado tarde. Al automatizar las comprobaciones de validación, como marcar registros duplicados o formatos incorrectos en el punto de entrada, se garantizan datos más limpios desde el principio.
4. Optimice los informes con una única fuente de información
Cuando todos los equipos trabajan con el mismo conjunto de datos, actualizado automáticamente, los informes se vuelven más rápidos, fiables y prácticos. En lugar de dedicar horas a verificar cifras, los equipos pueden centrarse en el análisis y la estrategia.
Del caos de datos a la confianza en los datos
Iniciar sesión en un panel que extrae automáticamente datos limpios y actualizados de todas tus fuentes hace que todo sea más eficiente. Sin esperas del departamento de TI, sin conciliaciones manuales, sin dudas.
Esa es la diferencia entre esforzarse por corregir datos desordenados y realmente anticiparse. Cuando la preparación de datos se automatiza y optimiza, los equipos avanzan con mayor rapidez, las decisiones se agilizan y las empresas crecen con confianza.
Los datos erróneos son un lastre. Las empresas que controlan sus datos son las que se mantienen a la vanguardia.
- Detalles
- Categoría: Comsol
- Visto: 2046
En este artículo presentamos una estrategia para minimizar el tiempo de simulación en COMSOL Multiphysics® cuando abordamos simulaciones con varias físicas acopladas, y consiste dividir el problema en varias etapas en lugar de resolverlo todo de una vez.
¿Cómo?
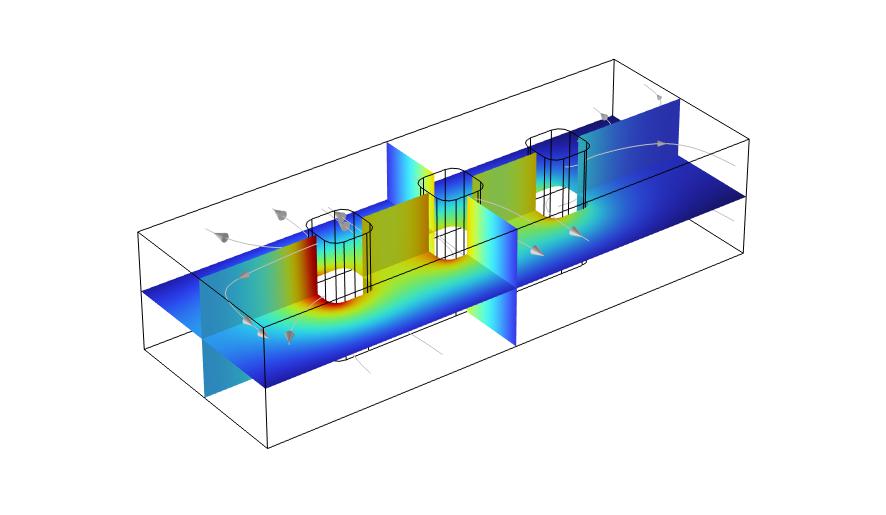
Veamos cómo a través del siguiente ejemplo basado en “wire electrode” cuya geometría se muestra en la Figura 1, y que combina las físicas de configuración de corrientes de tipo terciario, flujo laminar y transporte de especies diluidas.
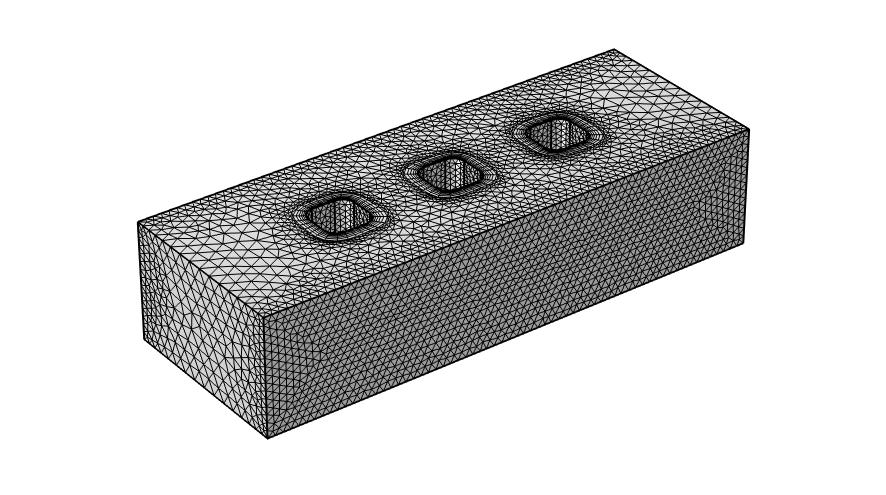
Figura 1. Geometría tridimensional y mallado utilizado en el modelo “wire electrode” en COMSOL Multiphysics®.
Sin realizar ninguna modificación, el estudio en estado estacionario se realiza según la configuración por defecto que se muestra en la Figura 2 (a): se utiliza un resolvedor de tipo segregado, directo para resolver la física de flujo laminar y una configuración de tipo segregado e iterativa para el resto de las físicas. Para reducir los tiempos de simulación, la estrategia consiste en dividir la simulación en dos etapas (Figura 2 (b)):
- Etapa 1: se resuelve la física de flujo laminar, que no depende de las otras.
- Etapa 2: se resuelven el resto de las físicas utilizando la solución previamente calculada para la física de flujo laminar.
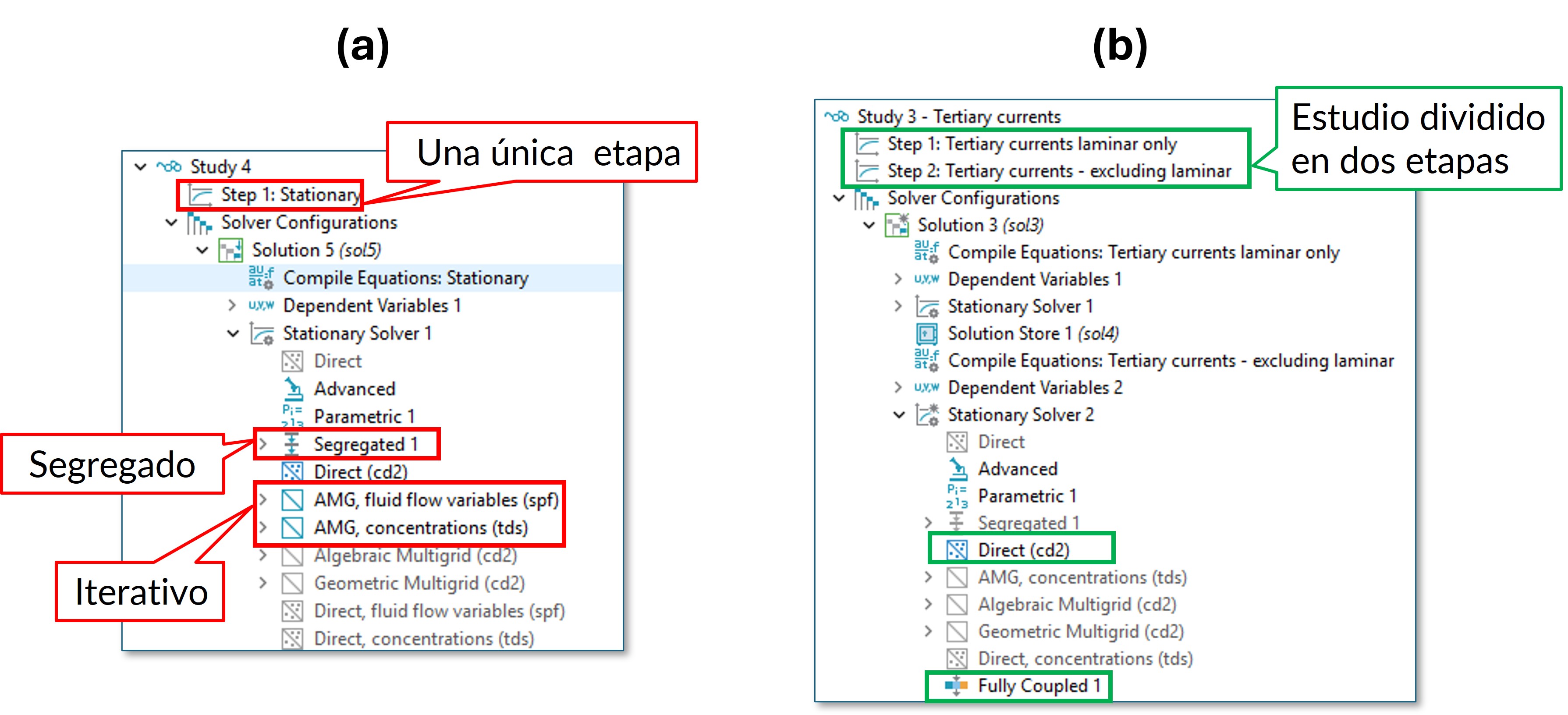
Configuración del resolvedor y tiempo requerido para completar la simulación: (a) por defecto, (b) modificada.
Además, se puede configurar el solver tal y como se muestra en la Figura 2 (b), es decir, utilizando un enfoque de físicas completamente acopladas y de resolución directa.
Tras completar la simulaciones (utilizando un equipo con procesador Intel(R) Core(TM) i7-14700 2.10 GHz y 16.0 GB de memoria RAM), la Figura 3 compara el tiempo requerido para completar la simulación. De acuerdo con los resultados obtenidos, aunque el proceso alternativo por etapas requiere de mayor uso de memoria RAM, ¡el tiempo de simulación se reduce de 3 horas y 45 minutos (configuración de estudio en una etapa y resolvedor por defecto) hasta 4 minutos, obteniéndose la misma curva de polarización tal y como se muestra en la Figura 3!
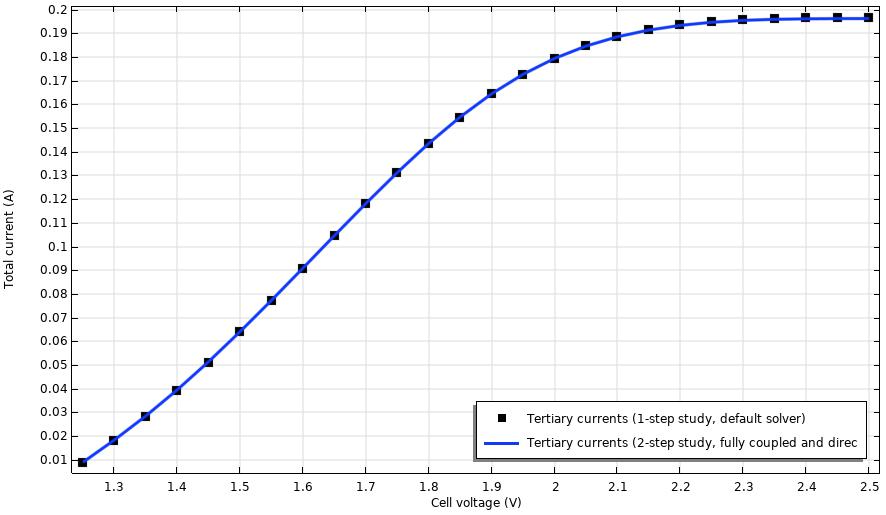
Figura 3. Curvas de polarización obtenidas mediante la simulación en COMSOL Multiphysics® utilizando distintas configuraciones de estudio y resolvedor.
Esperamos que este truco sea de utilidad para tus próximas simulaciones numéricas en COMSOL Multiphysics®.
- Detalles
- Categoría: Minitab
- Visto: 1937
Hoy quiero hablarte sobre la importancia de mejorar tu estrategia experimental para obtener DATOS de calidad. Esto permitirá que Minitab te proporcione un análisis fiable, facilitando una toma de decisiones más acertada. Al final del artículo, también comparto algunas malas prácticas comunes para que puedas evitarlas.
✔No confundamos análisis con plan de pruebas que es donde tú puedes aportar valor.
¿CÓMO DEMOSTRAR QUE ALGO FUNCIONA?
Las experiencias de “experimentar” siempre van acompañadas de la pregunta ¿Funciona? Por ello me viene a la mente el popular producto orientado a bajar el colesterol. Te has preguntado alguna vez, ¿qué evidencias esperas encontrar en los estudios científicos que avalan el éxito del producto para decidir incorporarlo a tu cesta de la compra convencida de que merece la pena el gasto? Y si quieres hacer previamente tú misma un estudio, ¿cómo lo harías teniendo en cuenta las evidencias que necesitas?
En todo estudio hay dos componentes:
- Diseño de experimentos
- Análisis de resultados
Siempre, hemos de entender cómo explotaremos los resultados analíticos que nos dará un software, para aportar valor en nuestro trabajo, diseñando las pruebas y recogida de datos con metodología propia de la Ingeniería Estadística.
CASO DE ESTUDIO: REDUCCIÓN DEL COLESTEROL
Vamos a abordar esta cuestión comenzando por el final, el análisis, con un caso simple y ficticio que persigue reducir el colesterol.
Imaginemos que tenemos datos sobre los niveles de colesterol de personas que SÍ han tomado y que NO han tomado el tratamiento. Este es un diseño de experimentos con un factor y dos tratamientos independientes. ¿Qué aporta el tener 10 o 50 personas participando en cada grupo?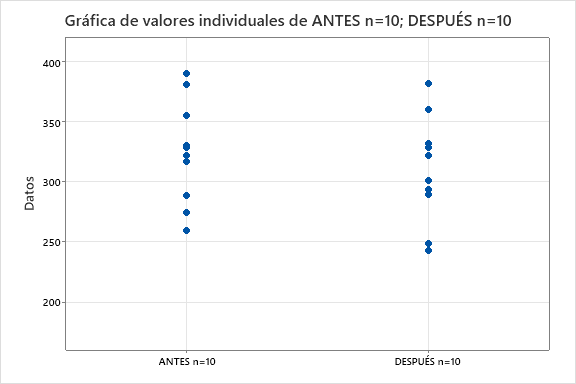
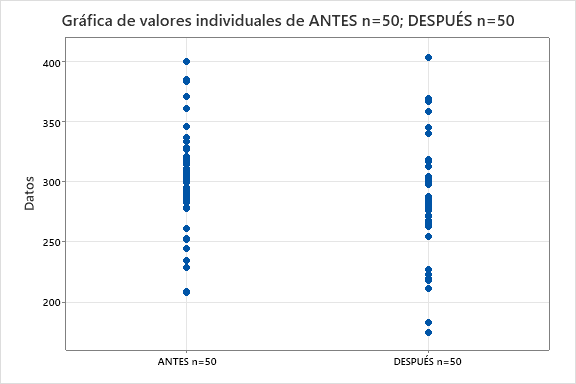
Para estudiar la diferencia entre dos tratamientos haremos uso de Intervalos de Confianza (IC):
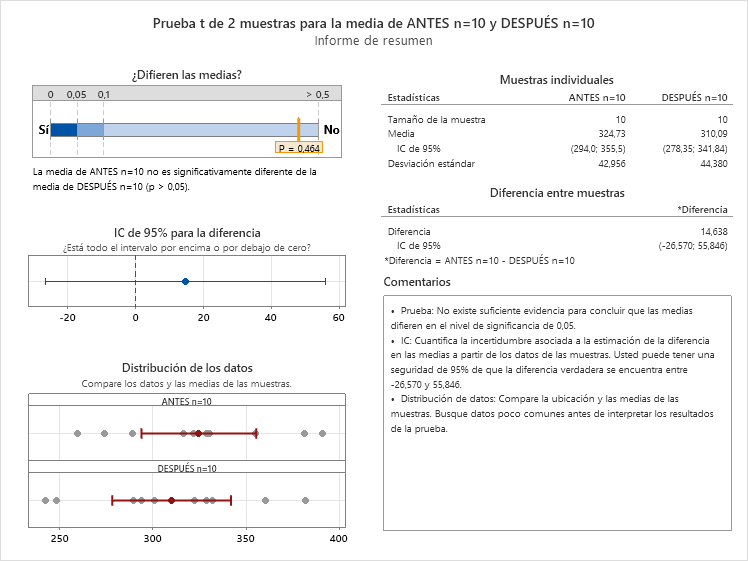
- n=10. La diferencia obtenida es de mejora en 14,6 puntos, pero no es evidente que esa diferencia sea por el tratamiento. La horquilla (-27, 56) indica que ese resultado también se podría haber obtenido si el tratamiento empeorara en 27 puntos o si lo mejorara en 56 puntos, situaciones muy diferentes, luego n=10 aporta muy poco conocimiento.
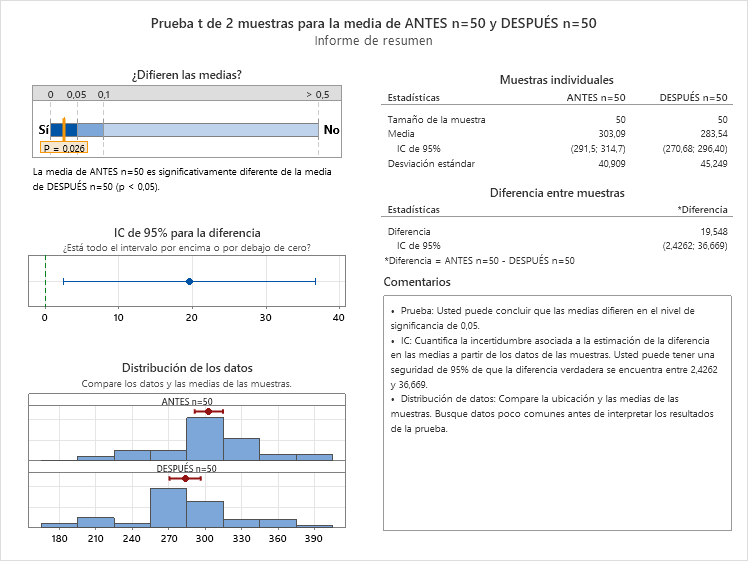
- n=50. En este caso podemos asegurar con 95% de confianza que el tratamiento mejora entre 2 y 37 puntos.
Con n=50 detectamos un efecto que con n=10 también está, pero que no lo podemos ver con evidencia. El hecho de tener individuos con tanta variabilidad dificulta la detección del efecto. En este caso, el tamaño de muestra afecta a la potencia de detectar evidencia del efecto del tratamiento. Estamos en manos de la “suerte” de obtener dos muestras que evidencien la diferencia.
✔Para reducir la variabilidad y obtener resultados más precisos, aumentar el tamaño de la muestra es una estrategia efectiva.
ALTERNATIVA: DISEÑO DE EXPERIMENTOS APAREADO
En este caso, es posible utilizar una contramedida mejor para atacar la variabilidad entre individuos, que es cambiar el tipo de diseño experimental y que sea la misma persona la que se utiliza para medir el colesterol antes y después del tratamiento. La consecuencia de poder obtener el incremento de colesterol para cada persona es que el diseño de partida necesita muchas menos personas en el estudio.
Tanto la manera de “mirar los datos” como la manera de analizarlos es diferente, ya que es un diseño de experimentos apareado.
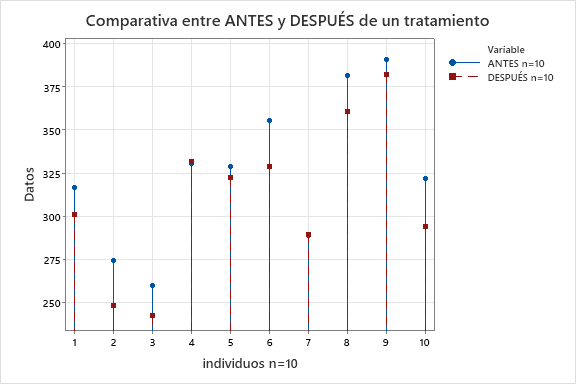
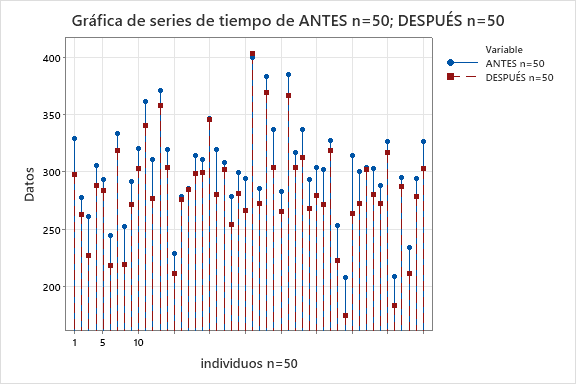
Y, realizando una prueba de hipótesis t pareada:
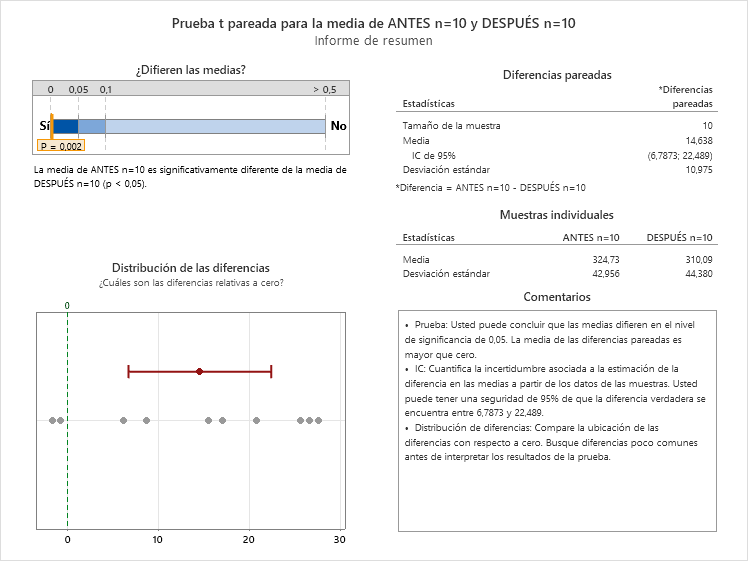
- n=10. La diferencia obtenida de mejora en 14,6 puntos muestra una evidencia de que el tratamiento afecta. Además, estimamos con un 95% de confianza de que el efecto, aunque nos haya salido 14,6 en la muestra, en realidad está en la horquilla (7 y 22).
LA IMPORTANCIA DEL DISEÑO EXPERIMENTAL
Si comprendemos los diferentes tipos de diseño y su interpretación, podemos delegar el análisis en Minitab, que proporciona herramientas intuitivas y amigables para este proceso.
Llegados a este punto, ¿cuál es nuestro rol? La respuesta es “lograr experimentar de manera eficiente, con el mínimo de pruebas y logrando datos de calidad, fiables”. Por ello, tenemos que aportar valor en:
- Seleccionar el tipo de diseño experimental adecuado a cada situación.
- Determinar el tamaño de muestra de las réplicas para cada tratamiento.
- Organizar las pruebas experimentales para minimizar factores externos que puedan afectar los resultados, de modo que “lo único que cambie sea el tratamiento de estudio”.
Minitab también ayuda a determinar el tamaño de muestra adecuado. Bien desde el propio Minitab o bien desde el asistente proporcionado por el módulo del tamaño de la muestra, podemos determinar cuántos individuos son necesarios para llevar a cabo la comparación de 2 tratamientos.
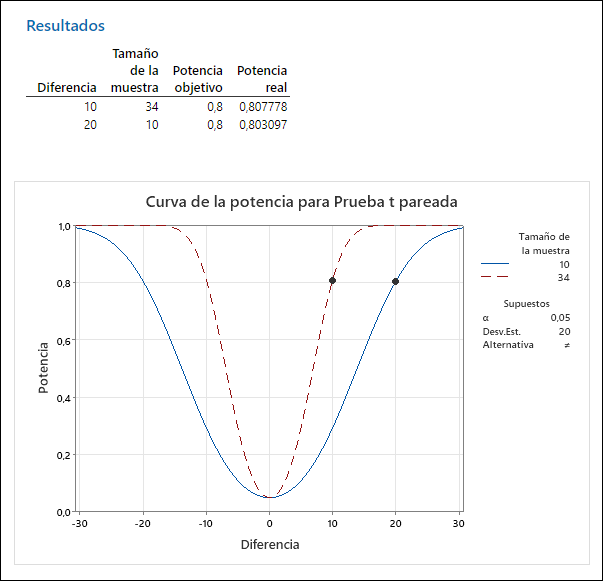
- Si utilizo un diseño apareado de comparación de 2 muestras con n=10 personas midiendo antes-después se logra una potencia de 80% de detectar cambios de 20 puntos o más, y si se deseara detectar cambios más pequeños de 10 puntos haría falta en torno a n=34 personas.
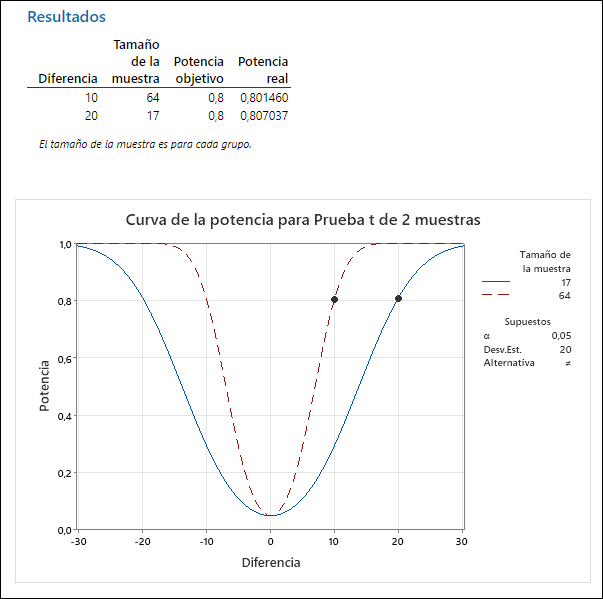
- Si el diseño no es apareado, en la misma situación de variabilidad, los recursos necesarios cambiarían notablemente (17 personas en cada grupo en el primer caso, luego 34, y 64 en el segundo).
ERRORES COMUNES EN EL DISEÑO EXPERIMENTAL
Un error frecuente es asumir que porque MINITAB puede analizar datos con una estructura determinada, el resultado será fiable.
Por ejemplo, si buscamos personas que ya toman Danacol y comparamos su colesterol actual con registros médicos previos, podría parecer un diseño apareado, pero no lo es. Factores como dieta y ejercicio también pueden influir, generando confusión en los resultados.
De hecho, si leemos la letra pequeña del anuncio del producto da qué pensar...
“Según estudios científicos, Danacol, como complemento a un estilo de vida saludable, reduce tu colesterol alto entre un 7 y un 10% en tan solo 2-3 semanas”
CONCLUSIÓN
Si nos dotamos de la habilidad de manejar un software como Minitab para chequear evidencias de un experimento, y comprendemos el efecto de variabilidad y tamaño de muestra en el poder de detección de efectos, seremos precavidos y eficientes incorporando este conocimiento a la táctica experimental.
Recuerda: una buena estrategia experimental es clave para obtener datos confiables y tomar decisiones fundamentadas.
¿QUIERES APLICAR ESTAS HERRAMIENTAS A TUS DATOS?
Si adquirimos la habilidad de diseñar experimentos adecuados y utilizamos Minitab para analizar los datos correctamente, podremos tomar decisiones informadas basadas en evidencia sólida.
En nuestro curso de Diseño y análisis de experimentos con Minitab (I) desarrollamos habilidades para lograr experimentar de manera eficiente, con el mínimo de pruebas y logrando datos de calidad.
Si desea recibir una propuesta formal del coste del curso en su caso particular, póngase en contacto con nuestro departamento comercial por teléfono (934154904 o 915158276) o a través de este FORMULARIO
- Detalles
- Categoría: NAG
- Visto: 1832

NUEVA PERSPECTIVA
Dominar las compensaciones: Equilibrar los objetivos contrapuestos con la optimización multiobjetivo
¿Tiene dificultades para equilibrar objetivos contrapuestos en sus modelos? La optimización multiobjetivo (MOO) le ayuda a encontrar las mejores compensaciones, ya sea que esté optimizando el costo frente al rendimiento, la velocidad frente a la precisión u otros objetivos conflictivos. Nuestros últimos análisis analizan cómo MOO puede acelerar la toma de decisiones y ayudarle a abordar problemas complejos con confianza. Explore aplicaciones y técnicas del mundo real para encontrar el equilibrio óptimo en su trabajo.
- Detalles
- Categoría: ChemOffice
- Visto: 1765
En un importante paso hacia la innovación en herramientas científicas, los reconocidos productos ChemDraw y ChemOffice han evolucionado bajo la firma de revvity para originar Signals ChemDraw, una plataforma que redefine la experiencia en el dibujo y análisis químico. Esto ha llevado a la desaparición de ChemOffice de la cartera de productos de revvity.
Signals ChemDraw mantiene la esencia de ChemDraw, el estándar de la industria en la creación de estructuras químicas, y la complementa con capacidades avanzadas de gestión de datos e integración con otras herramientas científicas. Este cambio responde a la creciente necesidad de laboratorios y empresas de contar con soluciones más eficientes y conectadas en el ecosistema digital.
Con Signals ChemDraw, los usuarios podrán disfrutar de una experiencia optimizada, con mejoras en la colaboración, almacenamiento en la nube y compatibilidad con plataformas de análisis de datos. Además, la integración con Signals Notebook facilita el flujo de trabajo, permitiendo a los investigadores registrar, compartir y analizar sus hallazgos de manera más intuitiva y productiva.
Esta evolución refuerza el compromiso de revvity con la innovación, asegurando que científicos, investigadores y docentes dispongan de herramientas de vanguardia para acelerar sus descubrimientos. Con Signals ChemDraw, el futuro del diseño químico y la gestión de datos científicos entra en una nueva era.
A partir de ahora encontrará las noticias de ChemDraw bajo la sección de Signals ChemDraw.