- Detalles
- Categoría: Lakes
- Visto: 5714
El pasado 1 de octubre, se publicaron nuevos ejecutables para el sistema de modelado de la versión 7 de CALPUFF en el sitio web del Sistema de Modelado CALPUFF. Las actualizaciones incorporan un nuevo tipo de fuente de irrigación agrícola en CALPUFF así como correcciones para varios errores. Las versiones de ejecutables actualizadas quedan como sigue:
- CALPUFF versión 7.3.1
- CALPOST versión 7.3.0
- CALSUM versión 7.2.0
- POSTUTIL versión 7.2.0
Mientras preparan los nuevos ejecutables para incorporarlos en CALPUFF View, los desarrolladores de Lakes Environmental han encontrado algunos problemas de compilación que impiden que los ejecutables actualizados puedan ser utilizados debido a límites muy restrictivos de varios objetos del modelo. Se ha informado a los desarrolladores del modelo de estos problemas para su corrección.
Mientras que los desarrolladores de CALPUFF corrigen estos problemas identificados, Lakes Environmental planea distribuir una actualización de CALPUFF View a finales de este mes.
Mientras esperamos a las actualizaciones de los modelos y procesadores de la versión 7, los usuarios actuales de CALPUFF View todavía pueden descargarse los ejecutables distribuidos previamente. Para facilitar ésto, hemos actualizado las Instrucciones de Descarga del Modelo CALPUFF. Los usuarios con servicio de mantenimiento actualizado pueden acceder a estas instrucciones desde la página web de Actualizaciones del software CALPUFF View.
- Detalles
- Categoría: NAG
- Visto: 6231

El compilador Fortran de NAG es una implementación estándar completa del lenguaje ISO Fortran 2003 con la adición de la mayor parte de Fortran 2008, partes importantes de Fortran 2018 y todo OpenMP 3.1. Su desarrollo se basa en el compilador NAGWare f90, que fue el primer compilador Fortran 90 del mundo. Al igual que su predecesor, el compilador Fortran de NAG ha sido probado y utilizado ampliamente desde su lanzamiento en 1997.
Además, algunas extensiones comunes de Fortran 77 pueden proporcionar soporte para código heredado. Por ejemplo, el compilador Fortran de NAG permite el procesamiento de código que contiene entrada de formato de tabulación, declaraciones del tamaño de byte (por ejemplo, INTEGER * 2) y COMPLEJO DOBLE.
El compilador da amplios mensajes de error, tanto los requeridos por el estándar ISO como la información adicional de compilación y tiempo de ejecución. Los mensajes son informativos en lugar de crípticos y generalmente contienen información de contexto para ayudar a identificar y rectificar problemas. Por esta razón, el compilador es particularmente adecuado para la enseñanza y para los programadores que desean actualizar sus habilidades al nuevo idioma. Los programadores que deseen producir código portátil que cumpla con los estándares se beneficiarán del análisis realizado por el Compilador.
El compilador Fortran de NAG presenta muchas comprobaciones de tiempo de ejecución opcionales, que incluyen: límites de matriz, asociación de puntero, referencias de puntero, referencias de procedimiento, punteros colgantes y variables indefinidas. También hay facilidades para rastrear la asignación de memoria y desasignación y ayudar a identificar pérdidas de memoria.
Los mensajes de error en tiempo de compilación pueden estar codificados por colores para resaltar los errores graves. Se proporciona una opción para generar un rastreo que muestra la pila de llamadas si se produce un error en tiempo de ejecución.
Los módulos integrados proporcionan una interfaz para una gran cantidad de llamadas al sistema Posix, por ejemplo, SYSTEM, y muchas otras.
La recolección automática de basura está disponible como una opción. Esto evita pérdidas de memoria al desasignar la memoria a la que el programa ya no puede acceder.
Además, el compilador proporciona herramientas de software para: convertir código de formato fijo a formato libre; código de impresión bonito ("polaco"); enumerar información de dependencia de módulos e incluir archivos; producir gráficos de llamada; y generar interfaces de procedimientos explícitos como módulos o archivos INCLUDE.
Entre las mejoras más recientes inluidas en la última versión destacan:
- Ejecución paralela de programas coarray en máquinas de memoria compartida;
- Punto flotante de media precisión conforme al estándar aritmético IEEE, que incluye soporte completo para todas las excepciones y modos de redondeo;
- Submodules, una característica de Fortran 2008 para dividir módulos grandes en archivos compilables por separado;
- Teams, una función de coarray de Fortran 2018 para estructurar la ejecución paralela;
- Events, una función de coarray de Fortran 2018 para una sincronización ligera de un solo lado;
- Operaciones atómicas, una función de coarray de Fortran 2018 para actualizar variables atómicas sin sincronización.
Si está interesado en el compilador, consulte a nuestro departamento comercial.
- Detalles
- Categoría: Comsol
- Visto: 8560
El controlador PID es una extensión del controlador on-off y se considera suficiente para la mayoría de problemas de control, hasta el punto que más del 95% de los lazos de control utilizan el PID. Tal es la utilidad de este tipo de controlador que ha sido capaz de superar a cambios tecnológicos tan importantes como la aparición del microprocesador, la autosintonía o la planificación de la ganancia y es utilizado ampliamente en el control de procesos industriales.
Entre sus funciones más importantes podemos destacar que utiliza la realimentación para rechazar las perturbaciones, elimina el error estacionario con la acción integral y puede anticipar el futuro gracias a la acción derivativa.
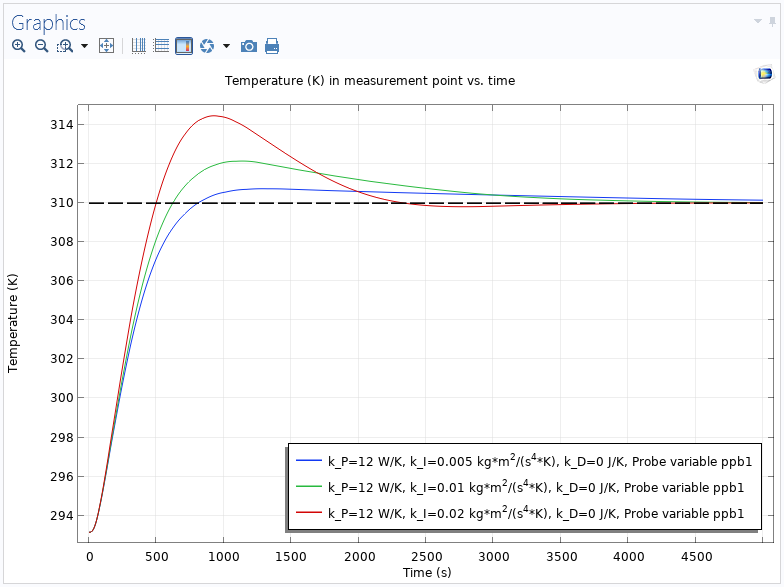
Pese a su popularidad su ajuste para conseguir los mayores beneficios sobre el proceso no es trivial. Para ello consta de tres parámetros de control combinando las tres acciones: Proporciona (P), Integral (I) y Derivativa (D).
Desde la versión 5.5 de COMSOL Multiphysics es posible incluir fácilmente un controlador PID en las simulaciones a través del complemento Controlador PID. Este complemento implementa un controlador PID con funcionalidad adicional, como anti-erolle del integrador ("integral anti-windup") y filtrado de la parte derivativa.
Magnus Ringh nos describe cómo utilizar el controlador PID en COMSOL Multiphysics y muestra su funcionamiento con dos ejemplos de simulación en la entrada del blog de COMSOL titulada "How to Simulate Control Systems Using the PID Controller Add-In".
- Detalles
- Categoría: Signals Notebook
- Visto: 23954
Enero 2020
Mejoras en la usabilidad
Se han realizado algunos cambios que reducen la posibilidad de que los valores calculados en la tabla de estequiometría se muestren en notación científica. Se mostraban en notación científica los valores calculados cuando tenían ceros finales y podía traer problemas en cuanto a la precisión. Por ello, se han ajustado las unidades de los valores calculados para eliminar los ceros finales respetando la precisión de los valores ingresados. También se ha aumentado la precisión de los valores de densidad de los productos químicos almacenados.
Los productos químicos almacenados también se agregarán usando sus apodos cuando se abrevie el nombre. El apodo siempre se puede expandir desde su etiqueta a la estructura completa en la ventana de ChemDraw.
Se ha agregado un campo adicional llamado "conversión a la tabla productos". Este campo está en unidades de porcentaje y está oculto de forma predeterminada.
También se han agregado accesos directos para superíndice y subíndice en el editor de texto.
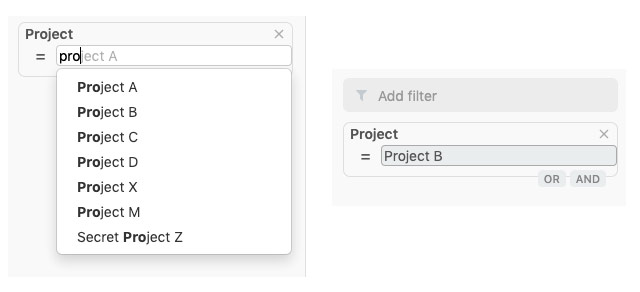
Se ha agregado una opción OR a los filtros, lo que permite aplicar múltiples opciones del mismo tipo de filtro. Además, para los filtros de tipo cadena ya no distingue entre mayúsculas y minúsculas y permite escribir, con anticipación, palabras contenidas en una frase de varias palabras.
Las siguientes capacidades solo están disponibles para usuarios y administradores de Signals Notebook Standard o Private Cloud y no están disponibles para usuarios de Signals Notebook Individual Edition.
Requerimiento de cuadernos
El administrador del sistema ahora puede definir como obligatorio la presencia de cuadernos dentro de los experimentos y solicitudes.
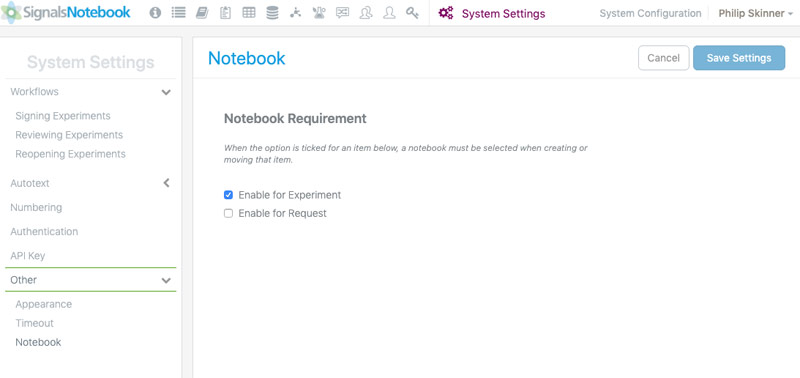
Cuando se aplica esta configuración, los autores no pueden crear experimentos y/o solicitudes sin seleccionar primero un cuaderno.
Listas externas
La capacidad de "lista externa" ya no se considera una herramienta de la versión beta y ahora está disponible para todos los clientes de Signals Notebook Standard o Signals Notebook Private Cloud sin solicitud.
Las siguientes capacidades están en versión beta y sólo están disponibles para usuarios y administradores de Signals Notebook Standard o Private Cloud a solicitud. Póngase en contacto con su representante de cuenta o con nuestro soporte si desea acceder a las siguientes funciones. No están disponibles como parte de Signals Notebook Individual Edition.
API públicas adicionales
Se han agregado puntos finales de API públicos adicionales, inluidas las API de búsqueda y las API para administrar usuarios, grupos de usuarios, muestras y materiales. Las mejoras continuas de la API continuarán independientemente de las actualizaciones de Signals Notebook.
CRAIS Checker
CRAIS Checker (o Compliance Checker) es una base de datos de cumplimiento químico de Patcore Inc. Un administrador puede configurar que se verifique el cumplimiento de las reacciones en la base de datos de CRAIS Checker. El administrador puede definir si se deben evitar los eventos de firma en el experimento si la verificación de cumplimiento no se completa.

Tareas y solicitudes
Signals Notebook ahora admite flujos de trabajo de tareas y solicitudes. Los científicos pueden crear solicitudes, definir tareas y enviar esas tareas para su finalización. Un colaborador puede seleccionar esas tareas dentro de su experimento para completar. Ambas partes pueden realizar adiciones a las tareas mientras están en progreso. El administrador puede definir tipos de tareas y propiedades para esos tipos.
- Detalles
- Categoría: Minitab
- Visto: 12874

Por Evan McLaughlin.
|
Con Minitab Statistical Software, se dispone de una interfaz fácil de usar y de todas las herramientas en tus manos para analizar datos rápidamente y tomar decisiones sobre los problemas más acuciantes de los negocios... pero ¿por dónde empezar si no se ha utilizado nunca antes? Puede ser desalentador sin una introducción apropiada Incluso usuarios de Minitab experimentados que han estado con nosotros durante varias versiones del software, pueden encontrar consejos rápidos y fáciles para ahorrar tiempo que antes no sabían. Por eso compartimos los siguientes cinco trucos. |
|
¿Quiere más? Estos trucos provienen directamente del nuevo recurso de aprendizaje electrónico gratuito Minitab Quick Start™. ¡Regístrese ahora!
|
|
1. Utilice Ctrl+E para navegar al cuadro de diálogo utilizado más recientementeDesde Calc a Estadística o Gráfica, seleccionar un ítem del menú para organizar y estructurar los datos y realizar análisis es uno de los pasos más habituales en Minitab. Se realizan unos cambios en los conjuntos de datos y se querrá correr el mismo test otra vez. No hay que molestarse en abrirse camino a través del menú. Cada. Simple. Vez. Se aprieta Ctrl+E y el cuadro de diálogo utilizado más recientemente se abrirá, incluyendo cualquier opción y entradas que se utilizaran la última vez. |

2. Fecha/hora, numérico y texto: Conozca sus tipos de datos de un vistazo¿Sabía que Minitab reconoce tres tipos diferentes de datos? Minitab es capaz de leer el primer valor que se entra en una columna y automáticamente etiquetar la parte superior de esa columna de acuerdo con el tipo de datos, para que pueda conocer su tipo de datos de un vistazo. Los tres tipos de datos son:
|
|
3. Cambiar el tipo de datos
Después de configurar el tipo de los datos, no se puede añadir un tipo diferente de datos a esa columna. Si se tuviera que escribir green, por ejemplo, en una columna donde todas las otras celdas son datos numéricos como 5.993, 6.88, 4.33, etc, se obtendría el siguiente mensaje:

Realmente no conocemos una manera científica de comparar 5.993, 6.88, 4.33 y green ("avísenos si sabe cómo"), así que Minitab hace esto para ayudarle. Si se necesita reformatear la columna después de que el formato se haya establecido, se puede hacer clic en la columna, entonces hacer clic derecho > Formato de columna y elegir un nuevo tipo de datos y formato de visualización.
|
|
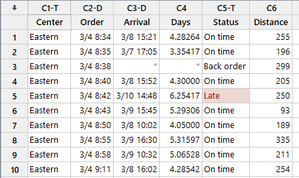
4. No solo copiar y pegar. Haga subconjuntos de su hoja de trabajo.Puede crearse fácilmente una nueva hoja de trabajo con únicamente los datos que se necesitan en cada momento. Digamos, por ejemplo, que se dispone de información de cada centro de envío pero que solo se desea ver uno de ellos. Elija Datos > Crear subconjunto de hoja de trabajo... y aparecerá un cuadro de diálogo donde se podrá seleccionar el criterio para hacer una nueva hoja de trabajo. |
5. Formato condicionalIgual que en Microsoft Excel, puede utilizarse el formato condicional en Minitab Statistical Software para resaltar celdas que cumplan una determinada condición e identificar puntos de datos, errores tipográficos o patrones inusuales en los datos antes de analizarlos. Además de las opciones estándar como Observaciones faltantes, Mayor que e Igual que , Minitab tiene reglas estadísticas adicionales disponibles. |
|
¡Con suerte podrá utilizar alguno de estos trucos para que le ayuden en su trabajo diario! Si está interesado en más lecciones gratuitas sobre cómo navegar por la interfaz de Minitab Statistical Software, organizar y estructurar sus datos e importar datos de otras fuentes como Excel, ¡le animamos a consultar el nuevo módulo de aprendizaje en línea Minitab Quick Start™!
- Detalles
- Categoría: Minitab
- Visto: 5415

Tanto si acaba de empezar a analizar sus datos o se trata de un experimentado estadístico, el nuevo recurso de formación Minitab Quick Start™ le proporcionará instrucciones sencillas y fáciles de seguir para empezar a utilizar Minitab Statistical Software para organizar y analizar sus datos para visualizar tendencias, resolver problemas y descubrir información valiosa.
Minitab Quick Start™ es un recurso de aprendizaje auto-guiado, en inglés, que le proporcionará instrucciones y demostraciones sobre las funciones básicas y navegación por la interfaz de Minitab Statistical Software.
- Detalles
- Categoría: Comsol
- Visto: 7328
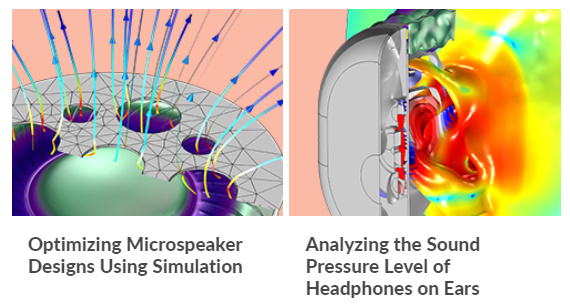
Los dispositivos móviles que cada día utilizamos, teléfonos, tabletas, ordenadores portátiles, etc, han incrementado en gran medida el uso de otros dispositivos de audio, como son los auriculares y los microaltavoces. Un diseño racional y medido de estos dispositivos es muy importante para obtener una buena calidad del sonido, pero todavía más para garantizar la seguridad del usuario. Un par de entradas del blog de COMSOL analizan y optimizan estos dispositivos.
En la entrada del blog de COMSOL de Thomas Forrister, puede ver cómo analizar el nivel de presión sonora que producen los auriculares en los oídos humanos, paso previo importante para poder diseñar auriculares seguros. Se trata de algo no trivial sin una herramienta de simulación como COMSOL al encontrarse estos dispositivos tan cerca de un sistema tan complejo como el oído humano.
Por otro lado, Rachel Keatley nos presenta en su entrada cómo optimizar el diseño de un microaltavoz utilizando la simulación de COMSOL Multiphysics. Estos dispositivos están presentes hoy en día en prácticamente cualquier aparato de consumo. Obtener una buena calidad del sonido con estos altavoces tan pequeños puede ser un reto de diseño complicado que la simulación ayuda a resolver.