- Detalles
- Categoría: Minitab
- Visto: 12608
Por Stacey McDaniel
Aunque a menudo viajan en los mismos círculos, la mejora continua y la calidad no son lo mismo. Si bien la mejora continua y la calidad están relacionadas, tienen objetivos diferentes. Profundicemos y analicemos esas diferencias con respecto a la fabricación y las herramientas que se utilizan para lograr ambas.
- La calidad de fabricación se refiere al nivel de excelencia en el proceso de producción y el producto final, asegurando que cumple o supera las especificaciones deseadas. La calidad se puede definir de varias maneras, como confiabilidad, durabilidad, rendimiento, seguridad y facilidad de uso.
- La mejora continua identifica áreas de mejora, analiza las causas raíz e implementa cambios para eliminar desperdicios, reducir costes y aumentar la productividad.
Si bien ambas son componentes esenciales de una fabricación exitosa, la garantía de calidad garantiza que el producto final cumpla con el estándar deseado, mientras que la mejora continua se enfoca en hacer que el proceso de producción sea más eficiente y efectivo, lo que lleva al éxito y la sostenibilidad a largo plazo. Existen diferencias similares en la calidad del diseño y la mejora continua en la oficina, no solo en la fabricación específicamente. En resumen, la calidad de fabricación es un resultado, mientras que la mejora continua es un proceso continuo.
Donde mejora continua y calidad se superponen
La mejora continua es un factor clave de la calidad. Al esforzarse constantemente por mejorar los procesos, productos y servicios, las organizaciones crean resultados de mayor calidad. Alternativamente, la calidad es un objetivo clave de la mejora continua. Al implementar procesos de mejora continua, las organizaciones pueden mejorar la calidad al identificar y abordar los problemas antes de que se conviertan en problemas mayores.
DIFERENTES METODOLOGÍAS UTILIZADAS
Se utilizan diferentes metodologías para la calidad y la mejora continua, pero también hay cierta superposición, como se verá:
- Para asegurar la calidad, se utilizan comúnmente metodologías como Six Sigma, Gestión de calidad total (TQM), Control estadístico de procesos (SPC) y Lean Manufacturing. Estas metodologías se enfocan en identificar y eliminar defectos, reducir la variabilidad y mejorar la estabilidad del proceso para lograr resultados de producción consistentes y de alta calidad.
- Las metodologías de mejora continua como Kaizen y Lean Manufacturing se enfocan en optimizar el proceso de producción para eliminar desperdicios, reducir los tiempos de ciclo y mejorar la eficiencia. Estas metodologías se basan en un enfoque de resolución de problemas que implica identificar oportunidades de mejora, probar soluciones potenciales e implementar cambios en un circuito de retroalimentación continuo.
Tanto las metodologías de garantía de calidad como las de mejora continua están diseñadas para mejorar los procesos de fabricación y mejorar la calidad del producto. Sin embargo, las técnicas y herramientas específicas utilizadas pueden diferir según las metas y objetivos específicos de cada enfoque.
EN QUÉ SE DIFERENCIAN LAS HERRAMIENTAS
Las herramientas de calidad y las herramientas de mejora continua son esenciales para diferentes aspectos de la investigación para mejorar los procesos y la calidad.
- Las herramientas de calidad se utilizan para garantizar que los resultados de la investigación sean precisos, fiables y válidos. Pueden ayudar a identificar posibles fuentes de sesgo, medir la coherencia de la recopilación de datos y evaluar la precisión de los análisis estadísticos. Los ejemplos de herramientas de calidad utilizadas en la investigación incluyen gráficos de control, gráficos de Pareto, diagramas de Ishikawa y control estadístico de procesos.
- Se utilizan herramientas de mejora continua para optimizar el proceso de investigación, haciéndolo más eficiente y eficaz. Pueden ayudar a identificar áreas de desperdicio, reducir los tiempos de ciclo y mejorar la productividad. Los ejemplos de herramientas de mejora continua utilizadas en la investigación incluyen Kaizen, Lean Manufacturing y el ciclo Plan-Do-Check-Act (PDCA).
Tanto las herramientas de calidad como las de mejora continua son necesarias para asegurar la calidad de la investigación y mejorar el proceso de investigación. Las herramientas de calidad ayudan a garantizar la precisión y validez de los resultados de la investigación, mientras que las herramientas de mejora continua ayudan a optimizar el proceso de investigación para lograr mejores resultados con menos tiempo y esfuerzo. Por lo tanto, los investigadores deben usar ambos tipos de herramientas para lograr resultados de investigación de alta calidad.
Como puede ver, la mejora continua y la calidad son muy diferentes, y no puede tenerse una sin la otra. Si desea ver cómo Minitab puede ayudar en sus iniciativas de calidad o mejora continua, ¡comuníquese con nosotros!
- Detalles
- Categoría: Lakes
- Visto: 5178

CALRoads View hace que sea muy fácil introducir enlaces a un proyecto de modelado utilizando una de las series de modelos CALINE (CALINE, CAL3QHC, CAL3QHCR). Si bien es común representar enlaces gráficamente, CALRoads también permite a los modeladores importar enlaces usando una plantilla de hoja de cálculo de Excel. Esto es útil para los modeladores que tienen todas sus entradas definidas o aquellos que tienen muchos datos para incluir. La hoja de cálculo plantilla se encuentra en la carpeta C:\Lakes\CALRoads View\Templates.
Una funcionalidad nueva es la capacidad de importar enlaces de grupo (G-Links). La columna T de la hoja de cálculo presenta una columna Group.
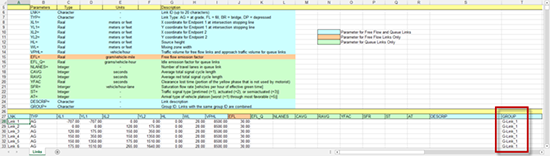
Para definir enlaces de grupo, especifique Group ID para varios enlaces. Utilice el mismo ID de grupo en todos los enlaces del grupo. Se pueden importar varios enlaces de grupo mediante el uso de un ID de grupo único para cada enlace de grupo.
- Detalles
- Categoría: Comsol
- Visto: 3024
El plazo de entrega anticipada de resúmenes en la conferencia COMSOL Conference 2023, que supone un gran descuento en el registro a la conferencia está próximo a su fin.
Envíe su resumen antes del viernes, 9 de junio y tanto Vd. como los coautores del trabajo podrán optar a un precio de registro reducido (ahorro de 150€).
¡No pierda esta oportunidad para mostrar sus investigaciones e ideas a una audiencia global de expertos en simulación e ingenieros!
Para obtener las guías, plantillas y entregar su resumen, visite la web de la conferencia
- Detalles
- Categoría: Minitab
- Visto: 6113

Por Andrea Grgic
Piense en su última visita al médico. ¿Fue amable el personal del hospital? ¿La sala de espera era cómoda? ¿Cuánto tiempo esperó a que el médico lo viera? ¿Su enfermera mostró empatía durante su visita? Todos estos factores contribuyen a la experiencia general del paciente, uno de los aspectos más importantes de la atención médica.
En este artículo del blog de Minitab, cubrimos la importancia de la satisfacción y la experiencia del paciente, junto con las formas en que el análisis predictivo y las herramientas de mejora continua pueden ayudar a los proveedores de atención médica a mejorar la satisfacción general del paciente.
SATISFACCIÓN DEL PACIENTE VERSUS EXPERIENCIA DEL PACIENTE: ¿CUÁL ES LA DIFERENCIA?
La satisfacción del paciente se refiere a si se cumplieron las expectativas de un paciente durante su visita con un proveedor de atención médica. Es uno de los indicadores clave para que los proveedores y hospitales evalúen dónde mejorar como organización y está directamente relacionado con el éxito general. Por estas razones, es una prioridad principal en todas las organizaciones de atención médica.
La experiencia del paciente se centra en mejorar la satisfacción del paciente y los resultados, reducir el tiempo de tratamiento y mejorar la coordinación de la atención al paciente. Según la "2023 Gartner CIO and Technology Executive Survey", la excelencia operativa y la experiencia del paciente son los objetivos principales de las inversiones digitales para los proveedores de atención médica.
LLUVIA DE IDEAS SOBRE LOS CONTRIBUIDORRES A LA SATISFACCIÓN DEL PACIENTE
Al pensar en la experiencia general del paciente, es importante tener en cuenta los factores que afectan a los pacientes. Una manera fácil de comenzar es hacer una lluvia de ideas con el personal administrativo y clínico y "trazar" estos factores con un mapa mental.
Un mapa mental ayuda a organizar visualmente ideas y conceptos relacionados, para que se pueda comprender mejor el concepto central y las posibles soluciones.
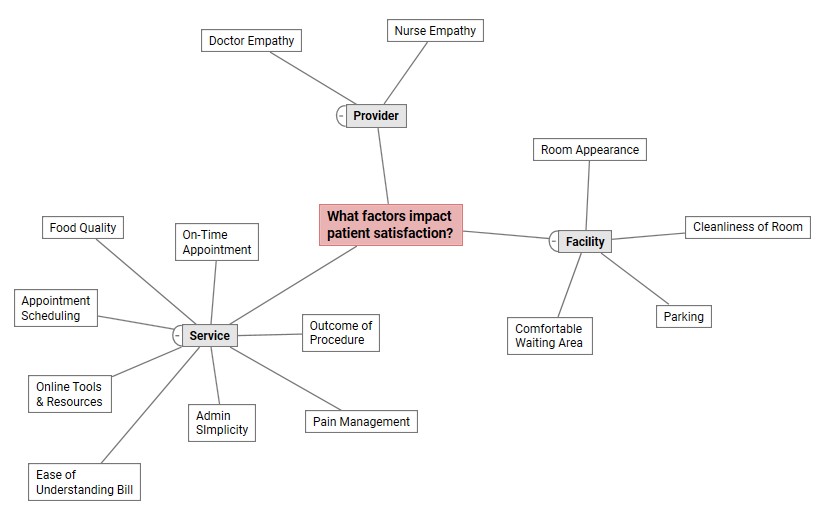
En el ejemplo anterior, utilizamos Minitab Engage para crear un mapa mental que ayude a comprender los factores en los que uno quiere enfocarse para mejorar la satisfacción del paciente. Ahora que se dispone de los factores mapeados, se determina cómo abordar la satisfacción del paciente.
Una de las formas más efectivas y rentables para que los proveedores de atención médica midan la satisfacción del paciente es enviar una encuesta.
ENCUESTA DE SATISFACCIÓN DEL PACIENTE: UNA MIRADA MÁS CERCANA
Los resultados de la encuesta de satisfacción del paciente brindan una comprensión más profunda de por qué los pacientes pueden o no estar satisfechos con su servicio. Repasemos un ejemplo.
Al observar el conjunto de datos de pacientes de muestra, se puede ver que se les pidió a los pacientes que calificaran su satisfacción general con un proveedor de atención médica. También se les pidió que calificaran otros factores importantes de su atención, como la empatía de la enfermera y el médico, la apariencia de la habitación, las citas a tiempo y las comodidades, que revisaremos más adelante en este artículo.
Los resultados de esta encuesta de muestra muestran que el 55% de los pacientes estaban satisfechos con su experiencia, lo que nos dice que, en general, la mayoría de los pacientes están satisfechos con la experiencia de su proveedor de atención médica.
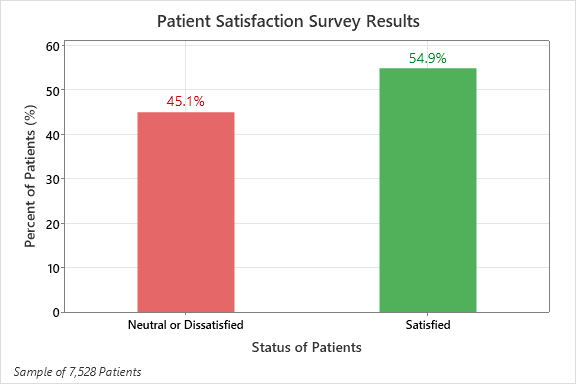
SATISFACCIÓN DEL PACIENTE: UN ENFOQUE PREDICTIVO
Es un buen comienzo saber que, en general, los pacientes están satisfechos con los servicios de este proveedor de atención médica. Ahora se profundiza en por qué estos pacientes están satisfechos y cómo se compara su experiencia con un paciente insatisfecho o neutral.
Al aprovechar el módulo de analítica predictiva de Minitab Statistical Software, el proveedor de atención médica puede identificar fácilmente los impulsores clave de la satisfacción del paciente. Para nuestro ejemplo, se utiliza CART®.
CART®, o árboles de clasificación y regresión, es un algoritmo de árbol de decisiones que se utiliza para encontrar patrones y relaciones importantes en variables de datos. Si la pregunta o el desafío al que uno se enfrenta tiene una respuesta categórica binomial o multinomial, utilice Clasificació CART, mientras que cualquier cosa que tenga una respuesta continua con muchos predictores categóricos o continuos debe usar CART Regression.
En la encuesta de muestra, se clasifica a los clientes en dos grupos, ya sea que estén satisfechos o no con este proveedor de atención médica, por lo que se utiliza la clasificación CART. Minitab Statistical Software encuentra automáticamente el mejor árbol de decisiones y proporciona estadísticas del modelo, para que se pueda comprender si el modelo es útil para el análisis.
Como puede verse a continuación, la empatía de la enfermera y mantener informado al paciente son las variables más importantes al predecir la satisfacción del paciente, seguidas por la empatía del médico y el resultado del procedimiento., que también se clasificó como muy importante.
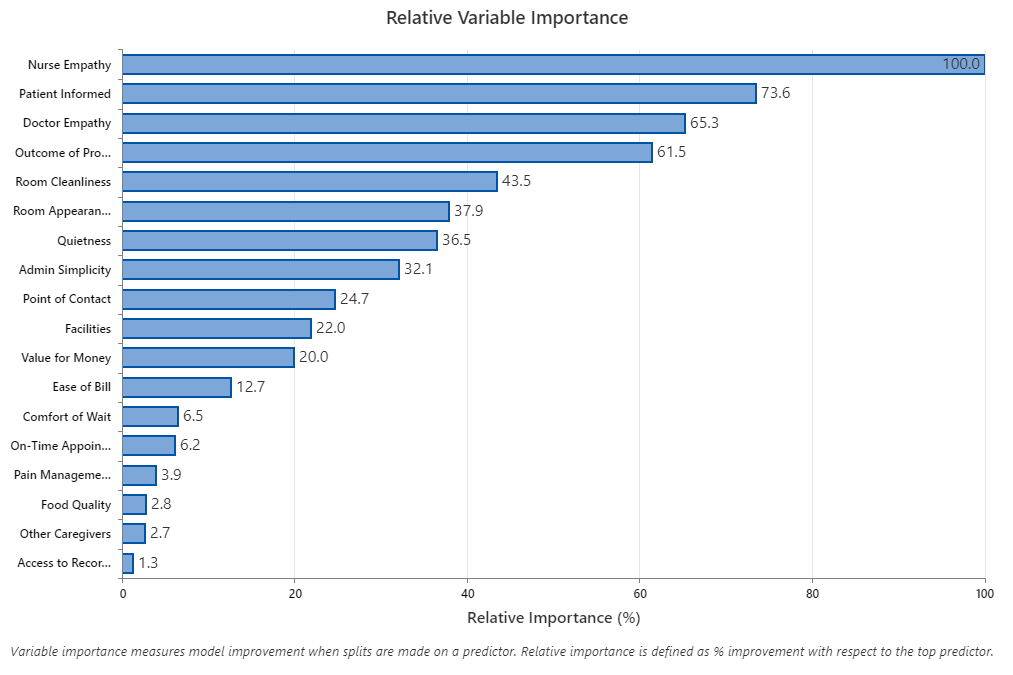
USO DE DIAGRAMAS DE ÁRBOL PARA COMPRENDER LOS DATOS DEL PACIENTE
Para empezar, nos gustaría mencionar que la empatía de las enfermeras se mide en una escala de 5 puntos, donde 5 indica una evaluación muy positiva. Al observar el árbol con mayor detalle, podemos ver que cuando la empatía de la enfermera se calificó con más de 3,5, aproximadamente el 82% de los pacientes calificaron su experiencia como satisfecha. También podemos ver que cuando los pacientes calificaron la empatía de su enfermera con menos de 3,5, estaban más satisfechos si el proveedor les informaba mejor, pero mucho menos satisfechos si no les informaban.
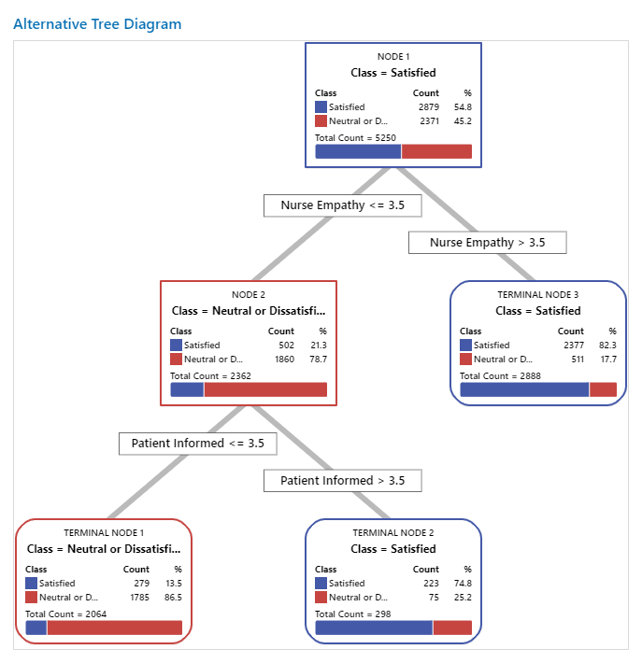
Al mirar el árbol de arriba, los proveedores de atención médica pueden ver que los pacientes quieren una enfermera empática y esperan estar informados durante su visita, pero saber que incluso si su enfermera no muestra empatía, pueden mantener felices a los pacientes manteniéndolos informados, lo que es una idea importante.
CONCLUSIÓN
La satisfacción del paciente es solo una parte de la experiencia general del paciente. Los conocimientos basados en datos del análisis predictivo, junto con las herramientas de lluvia de ideas, pueden ayudar a los proveedores de atención médica a lograr una atención óptima al paciente.
- Detalles
- Categoría: MapleSim
- Visto: 5384
Si una empresa buscando exprimir más la potencia de un vehículo eléctrico o espera mejorar la vida útil de la batería de los dispositivos de uso cotidiano, un diseño energéticamente eficiente de los sistemas de alimentación de baterías es cada vez más necesario y los modelos de baterías ahora son una herramienta indispensable para optimizar estos sistemas.
Los sistemas de baterías tienen un impacto global en el tiempo de actividad, la vida útil, la estabilidad térmica y la seguridad del sistema global, lo que hace que el rendimiento de la batería sea un aspecto crucial del diseño de un sistema. Los modelos de baterías de alta fidelidad, como los que se encuentran en la MapleSim Battery Library, pueden ayudar a proporcionar estimaciones precisas del comportamiento real de la batería y las técnicas basadas en modelos pueden dar respuestas basadas en la física a preguntas importantes en el proceso de diseño. Con la MapleSim Battery Library, los sistemas alimentados por batería se pueden modelar mucho más rápido que con las técnicas tradicionales, al tiempo que conservan la precisión para obtener resultados significativos.
Este artículo destaca tres historias de la industria que van desde aplicaciones de alto rendimiento hasta aplicaciones de alta eficiencia. Cada historia ayuda a describir las formas en que los modelos de batería y un enfoque de modelado a nivel de sistema brindan a las empresas la capacidad de tomar mejores decisiones durante su proceso de diseño.
- Detalles
- Categoría: Comsol
- Visto: 5466

Hanna Gothäll, del equipo técnico de COMSOL, nos explica cómo crear una malla de simulación a partir de los datos obtentidos mediante técnicas de imágenes 3D. En concreto noe muestra cómo hacerlo utilizando COMSOL Multiphysics®, completando otros artículos ya presentados anteriormente que trataban el tema del modelado de formas irregulares.
En el ejemplo nos muestra la construcción a partir de datos que vienen en conjuntos de imágenes transversales. En concreto se refiere a parte de un fémur humano.
En el proceso se divide la malla de la superficie, se suavizan los datos utilizando dos técnicas diferentes y explica cómo combinar la malla y la geometría.
Pueden encontrar más detalles en el artículo del blog de COMSOL y descargando el archivo mph del modelo. Acceda a ellos utilizando los enlaces al final de este artículo.
- Detalles
- Categoría: Minitab
- Visto: 5627

Por Joshua Zable
Cuando la gente piensa en construir cosas, piensa en herramientas. Aunque los martillos, los destornilladores, las llaves y la maquinaria son fundamentales para construir cosas, las herramientas analíticas son igual de importantes. Sin el "equipo" adecuado para resolver problemas, se puede terminar construyendo algo que se rompa, no dure mucho, lleve mucho tiempo producirlo o cueste más de lo previsto. Naturalmente, cuanto más complejo sea el elemento o componente, mayor será la necesidad de “instrumentos” analíticos.
LAS BATERÍAS ESTÁN LITERALMENTE LLENAS DE ENERGÍA... ASÍ QUE SE NECESITA MUCHO PARA FABRICARLAS
El proceso de diseño, creación y fabricación de baterías es complejo debido a varios factores. Un desafío clave en este proceso es gestionar la compleja química involucrada, ya que el rendimiento de la batería depende de las reacciones químicas.
Las baterías están hechas de diferentes materiales, cada uno con propiedades únicas que pueden afectar la conductividad, la estabilidad y la durabilidad de la batería. Mantener un estricto control y precisión durante todo el proceso de fabricación es fundamental para garantizar que las pruebas de calidad y rendimiento sean sólidas. Esto es particularmente importante para aplicaciones críticas para la seguridad, como los vehículos eléctricos. El siguiente mapa mental, producido en Minitab Workspace, demuestra algunos detalles más sobre estas complejidades:
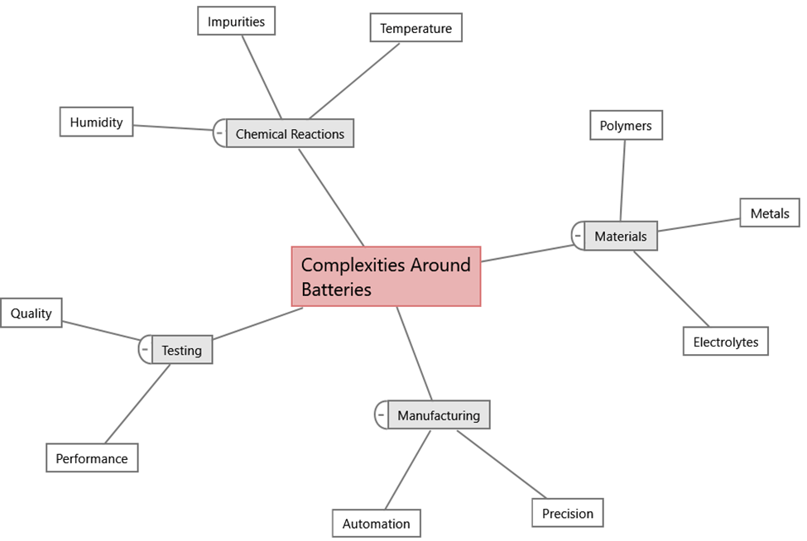
LAS "HERRAMIENTAS" ANALÍTICAS DE RESOLUCIÓN DE PROBLEMAS PUEDEN AYUDAR A ABORDAR ESTAS COMPLEJIDADES
Utilizar plantillas de lluvia de ideas y gestión de proyectos para definir el problema, el proyecto y el resultado deseado
Definir el proyecto con una carta del proyecto y una lluvia de ideas sobre los elementos que contribuyen tanto al producto como al proceso de fabricación es fundamental para abordar el desafío en sí. Tal vez no se esté comenzando desde cero y se necesite utilizar otras herramientas como un diagrama de espina de pescado o una matriz C&E para identificar las causas del bajo rendimiento. Independientemente, al abordar productos y procesos complejos, las plantillas probadas permiten delinear el resultado esperado, medir y replicar el éxito.
Utilizar Analytics para diseñar la combinación óptima de productos químicos y materiales para maximizar el rendimiento
Una vez que se defina el objetivo (por ejemplo, capacidad, voltaje o ciclo de vida) y se comprendan sus factores clave, se diseña un experimento para optimizar la combinación de variables que afectan el rendimiento de la batería o el proceso de fabricación. Puede ejecutarse el experimento completo, ejecutar un diseño de detección o incluso usar análisis predictivos para ayudar a identificar los factores más impactantes.
Utilizar herramientas de confiabilidad para estimar la probabilidad de falla e identificar formas de mejorar la durabilidad de la batería
Una vez que se diseñe la batería para un rendimiento ideal, querrá asegurarse de que dure. Con la prueba de vida acelerada, los fabricantes pueden simular años de uso en un período corto y evaluar la confiabilidad de la batería. Luego, utilizando un análisis y efectos de modos de falla (FMEA), se identifican los posibles modos de falla e implementan acciones correctivas para mitigar el riesgo de falla.
Supervisar la calidad del producto y el proceso mediante herramientas de calidad
Ya sea que se esté fabricando un primer lote de baterías, incrementando la producción o ya se encuentre en una producción de alto volumen, mantener y mejorar la calidad es trabajo de todos. Ya sea que se estén utilizando soluciones más tradicionales, como el análisis de sistemas de medición o el control estadístico de procesos, o técnicas más emergentes, como el aprendizaje automático, pueden reducirse los costes y los desperdicios mientras se mejora el rendimiento de los productos al contar con un sólido marco de análisis de calidad.