- Detalles
- Categoría: Comsol
- Visto: 6017
Las dos noticias anteriores trataron el tema de corrosión, dando primero una introducción y luego ejemplos prácticos sobre el tema. En esta ocasión mostraremos el módulo de electroquímica (Electrochemistry Module) en COMSOL Multiphysics. Dicho módulo aborda problemas de índole electroquímica desde un punto de vista más general de lo que lo pudiera hacer Corrosion Module.
El Módulo de Electroquímica de COMSOL Multiphysics [1] es una extensión que permite a los usuarios realizar simulaciones y análisis relacionados con fenómenos electroquímicos. Algunas de sus principales características incluyen el modelado de sistemas electroquímicos. Por ejemplo, es posible simular reacciones químicas y electroquímicas, así como procesos de transferencia de carga y transporte de iones y electrones. El módulo otorga una amplia gama de aplicaciones tales como la corrosión, la electrólisis, la electroquímica ambiental, la batería y la celda de combustible, entre otros.
En cuanto al acoplamiento multifísico, este módulo permite acoplar las simulaciones electroquímicas con otros fenómenos físicos, como la transferencia de calor, la mecánica de sólidos, la transferencia de masa y más. Para aquello, posee una interfaz de usuario intuitiva para definir geometrías, propiedades del material y condiciones de contorno. En relación con la visualización y análisis de resultados, el módulo permite la visualización detallada de los resultados de simulación para comprender el comportamiento de los sistemas electroquímicos.
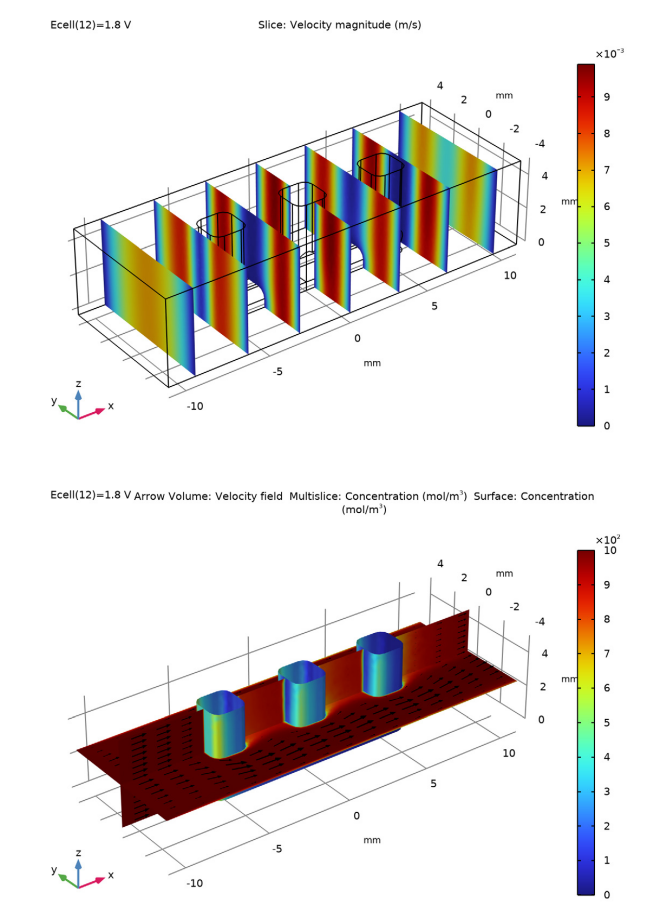
A continuación, presentamos un ejemplo resuelto con el módulo de Electroquímica. Se trata de un Wire Electrode [2], lo cual hace referencia al estudio de una celda electroquímica. Es un buen punto de partida para hacer visible las posibilidades de simular las distribuciones de densidad de corriente primaria, secundaria y terciaria. Para contextualizar, el modelo se puede considerar como una celda unitaria de un electrodo de malla metálica más grande que es común en varios procesos industriales. Uno de los aspectos más importantes en el diseño de celdas electroquímicas es la distribución de densidad de corriente en el electrolito y los electrodos. Distribuciones no uniformes de la densidad de corriente pueden ser perjudiciales para el funcionamiento de los procesos electroquímicos. En muchos casos, las partes de un electrodo que están sometidas a una alta densidad de corriente pueden degradarse a una tasa más rápida. El conocimiento de la distribución de la densidad de corriente es necesario para optimizar la utilización de los electrocatalizadores que suelen estar compuestos de metales nobles costosos. La deposición y el consumo no uniformes, las sobretensiones innecesariamente altas, las pérdidas de energía y las posibles reacciones secundarias no deseadas representan efectos que deben minimizarse. Este es el motivo por el cual el modelo apunta a obtener las distribuciones de densidad de corriente de una celda electroquímica arbitraria con electrodos metálicos. Ver la Figura de la cabecera, que muestra el Campo de flujo (arriba: diagrama de cortes con la magnitud de la velocidad) y el perfil de concentración (abajo: gráfico de superficie para el ánodo. Se incluye un corte con flechas de superficie para la dirección de la velocidad) a 1,8 V.
En resumen, el Módulo de Electroquímica de COMSOL Multiphysics es una herramienta esencial para modelar y analizar sistemas electroquímicos en una amplia gama de aplicaciones, brindando la capacidad de comprender y optimizar procesos y diseños relacionados con la electroquímica.
Referencias
[1] Electrochemistry Module de COMSOL
[2] Galería de aplicaciones de COMSOL: Wire Electrode
- Detalles
- Categoría: Lakes
- Visto: 5115

En un artículo anterior se analizó el nuevo Visor de tablas Top-50 (Top-50 Table Viewer), una de las nuevas incorporaciones a CALPUFF View Versión 10.0 que ayuda a los modeladores a visualizar la salida del posprocesador CALPOST. Otra adición a esta versión de CALPUFF View es la vista de cuadrícula de valores clasificados (Ranked Values Grid View).
Los valores clasificados de CALPOST son similares a la opción Valores más altos ("Higuest Values") que se encuentra en la ruta de salida del modelo de dispersión de aire AERMOD. Los modeladores definen el valor de salida clasificado y los resultados del modelo se ordenan receptor por receptor con los valores reportados definidos por el usuario.
Por ejemplo, al especificar un valor clasificado de 2, se devolverá el segundo valor más alto de cada receptor para la especie, el proceso y el período de promedio seleccionados. CALPOST puede calcular hasta cuatro valores clasificados que van del 1.º al 10.º rango. Después de una ejecución exitosa de CALPOST, CALPUFF View utiliza los datos para generar gráficos de contorno de cada rango, especie, proceso y período promedio seleccionado.
Con el lanzamiento de la versión 10.0, los modeladores ahora pueden ver el resultado de los valores clasificados en un visor de tabla cuadriculada para extraer y analizar el resultado del modelo más fácilmente. Para acceder a la vista de cuadrícula de valores clasificados:
- Vaya a la pestaña CALPOST Tree View que se encuentra en la parte inferior izquierda de la ventana de la aplicación.
- Seleccione el archivo de gráfico de valores clasificados (Ranked Values) que desee de la lista de especies.
- Haga clic derecho en el archivo para abrir el menú contextual.
- Seleccione la selección "View as grid" en este menú contextual.
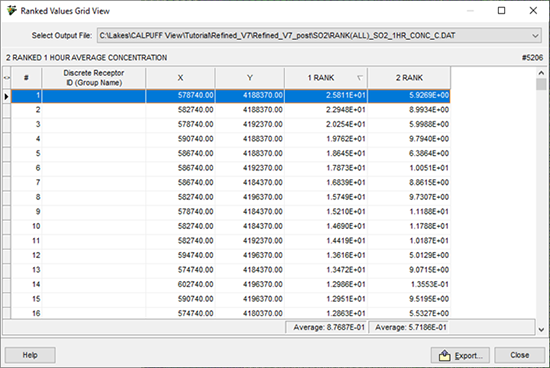
La información del archivo de gráfico se muestra en un formato de cuadrícula fácil de leer. La información se puede ordenar por columna haciendo clic en el encabezado de la columna. También puede arrastrar y soltar las columnas para cambiar el orden en que se muestran. El valor promedio de cada columna de clasificación se muestra en el panel inferior, debajo de la columna RANK.
El valor numérico en cada columna RANK representa el valor clasificado como se especifica en la configuración de Opciones de CALPOST - Ranked Values. Por ejemplo, “1 RANK” representa los valores de salida más altos (Rango 1).
En la parte superior de este cuadro de diálogo, se muestra el nombre y la ubicación del archivo de gráfico. En esta lista desplegable puede seleccionar qué archivo de gráfico desea ver en formato de cuadrícula. Debajo se puede ver una descripción del archivo de trama junto con el número total de receptores.
Los datos también se pueden exportar a formato CSV usando el botón  en la parte inferior del cuadro de diálogo.
en la parte inferior del cuadro de diálogo.
- Detalles
- Categoría: Minitab
- Visto: 58687
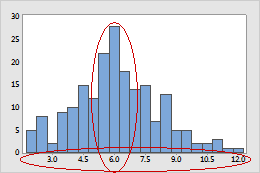
Los aspectos más importantes para interpretar de un histograma son su forma (que en general debe parecerse a una campana) y el rango de variación. De hecho, algunos histogramas incluyen una línea suavizada que resigue el perfil de las barras para facilitar su visualización.
Cuando nos referimos a la forma del histograma queremos describir si hay concentración de los datos en torno a un valor, el grado de dispersión y la presencia de patrones no aleatorios (varios grupos, anomalías, etc.)
¿Cómo se interpreta el rango de variación de un histograma?
En un histograma podemos interpretar como es la dispersión global de los datos (rango de variación) leyendo en el eje horizontal (eje x) de dónde a dónde va nuestra variable numérica. A partir de aquí nos podemos preguntar: ¿es la dispersión de los datos la que esperábamos? ¿Es la dispersión la que queremos? ¿Es posible cumplir las especificaciones con esta dispersión? Las respuestas a estas preguntas nos pueden dar pistas sobre cómo es el proceso y dónde actuar para mejorarlo.
¿Cómo se interpreta un histograma con forma simétrica?
Si el histograma muestra simetría y un solo pico, se asocia a que los datos se ajustan a una distribución Normal (de campana o de Gauss en honor al matemático que describió esta distribución). Pero lo importante no es el nombre que usemos para describir la forma, sino cómo la interpretamos y la información que extraemos.
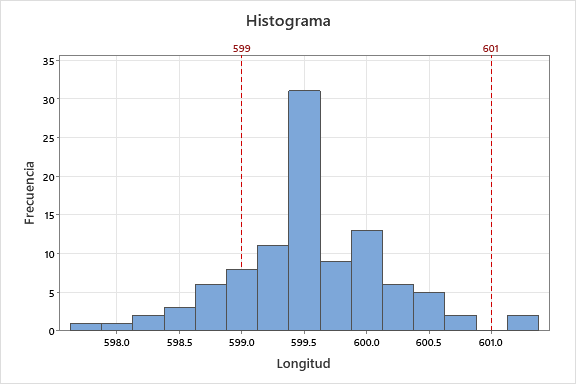 En el histograma de abajo vemos la longitud de 100 piezas escogidas al azar que ha medido un ingeniero. El valor nominal de la longitud es 600, y se pretende comprobar si están dentro de tolerancias (599, 601). En el gráfico vemos que la mayoría de las piezas tienen una longitud entre 599 y 600. La forma de campana nos dice que la frecuencia con la que encontramos piezas con longitudes superiores e inferiores al intervalo 599-600 disminuye a medida que nos alejamos del intervalo. Además, cuando observamos el rango de variación, podemos ver que hay muchas piezas que están fuera de tolerancias; más por debajo que por encima porque la distribución (la campana) no está centrada en tolerancias.
En el histograma de abajo vemos la longitud de 100 piezas escogidas al azar que ha medido un ingeniero. El valor nominal de la longitud es 600, y se pretende comprobar si están dentro de tolerancias (599, 601). En el gráfico vemos que la mayoría de las piezas tienen una longitud entre 599 y 600. La forma de campana nos dice que la frecuencia con la que encontramos piezas con longitudes superiores e inferiores al intervalo 599-600 disminuye a medida que nos alejamos del intervalo. Además, cuando observamos el rango de variación, podemos ver que hay muchas piezas que están fuera de tolerancias; más por debajo que por encima porque la distribución (la campana) no está centrada en tolerancias.
¿Cómo se interpreta un histograma con forma asimétrica?
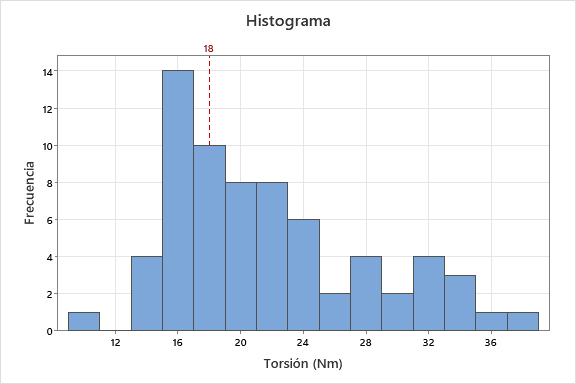 En otros casos, el histograma muestra asimetría, que puede ser a la derecha (si hay un pico con una cola a la derecha) o a la izquierda (si hay un pico con una cola a la izquierda). En este caso, se interpreta que hay un alto número de valores alrededor del pico y que, en el caso de la asimetría a la derecha, los valores se alejan más del pico por la derecha que por la izquierda, es decir, hay menos valores (y más cercanos) por debajo del pico, y más lejanos con frecuencia decreciente por encima del pico.
En otros casos, el histograma muestra asimetría, que puede ser a la derecha (si hay un pico con una cola a la derecha) o a la izquierda (si hay un pico con una cola a la izquierda). En este caso, se interpreta que hay un alto número de valores alrededor del pico y que, en el caso de la asimetría a la derecha, los valores se alejan más del pico por la derecha que por la izquierda, es decir, hay menos valores (y más cercanos) por debajo del pico, y más lejanos con frecuencia decreciente por encima del pico.
En otros casos, el histograma muestra asimetría, que puede ser a la derecha (si hay un pico con una cola a la derecha) o a la izquierda (si hay un pico con una cola a la izquierda). En este caso, se interpreta que hay un alto número de valores alrededor del pico y que, en el caso de la asimetría a la derecha, los valores se alejan más del pico por la derecha que por la izquierda, es decir, hay menos valores (y más cercanos) por debajo del pico, y más lejanos con frecuencia decreciente por encima del pico.
¿Cómo se interpretan otras formas en un histograma?
Otra forma habitual en el histograma es encontrar dos (o más) picos. Esto suele ser un indicador de que hay otra variable (que no estamos visualizando directamente) que separa en grupos nuestra variable numérica porque no está fija y afecta. Podría tratarse de tiempos de espera de entre semana vs. fin de semana o de piezas fabricadas en la máquina 1 y la máquina 2.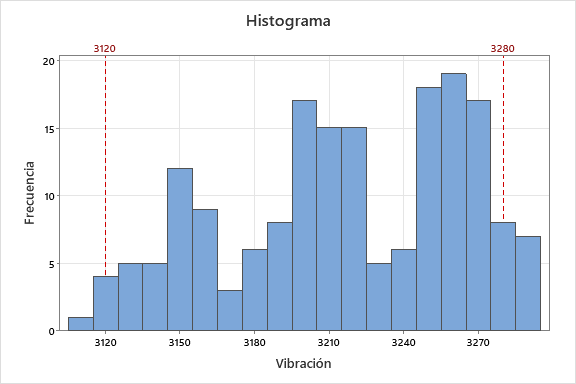 Es importante en estos casos indagar más para identificar cuál es la variable que cambia y luego tratar cada grupo por separado.
Es importante en estos casos indagar más para identificar cuál es la variable que cambia y luego tratar cada grupo por separado.
En el ejemplo observamos tres picos en forma de campana que, en conjunto, tienen un rango de variación que hace que no entren en tolerancias. Debemos sospechar que hay alguna variable oculta (que de momento no tenemos en cuenta y no visualizamos) que separa la variable vibración en tres grupos. A pesar de que globalmente la variable no entra en tolerancias (ni por debajo ni por arriba), hay que indagar más sobre los tres grupos porque individualmente tienen poca variación (inferior al rango de tolerancias) y si se pudieran centrar lograríamos fabricar dentro de tolerancias.
¿Cómo se identifican los valores atípicos?
Siguiendo con el concepto del rango de variación, cuando se observan valores muy dispersos (alejados de la mayoría de los valores) y con poca frecuencia nos puede indicar que se trata de valores atípicos, es decir, inusuales. Es importante indagar en el porqué de esos valores, puesto que podemos descubrir información muy valiosa. Puede que se trate de un valor atípico porque hubo un defecto de fabricación, de materia prima o porque estamos comparando el tiempo de espera en un día festivo, o simplemente podemos descubrir que hubo un error al entrar el dato.
¿QUIERE MÁS INFORMACIÓN?
Si le apetece indagar más sobre esta herramienta u otras que pueda utilizar para entender e interpretar mejor sus datos, consulte nuestro curso de Diagnóstico con visualización de datos con Minitab.
Si desea recibir una propuesta formal del coste del curso en su caso particular, póngase en contacto con nuestro departamento comercial por teléfono (934154904 o 915158276) o a través de este FORMULARIO
- Detalles
- Categoría: Comsol
- Visto: 6482
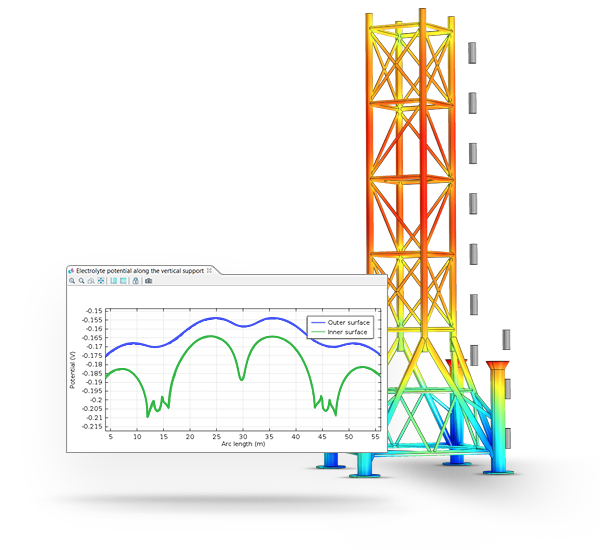
En la noticia anterior, introdujimos la corrosión de materiales y mencionamos que esta área se puede estudiar en COMSOL Multiphysics. En esta ocasión ahondaremos un poco más en el módulo de corrosión [1] y daremos a conocer algunos ejemplos. Corrosion Module es una extensión especializada de COMSOL Multiphysics. Este módulo se centra en la simulación y el análisis de la corrosión, como un proceso químico-electroquímico que resulta en la degradación de materiales metálicos debido a la interacción con su entorno.
Las principales características y capacidades clave de Corrosion Module de COMSOL Multiphysics se muestran a continuación:
- Modelado de corrosión: Permite a los ingenieros y científicos modelar una variedad de procesos de corrosión, incluida la corrosión galvánica, la corrosión por picadura, la corrosión por tensión, la corrosión bajo tensión y otros fenómenos relacionados.
- Interfaz de usuario intuitiva: El módulo proporciona una interfaz de usuario amigable que facilita la configuración de modelos de corrosión, la definición de geometría, condiciones de contorno, propiedades del material y parámetros de simulación.
- Acoplamiento multifísico: Se puede acoplar el modelado de corrosión con otras físicas, como la transferencia de calor, la mecánica de sólidos, la transferencia de masa y la electroquímica, lo que permite la simulación de problemas multidisciplinarios que involucran corrosión.
- Evaluación de propiedades de materiales: Corrosion Module incluye herramientas para la evaluación de propiedades de materiales específicas de corrosión, como las tasas de corrosión, la resistividad del electrolito, la densidad de corriente y otros parámetros que son cruciales para el modelado preciso de la corrosión.
- Visualización y análisis de resultados: COMSOL Multiphysics proporciona potentes herramientas de visualización y análisis de resultados que permiten a los usuarios comprender el comportamiento de la corrosión en sus diseños, identificar áreas críticas y tomar decisiones informadas para la mitigación de la corrosión.
- Aplicaciones diversas: Corrosion Module se utiliza en una variedad de industrias, incluyendo la aeroespacial, la industria petroquímica, la ingeniería naval, la construcción de infraestructuras, la electrónica y más, donde la corrosión puede ser un problema importante.
Seguidamente se muestran algunos ejemplos en donde se utiliza Corrosion Module como módulo de COMSOL:
Localized Corrosion Using the Level Set Method
Este ejemplo modela la corrosión galvánica entre las dos fases constituyentes de una aleación metálica [2]. Dado que las dos fases tienen diferentes potenciales de equilibrio, la corrosión ocurre cuando la aleación se expone a una solución electrolítica. Aunque es similar a un ejemplo de Corrosión Localizada, el modelo actual considera una microestructura transversal diferente que podría llevar a cambios topológicos. Dado que la formulación de geometría deformada utilizada en el ejemplo de Corrosión Localizada no puede manejar cambios topológicos, el método de Level Set se utiliza en el modelo actual para capturar la disolución de una fase constituyente. Los detalles geométricos del modelo considerado en este ejemplo se muestran en la Figura 1, junto con una microestructura representativa de la sección transversal, que consta de las fases alfa y beta. microestructura representativa de la sección transversal, que consiste en las fases alpha y beta expuestas a la solución electrolítica.
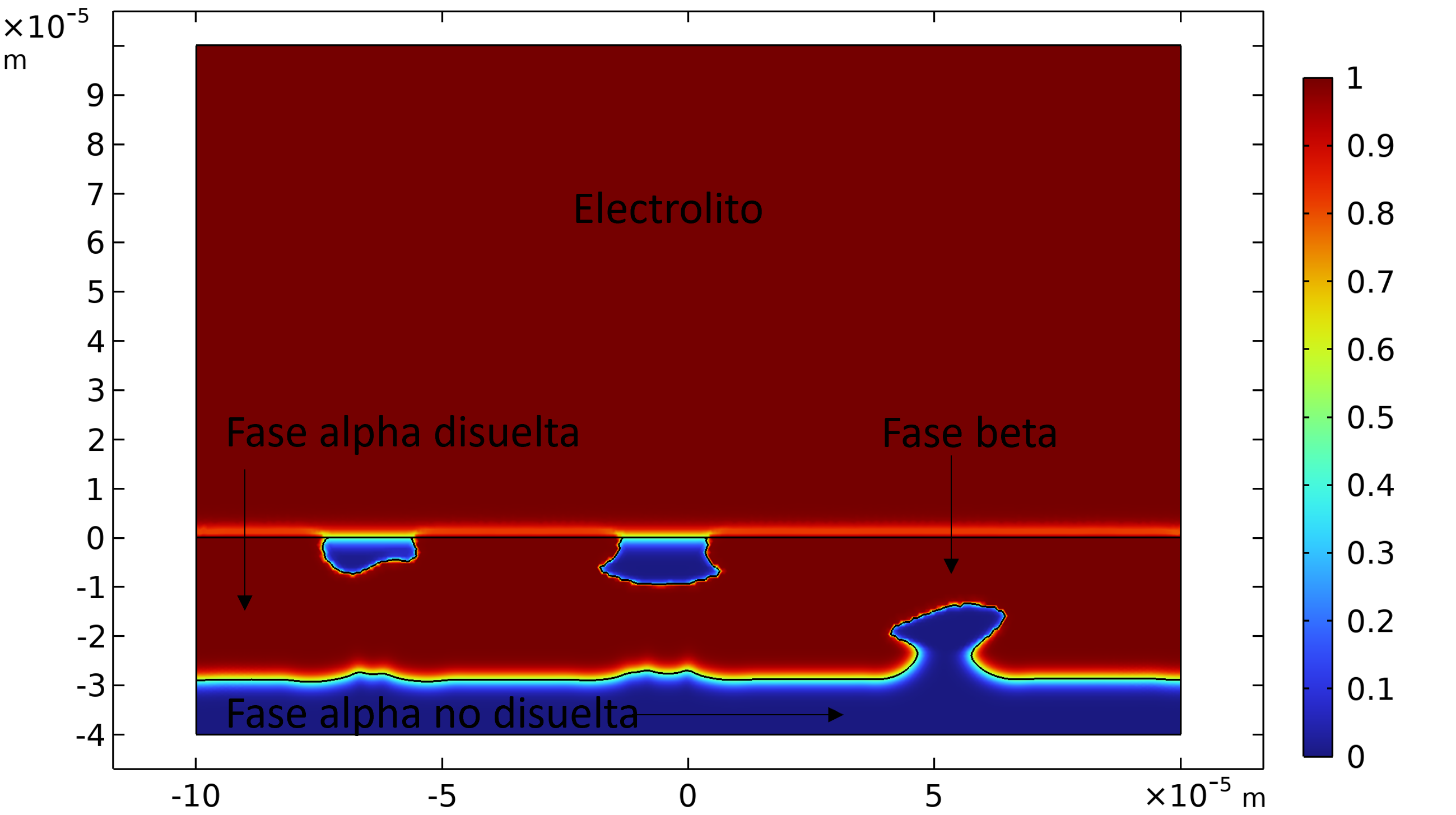
Figura 1: Gráfico de superficie de la fracción volumétrica del fluido 1 en el tiempo t = 300 h donde el valor de 1 es el dominio del electrolito y 0 es la fase beta intacta y la fase alfa no disuelta en el dominio del electrodo.
Stress Corrosion
En la industria del petróleo y el gas, los oleoductos de acero a menudo están expuestos a condiciones de esfuerzo y deformación complejas. Además del esfuerzo causado por la presión interna, los oleoductos están sometidos a una deformación longitudinal significativa debido al movimiento del suelo circundante. Como resultado de los cambios en las energías superficiales en la superficie del tubo, los esfuerzos resultantes pueden tener un efecto en la tasa de corrosión del tubo. Este ejemplo de modelo demuestra los efectos interconectados de la deformación elástica y plástica en la corrosión de los oleoductos. Las simulaciones de esfuerzos elastoplásticos se realizan aquí utilizando un modelo de plasticidad de pequeñas deformaciones y el criterio de von Mises. Se considera la disolución del hierro (ánodo) y la evolución del hidrógeno (cátodo) como reacciones electroquímicas, utilizando expresiones cinéticas que tienen en cuenta el efecto de las deformaciones elastoplásticas.
La geometría del modelo consiste en una tubería de acero de aleación de alta resistencia y el dominio del suelo circundante. La longitud de la tubería es de 2 m y el grosor de la pared es de 19,1 mm. El defecto de corrosión en el lado exterior de la tubería tiene forma elíptica con una longitud de 200 mm y una profundidad de 11,46 mm. Ver Figura 2.
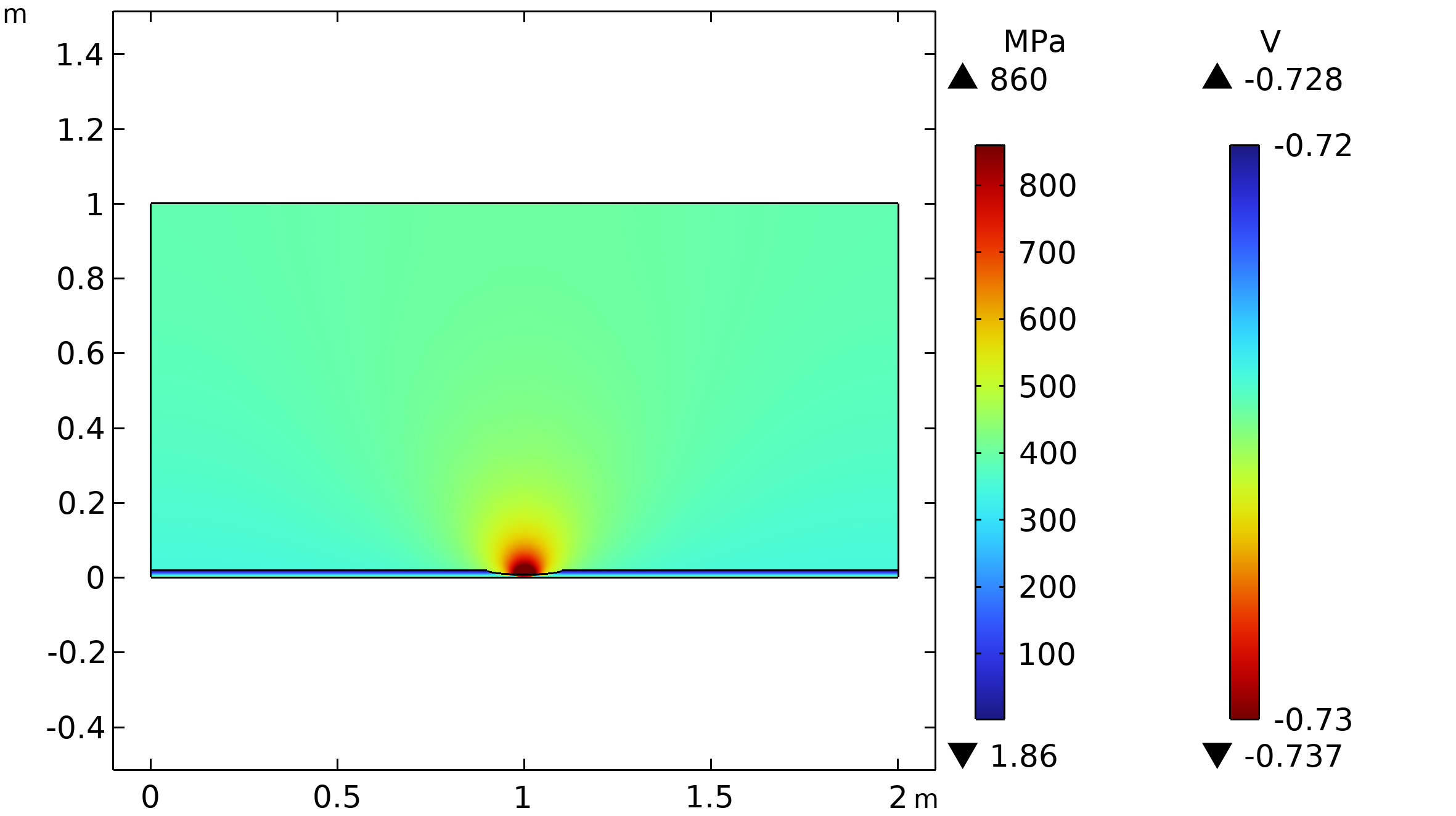
Figura 2: Distribución del potencial electrolítico y distribución de la tensión de von Mises en el dominio de la tubería para un desplazamiento prescrito de 4 mm.
Pitting Corrosion
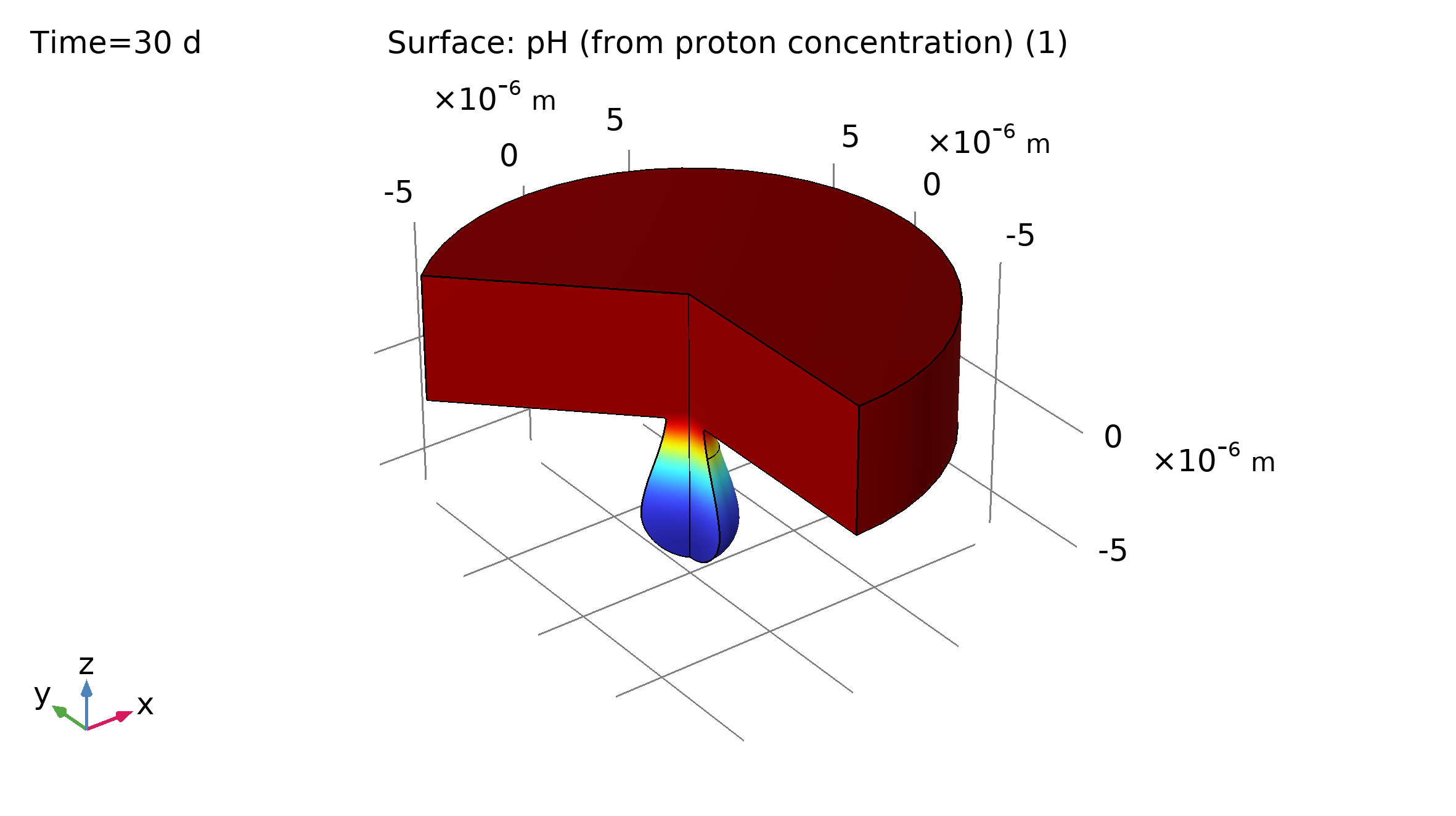
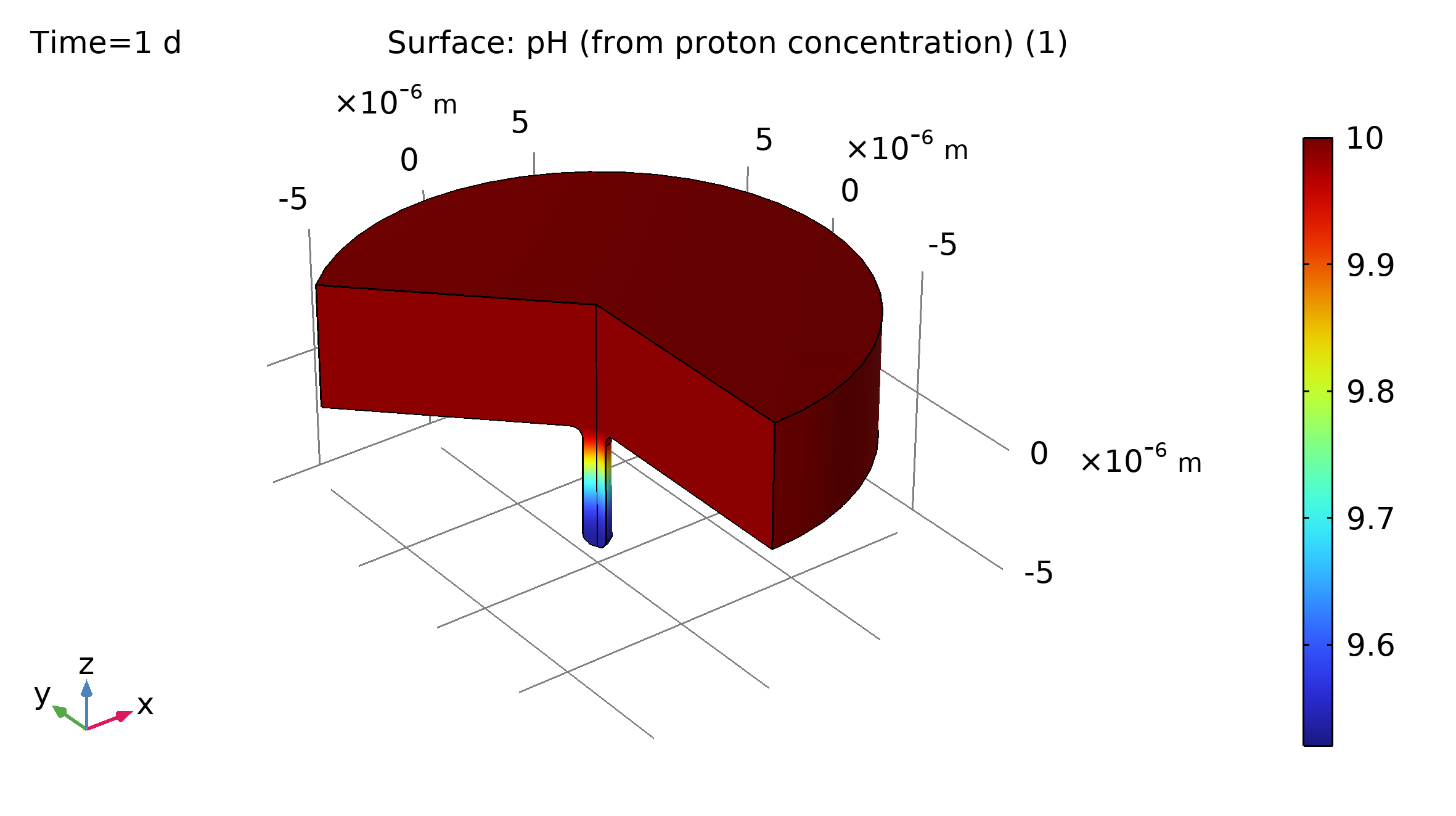
Este ejemplo permite ilustrar la corrosión por picadura. Este proceso es un tipo de corrosión localizada mediante la cual se forman cavidades locales, o picaduras, en una superficie metálica inicialmente lisa. Una picadura puede originarse debido a defectos en la superficie, como inhomogeneidades en la composición o forma, o debido a daños mecánicos que resulten en un pequeño arañazo o abolladura. Cómo crece la picadura depende de varios factores como el tipo de metal, la salinidad, el pH y la temperatura. Una comprensión fundamental del proceso de picado es esencial para una selección adecuada de materiales en entornos propensos a este tipo de corrosión. Este tutorial investiga el mecanismo fundamental de la propagación de las picaduras mediante la simulación de la cinética de electrodos, el transporte de masa, el transporte de carga y la deformación resultante de la geometría. La Figura 2 izquierda muestra el resultado inicial del modelo al día 1, que define una película de electrolito que cubre una superficie de electrodo metálico de hierro. La geometría está definida en 2D con simetría axial. axial.
 |
 |
|
Figura 3: Estado de la corrosión al día 1 (izquierda) y al día 30 (derecha) en términos del pH. |
|
Conclusión
En resumen, Corrosion Module de COMSOL Multiphysics es una herramienta potente para simular y comprender los procesos de corrosión en una amplia gama de aplicaciones. Permite a los ingenieros y científicos modelar, analizar y mitigar eficazmente los efectos de la corrosión en sus diseños y productos, lo que es esencial para garantizar la durabilidad y la integridad de las estructuras y componentes metálicos.
Referencias
[1] Módulo de corrosión de COMSOL Multiphysics
[2] Application Gallery COMSOL: Localized Corrosion Using the Level Set Method
[3] Application Gallery COMSOL: Stress Corrosion
[4] Application Gallery COMSOL: Pitting Corrosion
- Detalles
- Categoría: Lakes
- Visto: 5744
El 23 de octubre de 2023, la Agencia de Protección Ambiental de EE. UU. publicó actualizaciones del modelo de dispersión aérea AERMOD y AERMET, su preprocesador de datos meteorológicos. Los ejecutables del modelo actualizado se han publicado en el sitio web de SCRAM. Consulte las listas al final de esta noticia para obtener detalles sobre los cambios en AERMOD y AERMET.
Las actualizaciones del modelo se publicaron al mismo tiempo que la norma propuesta que notifica al público sobre la intención de la EPA de actualizar la Guía sobre modelos de calidad del aire (Apéndice W de 40 CFR Parte 51). La EPA utilizará la 13ª Conferencia sobre Modelación de la Calidad del Aire como audiencia pública para estas revisiones propuestas. La Conferencia se llevará a cabo los días 14 y 15 de noviembre de 2023 en el campus de la EPA en Research Triangle Park, Carolina del Norte.
Actualizaciones de AERMOD View
El equipo de Lakes Environmental está trabajando arduamente en la implementación de actualizaciones de AERMOD View, AERMET View y la versión paralela de AERMOD (AERMOD MPI) para abordar los cambios incorporados en las versiones del modelo 23132.
Planean lanzar una nueva versión de AERMOD View en las próximas semanas. Permanezca atento a las comunicaciones de Lakes Environmental que anunciarán el nuevo lanzamiento.
Lista de cambios para la versión 23132 del modelo AERMOD:
- Reformulación del tipo de fuente móvil RLINE para que concuerde mejor con los tipos de fuente existentes.
- Esta opción se propone para la reglamentación en la Directriz actualizada.
- Capacidad para tener en cuenta el terreno elevado con los tipos de fuente RLINE y RLINEXT también agregados al modelo.
- Actualizaciones de la formulación de la opción de cribado Tier 3 del Método de Conjunto de Reacciones Genéricas (GRSM) para la conversión de NO2.
- Esta opción se propone para la reglamentación en la Directriz actualizada.
- Adición de varias opciones de modelo experimental/de investigación no predeterminadas (ALPHA):
- Tratamiento para plumas de alta flotabilidad (HBP) que penetran en la parte superior de la capa mixta.
- Meandro de pluma incorporado para los tipos de fuente de área .
- Caracterización de las fuentes de aeronaves como áreas y/o volúmenes que explican la elevación adicional de la pluma.
- Se amplió el archivo de depuración urbana existente para generar perfiles de temperatura y temperatura potencial vertical.
- Corrección de errores y actualizaciones de documentación.
Lista de cambios para la versión 23132 del modelo AERMET:
- Adición del procedimiento de flujo aire-mar del Experimento de Respuesta Acoplada Océano-Atmósfera (COARE) para el procesamiento de la meteorología sobre el agua.
- Se trata de una nueva opción BETA que se propone para su reglamentación en la Directriz actualizada.
- Se agregaron comprobaciones de control de calidad para varias variables de ruta de superficie y en sitio.
- Adición de varios mensajes nuevos de error, advertencia e información.
- Correcciones de errores varias de versiones anteriores
- Detalles
- Categoría: Maple
- Visto: 5582

Tomás Recio, Profesor Magistral de la Universidad Antonio de Nebrija (Madrid) y miembro del grupo de Embajadores de Maple en España, presenta el jueves 26 de octubre, a las 18:30 (horario de España), su ponencia "Measuring with GeoGebra Discovery and Maple the Difficulty of Geometric Theorems" en la Conferencia de Usuarios de Maple 2023 (sección Algorithms and Software):
GeoGebra Discovery es una versión experimental de GeoGebra centrada en el desarrollo de demostraciones y descubrimientos automáticos de enunciados geométricos elementales. Por ejemplo, tiene un comando "Discover" que encuentra automáticamente todas las propiedades de un cierto tipo que se mantienen sobre algún elemento de una construcción. O el reciente comando "StepwiseDiscovery", que descubre automáticamente todos los enunciados que implican a cada uno de los nuevos elementos que el usuario va añadiendo en cada paso de la construcción. O el comando más general de la versión web llamado "Automated Geometer" que encuentra todas las expresiones (a menudo, cientos de ellas) que implican a los diferentes elementos de una figura. Ahora bien, sucede que un gran número de tales enunciados descubiertos son simplemente obvios, ¡como encontrar que el punto medio de un segmento (definido como un punto con coordenadas la mitad de la suma de las coordenadas de los puntos extremos del segmento) es equidistante a ambos extremos del segmento!
En este entorno, muy propenso a producir mecánicamente grandes cantidades de información geométrica, es muy relevante desarrollar instrumentos que permitan a los humanos evaluar la relevancia de los resultados obtenidos y, eventualmente, filtrarlos. En nuestra presentación introduciremos y discutiremos la propuesta de una medida específica de la complejidad (¿o interés?) de un enunciado geométrico, apoyada en la noción de "syzygy" del álgebra conmutativa, y ejemplificaremos su comportamiento, utilizando Maple para realizar los cálculos implicados, a través de una variedad de ejemplos: desde teoremas bien conocidos de los currículos escolares tradicionales, como los teoremas de Pitágoras, o el enunciado que determina la intersección común de las medianas de un triángulo, etc. hasta problemas aparecidos en las Olimpiadas Matemáticas.
Se trata de un trabajo conjunto de Zoltán Kovács (The Private University College of Education of the Diocese of Linz, Linz, Austria), Tomás Recio y M. Pilar Vélez (Universidad Antonio de Nebrija, Madrid, España). Cabe destacar que María Pilar Vélez también pertenece al grupo de Embajadores de Maple en España.
- Detalles
- Categoría: Comsol
- Visto: 6504
La corrosión es un proceso natural que afecta principalmente a los metales debido a reacciones químicas con agentes como el oxígeno, la humedad y sustancias químicas. Estos cambios debilitan los materiales metálicos con el tiempo, lo que subraya la importancia de comprender y prevenir este fenómeno. Herramientas como COMSOL Multiphysics permiten realizar simulaciones avanzadas para predecir y mitigar la corrosión, mejorando la durabilidad y eficiencia en el diseño de componentes y estructuras metálicas.
¿Por qué importa estudiar la corrosión y cómo se previene?
La corrosión se manifiesta de varias maneras, como la formación de óxido en metales ferrosos, la aparición de pátina en metales como cobre y bronce, o la disolución gradual de materiales como aluminio en ambientes ácidos. Esta problemática afecta a la industria, la construcción y muchas otras aplicaciones que involucran metales.
Para prevenir o controlar la corrosión, se emplean diversas estrategias, como aplicar recubrimientos protectores, utilizar aleaciones resistentes a la corrosión, mantener adecuadamente los materiales y gestionar las condiciones ambientales. La comprensión de los factores que contribuyen a la corrosión y la aplicación de técnicas adecuadas son cruciales para preservar la integridad de los materiales metálicos a lo largo del tiempo.
Corrosión y COMSOL Multiphysics
COMSOL Multiphysics es una herramienta esencial para comprender la corrosión y realizar estudios relacionados con la protección contra la corrosión y la electrodeposición. A través de esta plataforma, es posible crear modelos de alta fidelidad que incorporan detalles clave, como la cinética del electrodo para múltiples reacciones competidoras, potenciales mixtos, equilibrio de corriente, carga en el electrolito y las estructuras metálicas, así como el transporte de especies químicas. Dos módulos fundamentales para realizar estos estudios son el "Corrosion Module" [1] y el "Electrodeposition Module" [2].
Además, se pueden abordar estos temas combinando COMSOL Multiphysics con módulos adicionales como el "Battery Design Module" [3], el "Electrochemistry Module" [4] o el "Fuel Cell & Electrolyzer Module" [5]. Esto amplía aún más las capacidades de modelado en el ámbito de la corrosión y la electroquímica.
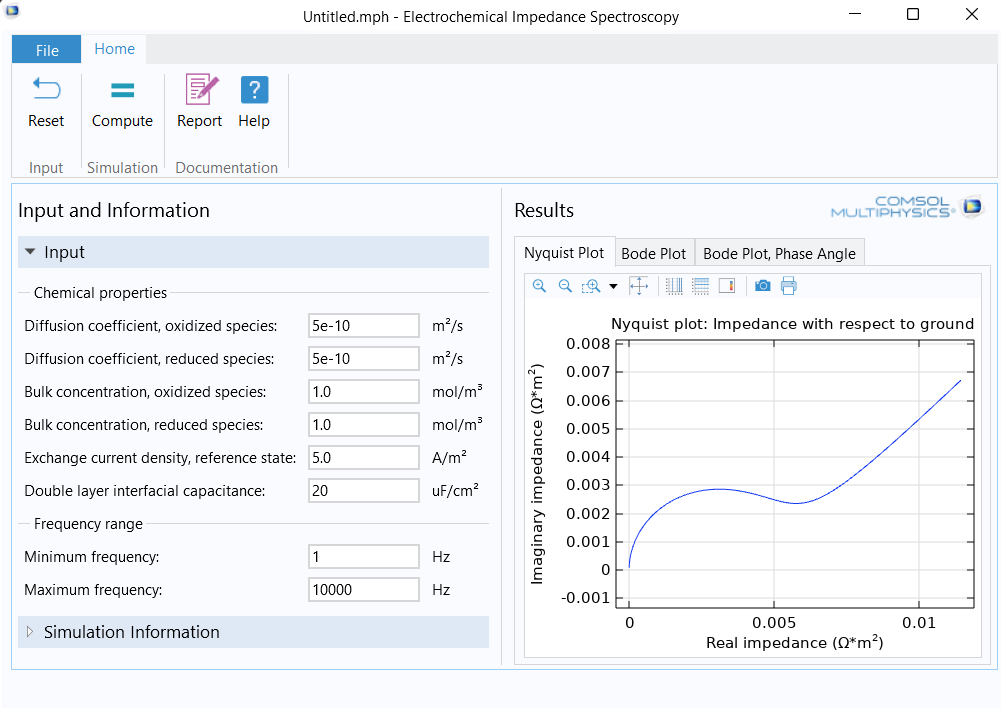
Un ejemplo destacado de aplicación es la técnica de caracterización conocida como "Electrochemical Impedance Spectroscopy (EIS)". Esta técnica se utiliza comúnmente en el electroanálisis para analizar la respuesta armónica de sistemas electroquímicos. Implica la aplicación de una pequeña variación sinusoidal al potencial en el electrodo de trabajo, y la corriente resultante se analiza en el dominio de la frecuencia. Las componentes real e imaginaria de la impedancia proporcionan información valiosa sobre las propiedades cinéticas, de transporte de masa y superficiales de la celda, a través de la capacitancia de doble capa.
Para obtener más detalles sobre el modelado de esta técnica, se puede consultar la referencia [6], que proporciona una aplicación específica para comprender gráficos como EIS, Nyquist y Bode. Esta aplicación permite ajustar parámetros como la concentración aparente, el coeficiente de difusión, la densidad de corriente de intercambio, la capacitancia de doble capa y la frecuencia máxima y mínima, lo que resulta en un enfoque integral para el estudio y comprensión de la corrosión y procesos relacionados en COMSOL Multiphysics. Ver la figura de la cabecera que muestra la app creada por COMSOL App para realizar un estudio de EIS.
Referencias
[1] Corrosion Module
[2] Electrodeposition Module
[3] Battery Design Module
[4] Electrochemistry Module
[6] Application Gallery: Electrochemical Impedance Spectroscopy