- Detalles
- Categoría: Minitab
- Visto: 5292

Óliver Franz.
En la rápida industria de fabricación de vehículos eléctricos (EV), cada decisión tiene su peso. Uno de los elementos más cruciales en la producción de vehículos eléctricos de alta calidad es garantizar la durabilidad y fiabilidad de las baterías de los vehículos.
Aquí es donde el análisis de Weibull interviene como una herramienta potente. Demostraremos cuatro usos clave del análisis de Weibull en la fabricación de baterías para vehículos eléctricos y cómo esta herramienta puede generar dividendos en términos de ahorro de tiempo y costes.
#1: OPTIMIZAR LAS GARANTÍAS
Es importante establecer políticas de garantía adecuadas y realistas para equilibrar las expectativas del cliente y la sostenibilidad financiera. El análisis de Weibull puede ayudar a los fabricantes a estimar la distribución de la duración de la vida útil de las baterías, lo que les permite crear garantías generosas y fiscalmente responsables.
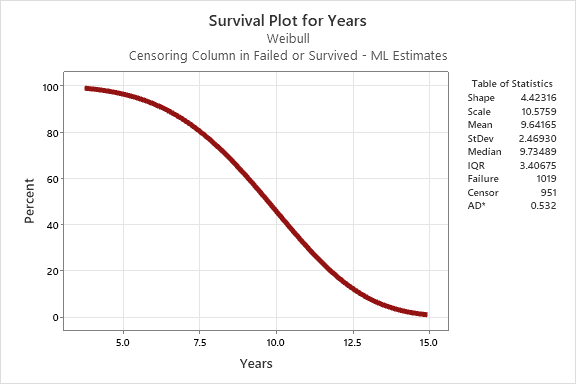
La muestra aquí contiene datos de más de 10.000 baterías. Como se puede ver, más del 95% de las baterías duran al menos 5 años, con una vida media de poco menos de diez años. Esta información puede ayudar a las empresas de vehículos eléctricos a tomar decisiones más inteligentes y mejor informadas.
#2: MEJORAR LA CALIDAD DEL PRODUCTO
Los fabricantes de baterías deben esforzarse continuamente por mejorar la calidad y fiabilidad de sus productos para cumplir con los exigentes requisitos del mercado de vehículos eléctricos. Esto incluye identificar y abordar posibles fallas de diseño, debilidades de materiales o problemas en el proceso de fabricación que podrían provocar un deterioro o falla prematura de la batería.
Por ejemplo, tal vez esté analizando datos de campo e identifique que un modelo particular de batería tiene una tasa de falla más alta de lo esperado debido al sobrecalentamiento durante la carga rápida. El análisis de Weibull se puede utilizar para identificar el modo de falla y trabajar para mejorar el sistema de gestión térmica de la batería, mejorando la calidad y fiabilidad del producto.
#3: REDUCIR EL COSTE DE FABRICACIÓN
Weibull ayuda a reducir los residuos y guiar los procesos de producción que pueden reducir los costes. También puede ayudar a identificar dónde se pueden utilizar sus recursos de manera más eficiente.
El análisis de Weibull puede revelar que un paso de producción específico, como el proceso de llenado de electrolitos, contribuye a las variaciones en la vida útil de la batería. El análisis proporciona información sobre la distribución de la vida útil de las baterías y revela que las inconsistencias en el proceso de llenado de electrolitos pueden generar una mayor probabilidad de fallas tempranas.
#4: ASIGNAR RECURSOS
Weibull puede ayudar a priorizar qué baterías o lotes de productos requieren un seguimiento más estrecho o una mayor investigación, lo que permite una mayor asignación de recursos.
Por ejemplo, en una planta de fabricación, el análisis de Weibull podría ayudar a identificar que una línea de producción particular produce constantemente baterías con una vida útil más corta. El fabricante puede asignar más personal y recursos de control de calidad a esta línea para abordar los problemas lo antes posible y reducir posibles defectos.
- Detalles
- Categoría: Comsol
- Visto: 6203
El número de grados de libertad (DoF, degrees of freedom, en inglés) en un modelo de COMSOL Multiphysics tiene una incidencia significativa y un efecto en el cálculo de un modelo. En esta ocasión, explicamos la importancia de los grados de libertad para un modelo.
¿Qué son los grados de libertad?
En la mayoría de las interfaces físicas, cada variable dependiente está presente en todos los nodos de la malla. Esto significa que el número de grados de libertad corresponde al número de nodos multiplicado por el número de variables dependientes [1].
>#DoF = (# nodos) * (# Variables Dependientes)
¿Por qué importan los grados de libertad?
El tiempo de solución y los requisitos de memoria para calcular un modelo están estrechamente relacionados con el número de grados de libertad del modelo. A menudo es deseable poder estimar el número de grados de libertad basándose en el número de elementos del modelo. La relación entre el número de nodos y el número de elementos depende del orden de los elementos y difiere entre 2D y 3D. La relación es sólo aproximada, ya que depende de la proporción de elementos que se encuentran en el límite de la geometría. Si se desea obtener más información acerca de qué tamaño de modelo se puede resolver con COMSOL, se puede visitar el sitio [2].
Nodos y elementos
Existen relaciones aproximadas entre el número de nodos y el número de elementos en 2D y 3D para elementos de Lagrange de distinto orden. Las mallas cuadriláteras (quad) tienen aproximadamente el doble de nodos que las mallas triangulares, y las mallas hexaédricas (brick) tienen aproximadamente seis veces más nodos que las mallas tetraédricas. Una vez calculado el número total de nodos, se puede calcular el número total de grados de libertad.
El número de elementos de malla del modelo se presenta en la ventana Log cada vez que crea una nueva malla o modifica una existente haciendo clic en el botón Build All. También está disponible a través de la pestaña de la cinta Mesh, en el grupo de la cinta Evaluate, a través del botón Estadísticas. El botón Estadísticas de la pestaña de la cinta Mesh sirve para evaluar rápidamente el número de elementos de malla, entre otras estadísticas de malla, del modelo. Las cantidades respectivas se muestran en la ventana Log. También puede encontrar el número de elementos de malla en el modelo haciendo clic con el botón derecho del ratón en el nodo Mesh y seleccionando Estadísticas.
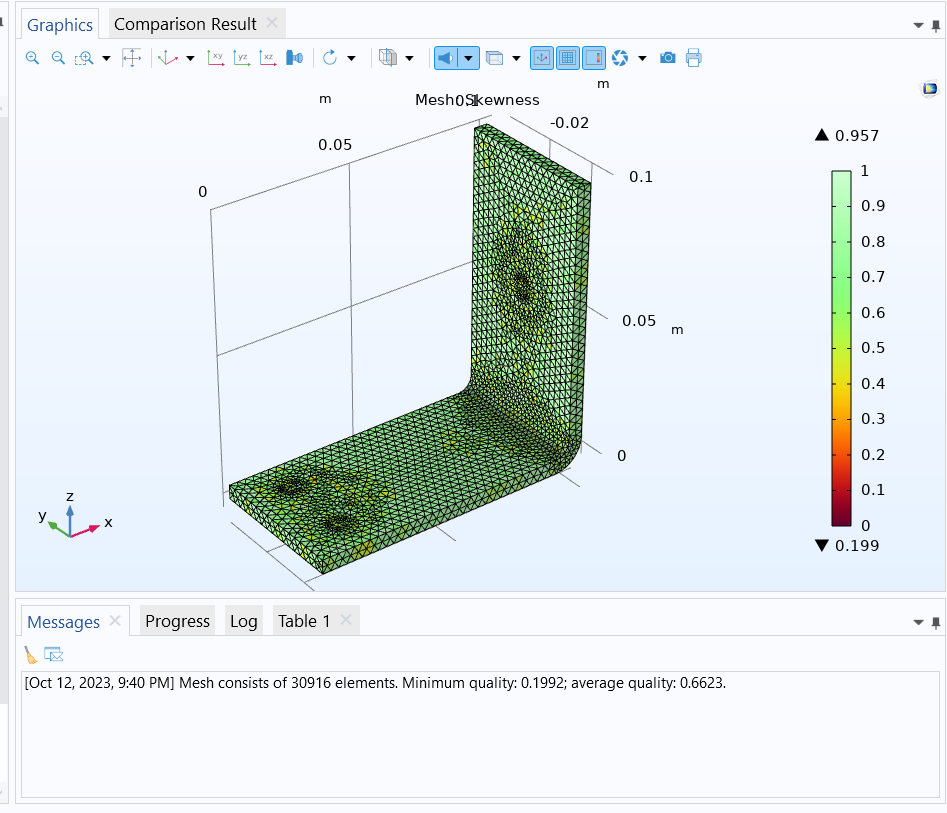
Figura 1: Calidad de los elementos de malla e información desplegada en la pestaña de mensajes: 30916 elementos con una calidad mínima de 0.1922 y calidad promedio de 0.6623.
¿Dónde ver el número de grados de libertad?
Para ver el #DoF de un modelo, primero se deben crear las configuraciones del resolvedor calculando el modelo o haciendo clic con el botón derecho del ratón en Estudio y seleccionando Mostrar solucionador predeterminado. Su estudio contendrá entonces un nodo Compilar ecuaciones para cada paso del estudio. Tras hacer clic con el botón derecho en cualquiera de estos nodos y seleccionando Estadísticas para ver el número de grados de libertad resueltos por el paso de estudio correspondiente. Esto proporcionará una visión general de las variables dependientes y su número de grados de libertad, así como el número total de grados de libertad.
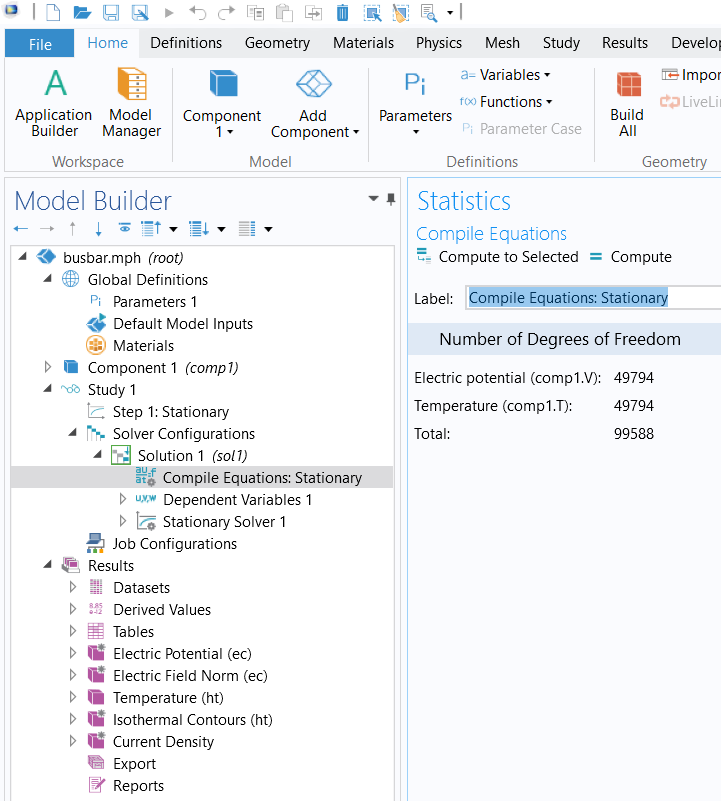
Figura 2: Número de grados de libertad para el modelo busbar con la malla resuelta por defecto del ejemplo creado por COMSOL.
Referencias
[1] Learning Center COMSOL: How to Estimate the Number of Degrees of Freedom in a Model
[2] COMSOL Blog: How Large of a Model Can You Solve with COMSOL®?
- Detalles
- Categoría: Minitab
- Visto: 19021
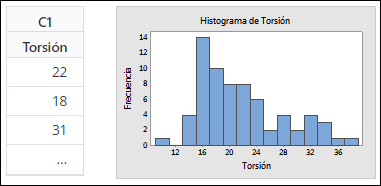
El histograma es una de las herramientas descriptivas básicas para la visualización de variables numéricas, como por ejemplo la longitud de una pieza, el tiempo que transcurre entre la recepción de un pedido y la entrega del mismo, la viscosidad de un producto, o los decibelios de un motor. Un histograma representa la distribución de los datos y se construye representando la escala de la variable numérica en el eje horizontal (eje x) y cortándola en intervalos iguales. Luego se cuentan cuantos valores de nuestros datos hay en cada intervalo y se representa su frecuencia en el eje vertical (eje y) en forma de barra; cuanto más alta es la barra, más frecuentes son los valores del intervalo entre nuestros datos.
¿Es lo mismo un histograma que un diagrama de barras?
Es una confusión habitual, puesto que en ambos gráficos visualizamos barras, pero no son lo mismo. En el histograma, el eje horizontal representa una variable numérica y las barras están pegadas una a la otra, es decir, al terminar una barra, que es un intervalo numérico, enseguida empieza la otra barra, que es otro intervalo numérico a continuación del anterior.
En un diagrama de barras, el eje horizontal representa generalmente categorías que, a pesar de que se puedan ordenar, no tienen una escala o métrica y por eso las barras están siempre separadas las unas de las otras.
A nivel práctico, los dos gráficos se utilizan para conocer cómo se distribuyen los datos de un conjunto de individuos; si a los individuos se les mide una característica como la altura, se utiliza un histograma, y si se les clasifica según la región de nacimiento, se utiliza un diagrama de barras. Con el histograma obtenemos una idea general de cómo se concentran las alturas de los individuos y, con el diagrama de barras, de cómo son las regiones de origen de estos individuos.
En lo que sí se parecen un histograma y un diagrama de barras es en el eje vertical, que en ambos casos representa la frecuencia (cantidad de veces que ese intervalo o categoría se observa entre los datos). La frecuencia se puede expresar en valor absoluto, es decir, mostrando el contaje o número total de valores observados, o en valor relativo, que puede ser el porcentaje o tanto por uno sobre el total.
¿Cómo se usa un histograma?
Mostramos a continuación un ejemplo real de interpretación de un histograma. El departamento de calidad quiere analizar los registros históricos de los datos de fricción de una pieza que tiene un límite de tolerancias de 4.2. 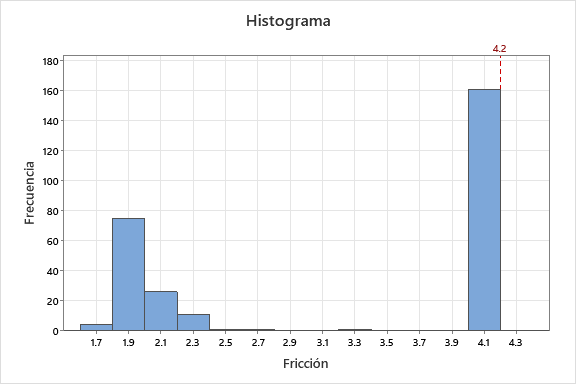 Al realizar el histograma se obtiene el gráfico de la siguiente figura.
Al realizar el histograma se obtiene el gráfico de la siguiente figura.
Se puede apreciar que hay dos bloques de valores. El bloque de la izquierda que tiene forma aproximada de campana y con valores que oscilan entre 1.9 y 2.1. Y el bloque de la derecha con casi todos los valores en 4.1 y con muy poca dispersión. Por el hecho de tener dos bloques de datos tan separados, debemos cuestionar si hay alguna variable, que de momento no consideramos, que separa en grupos la variable fricción.
Además, nos tendría que llamar la atención que el grupo de 4.1 está muy cerca del valor de tolerancias sin superarlo nunca, ya que en realidad se esperaría ver la misma forma de campana de la izquierda replicada en el grupo de 4.1 y, sin embargo, surge una única barra. Esto nos hace sospechar que los datos originales han sido modificados para “hacerlos entrar en tolerancias”.
¿QUIERE MÁS INFORMACIÓN?
Si le apetece indagar más sobre esta herramienta u otras que pueda utilizar para entender e interpretar mejor sus datos, consulte nuestro curso de Diagnóstico con visualización de datos con Minitab.
Si desea recibir una propuesta formal del coste del curso en su caso particular, póngase en contacto con nuestro departamento comercial por teléfono (934154904 o 915158276) o a través de este FORMULARIO
- Detalles
- Categoría: Comsol
- Visto: 6331
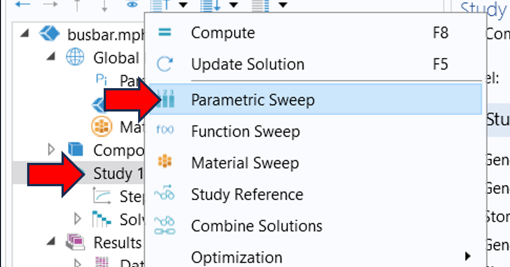
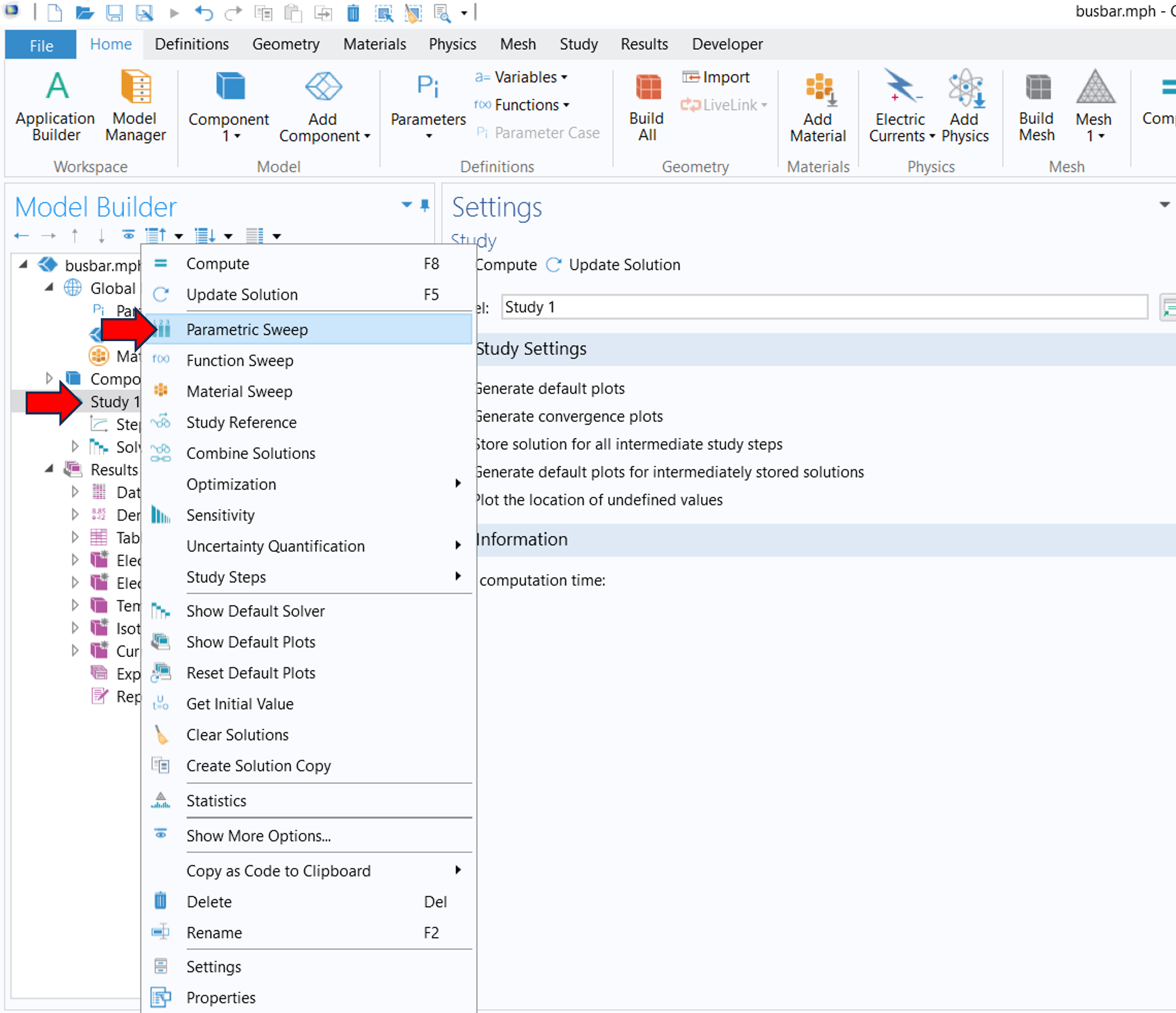
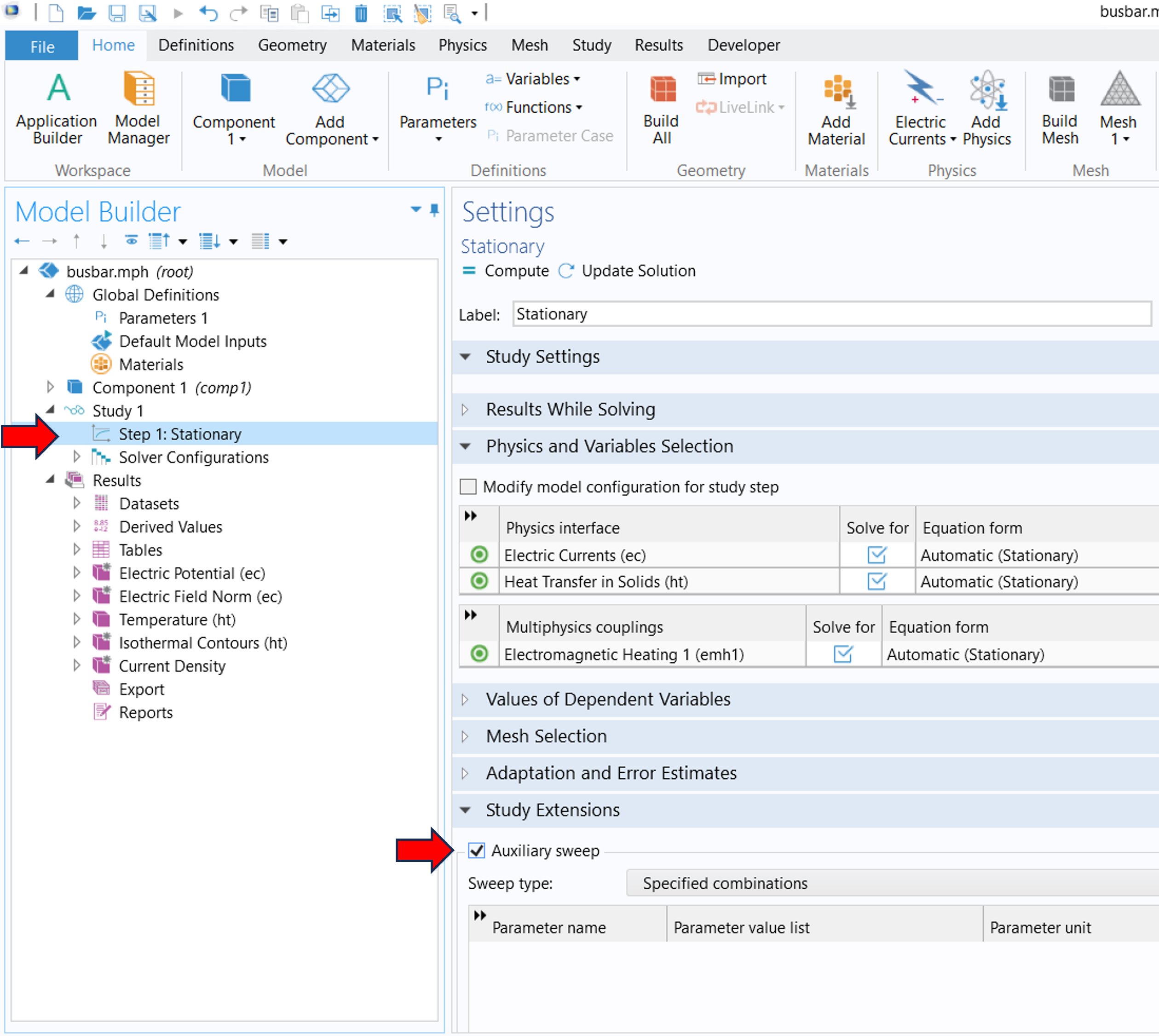
Seguramente nos hemos preguntado sobre la diferencia entre un barrido paramétrico y un barrido auxiliar. En COMSOL esto se conoce como parametric y auxiliary sweep. Esto es lo que comentaremos ahora. El primero tipo de barrido (es decir, el paramétrico) se puede definir bajo el nodo principal del estudio (Study), mientras que el segundo (auxiliar) se define del subnodo Step1 en Study Extensions. Para que se entienda, ver la Figura 1 donde se ilustra dónde están dichas opciones (la imagen de la izquierda muestra dónde se encuentra Parametric Sweep; por otro lado, la imagen de la derecha muestra dónde se puede seleccionar el Auxiliary Sweep).
 |
 |
|
Figura 1. Izquierda: Parametric Sweep bajo el nodo principal Study 1. Derecha: Auxiliary Sweep bajo el subnodo Step 1. |
|
El Barrido Paramétrico utiliza el Parametric Solver con un no continuation algorithm y permite encontrar la solución a una secuencia de problemas estacionarios o dependientes del tiempo que surgen al variar algunos parámetros de interés. Así este enfoque realiza un plain sweep. El barrido paramétrico puede incluir múltiples parámetros independientes directamente para un barrido multiparamétrico completo. Dichos parámetros pueden ser propiedades geométricas como un espesor, la longitud, etc. Se pueden configurar todas las combinaciones posibles. Algunas características adicionales del barrido paramétrico es que se puede realizar de modo distribuido y en modo batch [1]. Por otro lado, el Barrido Auxiliar utiliza un Continuation Algorithm y no permite variar los parámetros de la geometría o de la malla.
La clave para entender las diferencias entre cada tipo de barrido y su aplicación es el concepto de continuación: En el caso del Barrido Auxiliar, éste puede reutilizar la solución para un valor de barrido como valores iniciales para el siguiente valor de barrido. Esto se utiliza sobre todo para la rampa de carga en problemas no lineales [2]. Sin embargo, esto introduce un par de limitaciones. La más notable es que la geometría y la malla no pueden cambiar entre iteraciones. Así que el barrido auxiliar admite continuación, pero el barrido paramétrico permite el remallado entre valores de barrido. El barrido auxiliar también es a veces más rápido porque puede tomar algunos atajos que el barrido paramétrico más general no puede, pero esto no suele ser significativo.
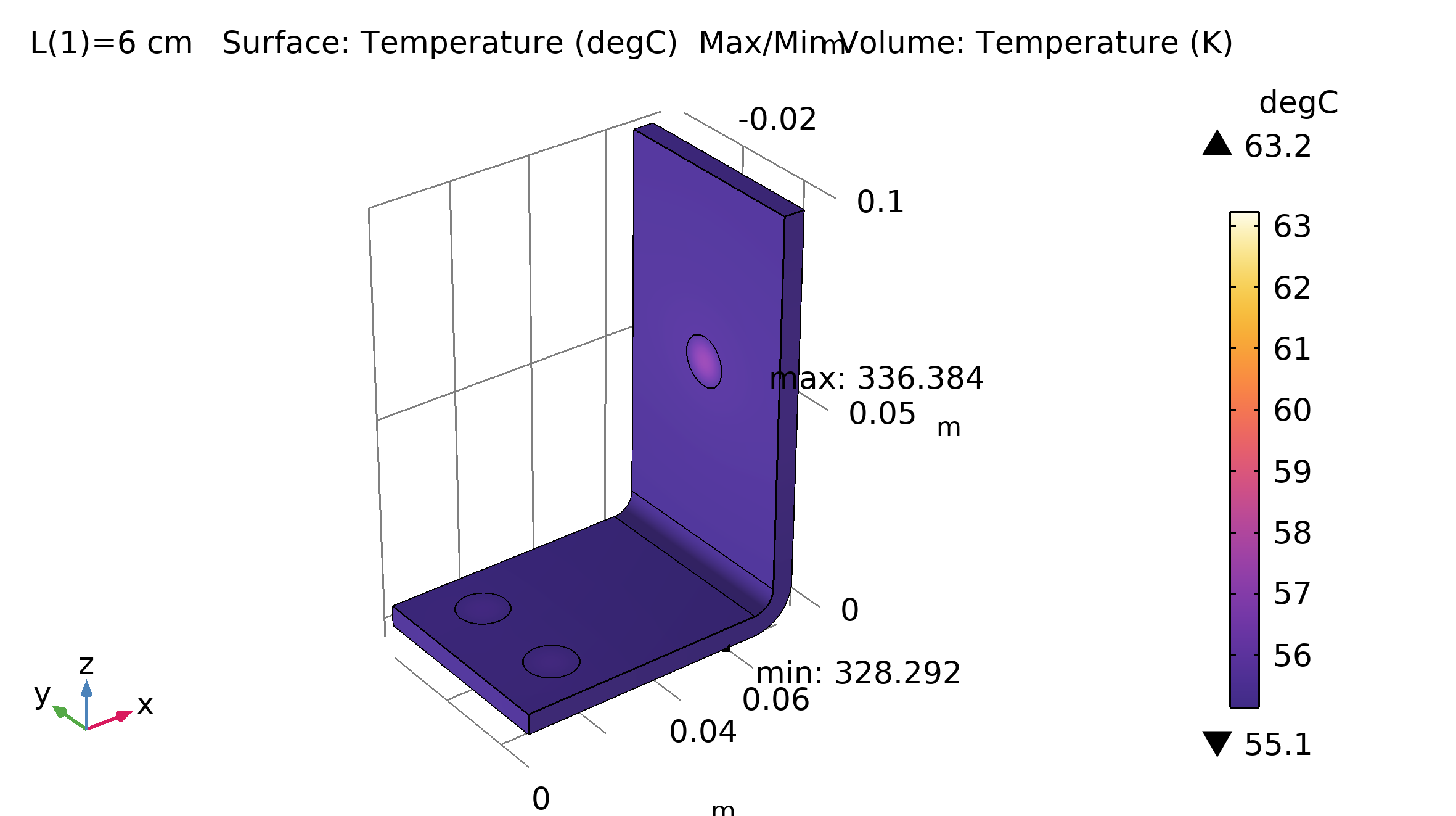
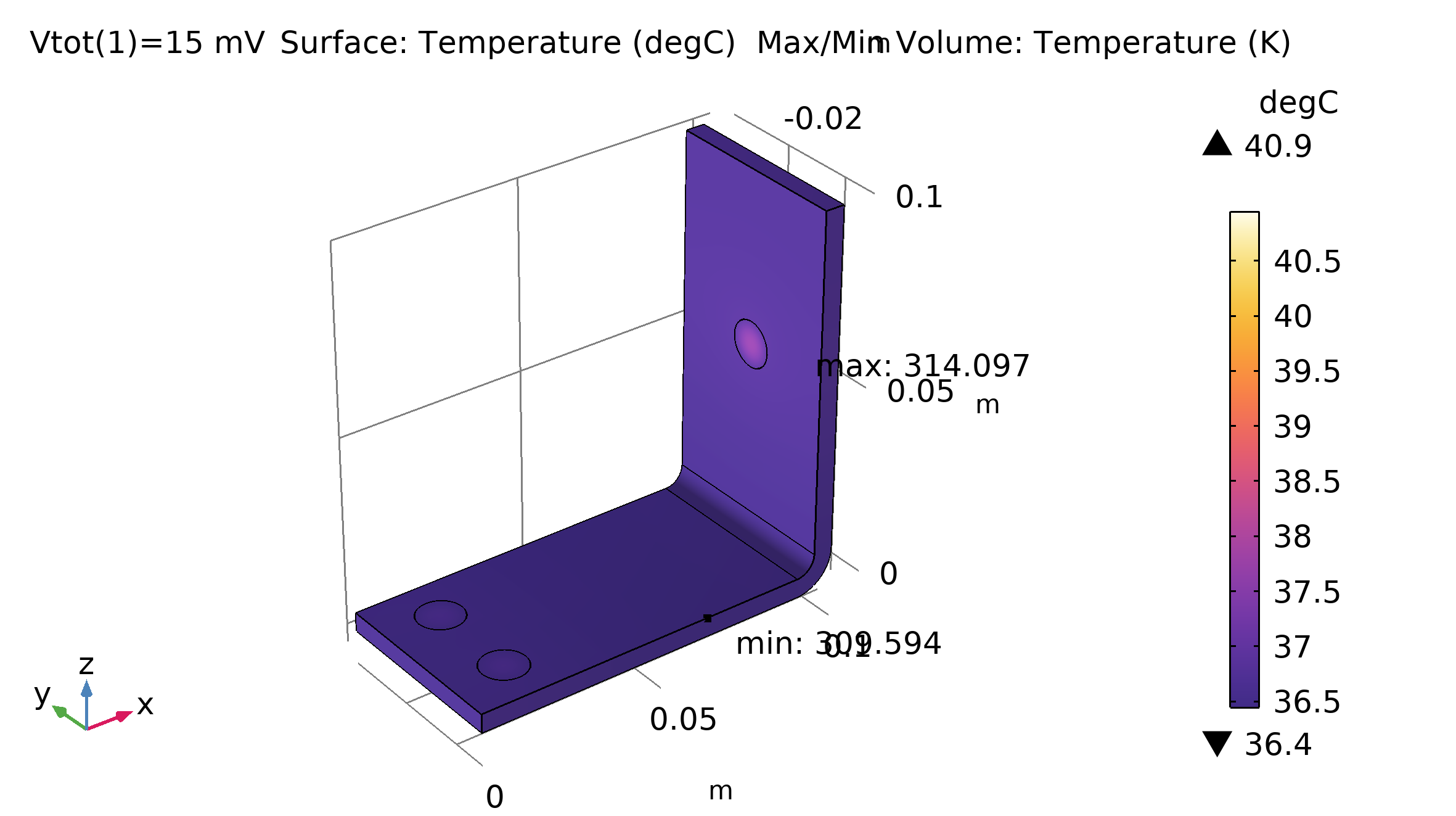
Hemos utilizado el modelo busbar [3] para implementar ambos tipos de barrido. En el caso de barrido paramétrico se ha elegido una longitud (L), mientras que para el barrido auxiliar se ha escogido el voltaje aplicado (Vtot). Esto debido a que sólo el barrido paramétrico admite cambios geométricos. La Figura 2 muestra el resultado tras realizar un barrido paramétrico sobre el parámetro geométrico L. Por otro lado, la Figura 3 ilustra el resultado tras efectuar un barrido auxiliar sobre el parámetro Vtot.
 |
 |
|
Figura 2. Distribución de temperatura y temperatura máxima para L=6 cm (izquierda) y L=12 cm (derecha). |
|
 |
 |
|
Figura 3. Distribución de temperatura y temperatura máxima para Vtot=15 mV (izquierda) y Vtot=25 mV (derecha). |
|
Referencias
[1] Running parametric sweeps, batch sweeps, and cluster sweeps from the command line
[2] Learning Center COMSOL: Improving Convergence of Nonlinear Stationary Models
[3] Application Gallery COMSOL: Electrical heating in a busbar
- Detalles
- Categoría: Minitab
- Visto: 5206
Por Josué Zable.
Según McKinsey & Company, las empresas de semiconductores pueden perder millones de dólares debido a pérdidas de rendimiento. Las pérdidas de rendimiento son las pérdidas que ocurren debido a defectos, reelaboraciones o desechos en la salida de una máquina o proceso.
Hay muchas maneras en que los fabricantes de semiconductores pueden mejorar la calidad y la producción. Sin embargo, dado lo compleja y costosa que puede ser la fabricación de circuitos integrados, es fundamental esforzarse por lograr una mejora continua.
CONTROL DE CALIDAD Y RENDIMIENTO
Se fabrican simultáneamente varios cientos de chips sobre una oblea. No estamos hablando de galletas deliciosas; Una oblea suele ser un trozo de silicio (uno de los semiconductores más abundantes disponibles en el mundo) u otro material semiconductor, diseñado en forma de disco muy delgado. Las obleas se utilizan para crear circuitos electrónicos integrados.
Las obleas se procesan juntas en grupos llamados lotes. Una vez que se completa el proceso de fabricación, cada chip de cada oblea se somete a una serie de pruebas de funcionalidad y se declara que es bueno o defectuoso.
Después de las pruebas, el análisis de los datos para fines de control de calidad y monitorización de procesos generalmente se centra en medidas resumidas generales a nivel de lote, como el rendimiento (la cantidad de chips buenos en un lote) y la relación bueno-funcional (el número de chips buenos en un lote dividido por la cantidad de chips que funcionan pero que no cumplen con los límites de especificación).
Si bien estas medidas son críticas, también suponen que los defectos se distribuyen aleatoriamente tanto dentro como entre las obleas del lote.
Minitab comprende las crecientes necesidades de la industria de semiconductores
CÓMO PUEDE AYUDAR EL MAPA DE OBLEAS
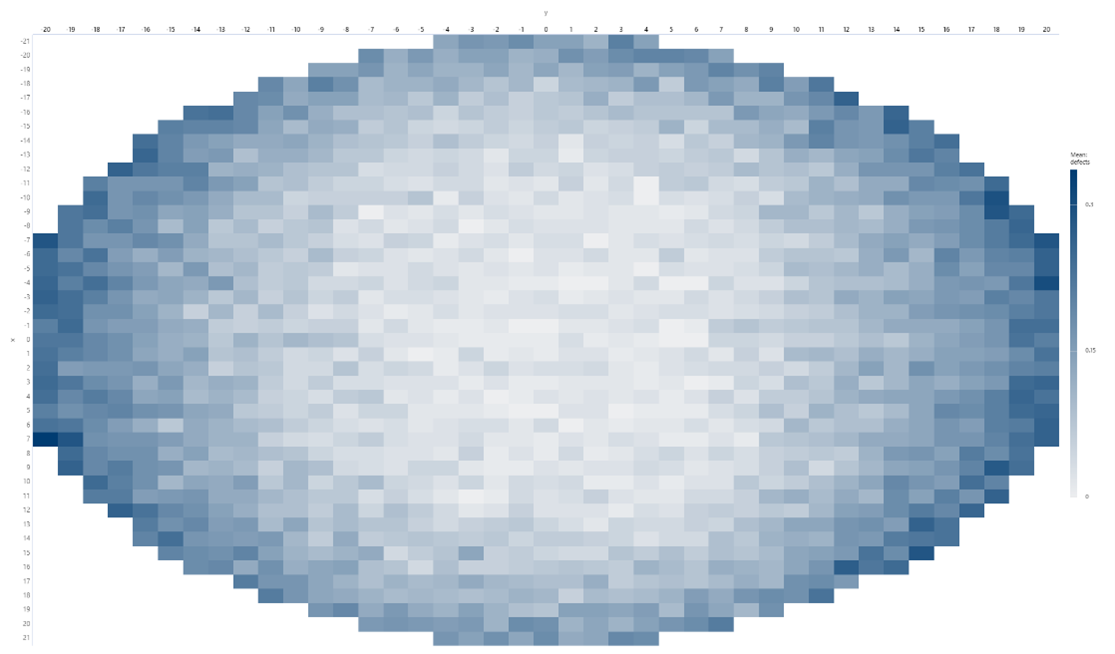
Comprender el rendimiento a nivel de lote y analizar las causas fundamentales es la clave para impulsar mejoras en el rendimiento. Para obtener conocimientos más profundos, mediante el uso de un mapa de oblea, un ingeniero puede visualizar si los chips defectuosos muestran o no un patrón o grupo sistemático.
Estos patrones espaciales pueden contener información útil sobre posibles problemas de fabricación que las medidas resumidas generales pasan por alto. Según Mark H. Hansen, Vijayan N. Nair y David J. Friedman, coautores del artículo “Monitoring Wafer Map Data from Integrated Circuit Fabrication Processes for Spatially Clustered Defects,” patrones específicos pueden indicar problemas comunes. Por ejemplo, si ve un anillo de virutas muertas alrededor del borde de la oblea, esto puede indicar una distribución desigual de la temperatura durante el rápido proceso de recocido térmico. Un patrón de tablero de ajedrez de chips defectuosos a menudo indica un mal funcionamiento del paso a paso. El exceso de vibración en una máquina puede liberar suficientes partículas como para provocar que fallen todos los chips en alguna región contigua de una oblea. En general, los grupos de defectos pueden clasificarse como relacionados con partículas o con procesos, siendo los grupos relacionados con partículas asignables a máquinas individuales y los grupos relacionados con procesos atribuibles a uno o más pasos del proceso que no cumplen con los requisitos de especificación.
En la figura de la cabecera se muestra un ejemplo de un mapa de oblea: el anillo de defectos puede sugerir una distribución desigual de la temperatura. En Minitab Statistical Software.
Por otro lado, los defectos espacialmente aleatorios también pueden contar una historia. Por ejemplo, las densidades aleatorias de defectos tienden a aumentar y disminuir con la limpieza general de la sala blanca. Estos pueden reducirse mediante un programa de mejora continua y gradual a largo plazo o quizás mediante la actualización y revisión de los equipos. Alternativamente, los defectos espacialmente aleatorios pueden indicar que no hay problema con el proceso, sino más bien con los materiales.
EL MAPA DE OBLEAS: UNA IMPORTANTE HERRAMIENTA DE CALIDAD
El control de calidad en un entorno de fabricación complejo también lo es. Debido a la naturaleza costosa de la fabricación de semiconductores, cualquier información adicional que pueda mejorar el rendimiento puede generar importantes ahorros de costos. Wafer Map es una herramienta adicional en el conjunto de herramientas del ingeniero de calidad para identificar las causas fundamentales de los problemas más rápidamente.
- Detalles
- Categoría: Comsol
- Visto: 8408
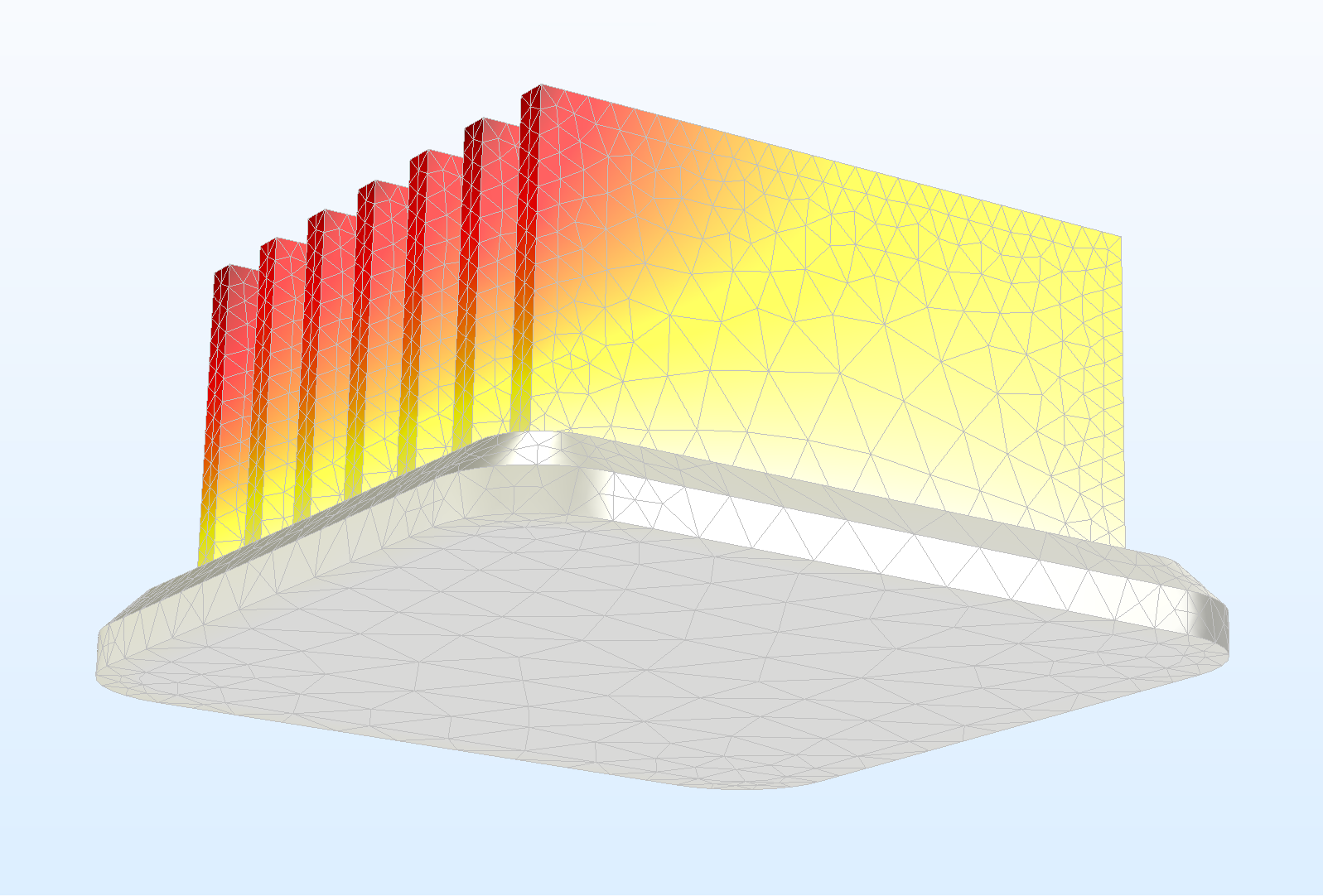
El comportamiento de las variables en un dominio de análisis de elementos finitos suele representarse mediante ecuaciones diferenciales parciales (EDP). La ecuación gobernante del problema físico es una ecuación diferencial parcial. Junto con las condiciones de contorno, se denomina forma fuerte de la ecuación diferencial. En su forma original, la forma fuerte impone requisitos de diferenciabilidad y continuidad a sus soluciones plausibles. Usualmente, la forma fuerte requiere que la solución sea continua y diferenciable al menos hasta la segunda derivada. Por otra parte, la incorporación de las condiciones de contorno es una tarea difícil en la resolución directa de las formas fuertes. El nombre de "forma fuerte" se debe a los requisitos más estrictos sobre la continuidad de las variables de campo. Para abordar estas dificultades, aparece la forma débil.
La forma débil es una manipulación matemática para relajar los requisitos "fuertes" para la solución de una EDP. Notar que la forma débil no significa que la solución sea débil, o que los resultados obtenidos siguiendo este enfoque se desvíen de los resultados reales. La forma débil reduce los requisitos de continuidad de las funciones de base utilizadas para la aproximación, lo que permite utilizar polinomios de menor grado. Esto se consigue convirtiendo la ecuación diferencial en una forma integral que, en comparación, suele ser más fácil de resolver. La formulación débil es una de las razones que explican la técnica ampliamente conocida de aumentar el número de elementos para obtener una mayor precisión en la simulación.
¿Dónde aparece esta cuestión en COMSOL Multiphysics? La respuesta es que COMSOL es un software que se basa en el método de elementos finitos. El proceso es el siguiente: teniendo como punto de partida la ecuación diferencial en derivadas parciales, se transforma a su forma débil resultando en una formulación integral. Una vez conseguido aquello, se discretiza la forma débil para conseguir así el modelo numérico que finalmente resolverá el software.
La figura de cabecera muestra la discretización mediante elementos finitos del modelo Heat Sink por COMSOL INC [3].
COMSOL tiene ya incorporada una variedad bastante grande de ecuaciones físicas y que están organizadas por módulos e interfaces que responden a una física determinada. Por lo tanto, este trabajo de escritura de forma débil no hace falta realizarlo. Sin embargo, en ocasiones puede resultar útil hacerlo manual y efectivamente dicha opción se encuentra disponible. Para ello se recomienda ver las siguientes entradas del blog de COMSOL y el ejemplo adjunto:
- Detalles
- Categoría: Minitab
- Visto: 12564

Por Óliver Franz.
En el dinámico mundo de los servicios financieros, la precisión y la eficiencia son de vital importancia, y las herramientas estadísticas pueden ayudar. Entre estas herramientas se encuentran los gráficos de control que pueden ayudar a los directores de empresas de servicios financieros que buscan monitorizar el rendimiento y navegar por el intrincado terreno de la mejora de procesos.
Exploraremos dos casos de uso en esta publicación de blog que muestran cómo los gráficos de control pueden mejorar el rendimiento del equipo y eliminar riesgos de ciertos procesos prolongados.
CASO DE USO N°1: MONITORIZAR EL RENDIMIENTO DEL EQUIPO
Hay varias herramientas estadísticas localizadas en Minitab que pueden ayudar a monitorizar el rendimiento de su equipo y optimizar sus operaciones de cumplimiento.
Los gráficos de control se pueden utilizar para monitorizar métricas financieras o indicadores de rendimiento para garantizar que cumplan con los requisitos regulatorios más recientes. Por ejemplo, los gráficos de control pueden rastrear índices financieros clave, como índices de adecuación de capital o índices de liquidez, para garantizar que permanezcan dentro de los límites de control. Además, pueden proporcionar información clave sobre las tasas de error con fines de cumplimiento. Este gráfico NP proporciona más contexto:
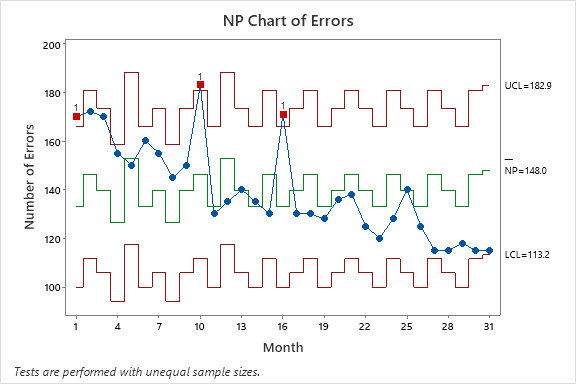
El gráfico NP de errores en esta institución financiera reveló información crucial sobre el rendimiento de la organización durante un período de 31 meses. Dado que enviar transferencias bancarias, responder correos electrónicos y mover capital generalmente requiere el toque humano, es razonable suponer que inevitablemente se cometerán algunos errores. Pero a efectos de cumplimiento, queremos que esos errores sean los mínimos posibles.
Si bien el número total de errores por tamaño de muestra (el tamaño de la muestra dependía del número de transacciones realizadas en cada período, o “eventos”, como correos electrónicos, movimientos de dinero o transferencias bancarias) demostró una tendencia a la baja prometedora, es importante abordar la puntos de fallo específicos en 1, 10 y 16.
Estos puntos de fallo indican desviaciones de los patrones esperados y justifican una mayor investigación. En este caso, se cometieron más errores de los que deberían haberse cometido según el tamaño de la muestra. Para asegurar el cumplimiento y sostener la mejora en las tasas de error, es fundamental realizar un análisis exhaustivo de estos puntos. Este análisis puede implicar examinar las causas subyacentes, identificar posibles variaciones del proceso o factores externos que contribuyeron a las fallas e implementar acciones correctivas apropiadas. Quizás el equipo tenía poco personal, estaba implementando un nuevo proceso o estaba demasiado fatigado. El conocimiento de estos factores subyacentes puede ayudar con futuras acciones correctivas, como agregar personal adicional o mejorar la capacitación.
Al abordar las causas fundamentales de las fallas de las pruebas y tomar de manera proactiva las medidas necesarias, la institución financiera puede refinar sus esfuerzos de cumplimiento, minimizar los errores y mantener una tendencia constante de mejora a lo largo del tiempo.
CASO DE USO Nº2: GESTIÓN DEL RIESGO DE APROBACIÓN DE PRÉSTAMOS Y MEJORA DE PROCESOS
Mitigar el riesgo es de vital importancia en el sector financiero. Un excelente ejemplo de esto es el tiempo de respuesta a la aprobación de préstamos, donde los gráficos de control ofrecen una solución potente para reducir el riesgo y agilizar los procesos. Un tiempo de respuesta lento puede amenazar las oportunidades comerciales y provocar la insatisfacción del cliente.
Imaginemos al director de una empresa de servicios financieros centrándose en optimizar su proceso de aprobación de préstamos. Su objetivo es doble: garantizar el procesamiento oportuno de las solicitudes y, lo que es más importante, cumplir con los requisitos reglamentarios. Para lograr esto, se aprovechan los gráficos de control para monitorizar el tiempo de respuesta.
Al compilar los datos iniciales y configurar los gráficos de control, el equipo mantiene el gráfico con datos nuevos (esto se puede hacer automáticamente con Minitab Connect). Durante el análisis, el equipo detecta una tendencia recurrente en la que los tiempos de aprobación superan constantemente el límite superior de control.
Como se mencionó anteriormente, esto señala un riesgo: los retrasos persistentes en la aprobación de categorías de préstamos específicas podrían generar insatisfacción de los clientes, perspectivas comerciales perdidas y posibles incumplimientos de los plazos regulatorios.
A través de un análisis exhaustivo, el gestor señala que documentos específicos de solicitud de préstamo requieren pasos de verificación adicionales, lo que provoca retrasos notables. Además, se conoce una distribución desigual de la carga de trabajo entre los procesadores.
Con el poder de esta información, pueden optar por implementar mejoras en los procesos. Estas incluyen simplificar la verificación de documentos, redistribuir la carga de trabajo y ofrecer capacitación adicional a los procesadores de préstamos.
A medida que realice cambios en el proceso, sus límites de control cambiarán. Después de estos cambios, el equipo realiza un seguimiento continuo de los cambios del gráfico de control en una nueva etapa con límites de control actualizados. A medida que los ajustes entran en vigor, el equipo observa un retorno gradual de los tiempos de aprobación de préstamos dentro de los límites de control. Esto constituye una prueba de una gestión eficaz de los riesgos y una mayor eficiencia operativa.
CONCLUSIÓN
A través de la lente de dos ejemplos impactantes, hemos sido testigos de cómo los gráficos de control refuerzan el rendimiento del equipo y mitigan el riesgo. Al aprovechar los conocimientos basados en datos, las instituciones financieras pueden navegar por las complejidades del cumplimiento, minimizar errores e impulsar mejoras continuas, ayudándolos en su camino hacia una eficiencia y resiliencia óptimas.