- Detalles
- Categoría: Minitab
- Visto: 5389

Con Minitab es fácil crear gráficos y genstionar datos numéricos, fechas y textos. Ahora las funcionalidades de manipulación de datos mejoradas de Minitab 17.2 hacen todavía más fácil trabajar con datos de texto.
En esta serie de tres entradas del blog de Minitab vamos a dedicarnos a varias herramientas de Minitab que son de utilidad cuando se trabaja con datos textuales. Veremos por orden el análisis del uso de la Calculadora, el menú Data y el menú Editor.
- Detalles
- Categoría: Comsol
- Visto: 5289

Las applications de COMSOL Multiphysics son el motivo principal de la portada del ejemplar de abril de la revista Desktop Engineering
Además de la portada, COMSOL tiene un gran protagonismo en este ejemplar:
- Editorial en la página 2
- Destacado en la tabla de contenidos en página 4
- Artículo principal "The 'Appification' of Simulation" en página 14
- Artículo "Powering Up Battery Design with Multiphysics Simulation" en página 25
- Detalles
- Categoría: Comsol
- Visto: 15732

por Phillip Oberdorfer
Los motores Stirling, o bombas de calor, son sistemas que son capaces de trabajar con diferencias de temperatura increíblemente bajas. De hecho, algunos tipos de motores Stirling solo necesitan el calor del cuerpo humano para funcionar. En esta entrada del blog de COMSOL se explora la dinámica de esta interesante máquina que se puede construir en casa para demostrar cómo modelarla utilizando COMSOL Multiphysics.
Aplicaciones modernas para una idea bastante antigua
Empecemos dando un paso hacia atrás en la historia del motor Stirling. Denominado el "motor del futuro", el motor Stirling fue desarrollado por Robert Stirling hace cerca de 200 años en 1816. Aunque la tecnología nunca llegó a la cima, este tipo de motor de calor ha encontrado uso en muchas aplicaciones modernas. Por ejemplo, el motor Stirling solar se utiliza para transformar directamente el calor solar en energía mecánica, lo que a su vez se utiliza para alimentar un generador y producir energía eléctrica. Además, existen aproximaciones análogas que están basados en la energía geotérmica o utilizan el calor residual industrial. La aplicación moderna más asombrosa del motor Stirling puede ser su uso en los submarinos suecos — la ausencia de aire no es un problema para un propulsor Stirling.
- Detalles
- Categoría: Comsol
- Visto: 20360

por Brianne Costa
Pruebe de escanciar algo de vino en una copa. No se la beba todavía — es para un experimento científico. Cuando levante la copa, verá lo que parecen lágrimas bajando por los lados. Estas lágrimas de vino son causadas por el efecto Marangoni, que describe una transferencia de masa en la superficie de dos fases de fluido cusadas por los gradientes de tensión superficial en la interfaz entre dos fases (por ejemplo líquido y vapor).
Lágrimas del vino
El término lágrimas del vino fue acuñado por primera vez en 1865 por el físico James Thomson, el hermano de Lord Kelvin. Más tarde, el físico italiano Carlo Marangoni estudió el tema para su investigación doctoral y publicó sus resultados en 1865. El efecto Marangoni, que causa las lágrimas del vino y otros fenómenos observados en química de superficie y flujo de fluidos, recibieron el nombre de Marangoni y su investigación.
Lágrimas del vino bajando por el interior de la copa.
- Detalles
- Categoría: Comsol
- Visto: 6931
¿Desea compartir sus simulaciones con todo el mundo o simplemente con su propio equipo? Después de construir una aplicación con Application Builder en el software COMSOL Muliphysics®, puede compartir su app utilizando una licencia de COMSOL Server™ con cualquiera, ya sean colegas o clientes. Aquí le proporcionamos una introducción a COMSOL Server™ - qué es, por qué utilizarla, y una breve supervisión de cómo empezar a usarlo.
¿Qué es COMSOL Server™?
COMSOL Server™ es una potente herramienta que le permite compartir simulaciones.
Todo empieza con el software de simulación COMSOL Multiphysics. Como experto en simulación, Vd. puede crear las simulaciones que necesita con COMSOL Multiphysics y transformarlas en apps con Application Builder. Puede incluir únicamente la información relevante para el usuario y excluir cualquier cosa innecesaria. De esta manera los usuarios de su aplicación simplificada tendrán una interfaz más fácil en la que trabajar.
Antes de que otros puedan aprovechar su aplicación, necesitarán acceder a ella. Aquí es donde COMSOL Server™ juega su papel.
La persona responsable de distribuir las aplicaciones comprará una capacidad de licencias para cada usuario de app. Dependiendo de su situación, que puede ser cliente, ingeniero, trabajador de la fábrica, o cualquiera que no sea un usuario de COMSOL Multiphysics pero pueda utilizar las simulaciones. Por ejemplo, si Vd. dispone de cuatro ingenieros que necesitan utilizar su app, comprará cuatro licencias de COMSOL Server™. Ahora cada ingeniero podrá correr su app - así como otras tres apps al mismo tiempo.
¿Por qué debería de utilizar COMSOL Server™?
Con COMSOL Server™ las posibilidades son ilimitadas. Lo que Vd. haga es su decisión. No importa lo que haya creado, COMSOL Server™ le simplifica el proceso de distribución de sus apps de simulación.
Antes de la aparición de COMSOL Server™, únicamente aquellos con conocimientos de COMSOL Multiphysics podían correr simulaciones utilizando nuestro software. La tarea de volver a trabajar la simulación cuando se descubrían nuevos datos y compartir los nuevos resultados recaía en el ingeniero de simulación. Ahora puede crear una app que permita a la gente sin conocimientos de simulación hacer el trabajo por ellos mismos.
Digamos que Vd. es un experto en simulación y trabaja en una empresa que construye automóviles. Utilizando sus conocimientos de COMSOL Multiphysics crea una app basada en los modelos que más utiliza. Un día, su empresa decide crear un innovador automóvil eléctrico. Los ingenieros quieren estudiar diferentes materiales y aleaciones para el chasis, pero pueden no tener los conocimientos de simulación para trabajar con COMSOL Multiphysics. En su lugar, ellos pueden simplemente abrir COMSOL Server™ y filtrar las aplicaciones para encontrar lo que ellos necesitan. En este caso, buscarían una aplicación en la categoría de materiales. Después de escoger la aplicación que quieren, pueden simular cómo afectan los diferentes materiales al chasis del automóvil. Si utilizan esta aplicación a menudo, pueden hacerla favorita para tener incluso un acceso más rápido.
Con COMSOL Server™, puede compartir una app que capacite a la gente para utilizarla para obtener los resultados ellos mismos. Esto ahorra tiempo y permite que el conocimiento y la especialización se distribuyan más fácilmente entre diferentes miembros del equipo, departamentos, y empresas.
Breve introducción a la utilización de COMSOL Server™
COMSOL Server™ es muy versátil. Puede utilizarse para acceder a aplicaciones de simulación en el ordenador así como en otros dispositivos, como teléfonos inteligentes y tabletas. Esto le permite llevar su app consigo a donde vaya. Existen do maneras principales de correr aplicaciones con COMSOL Server™:
- En un navegador web
- En COMSOL Client
Correr COMSOL Server™ en un navegador web
Correr COMSOL Server™ en un navegador web tiene muchas ventajas. Puede acceder a él en la mayoría de navegadores de internet, incluyendo Google Chrome™, Firefox® Safari® e Internet Explorer®. Esto significa que puede llevar su app a cualquier sitio y utilizarla en diferentes tipos de dispositivos sin tener que descargar nada.
Sin embargo, existen algunos inconvenientes. Cuando se corre COMSOL Server™ en un navegador, no se tiene acceso a algunas funcionalidades como los productos LiveLink™ para software de CAD. Además los teléfonos móviles y tabletas pueden tener mayores limitaciones. Todo esto son cosas a tener en cuenta cuando se escoge el mejor método para cada usuario.
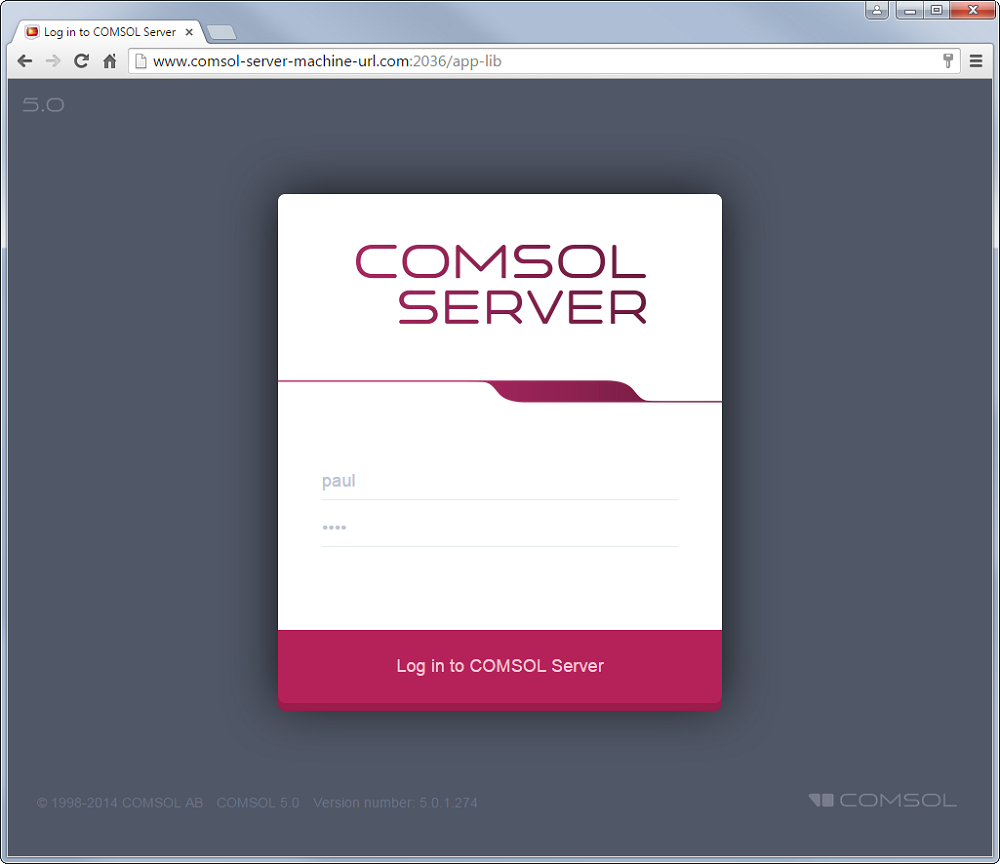
Para correr una aplicación en un navegador web, se hace clic en un enlace que alguien proporciona o directamente se entra en la dirección web de una interfaz web de COMSOL Server™ en la barra de dirección del navegador. La dirección usualmente será el nombre del ordenador y el número de puerto de la interfaz web. Por ejemplo, si el número de puerto es el 2036, se deberá de entrar la información tal y como sigue:
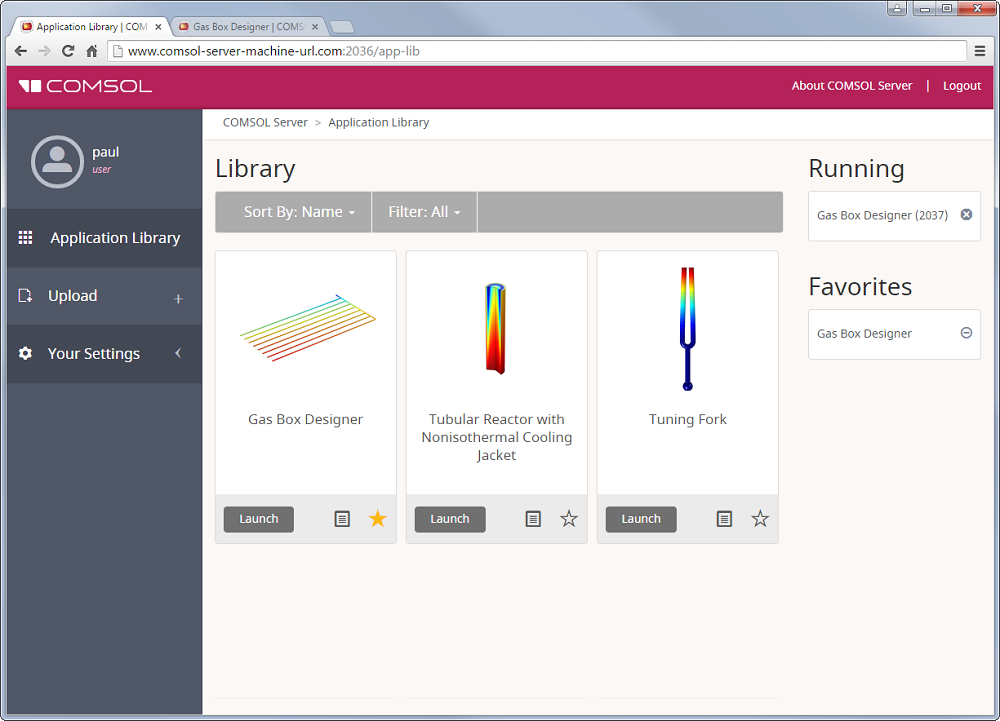
Desde esta pantalla, se necesita identificarse para acceder a la página de la Librería de Aplicaciones. Una vez realizado esto, se verá una lista de las apps disponibles en su librería. Simplemente escoja la aplicación que quiera correr y haga clic en el botón Launch para abrirla en una nueva pestaña, como se ve más abajo.
Correr COMSOL Server™ en COMSOL Client
Una alternativa a utilizar un navegador web es COMSOL Client para el sistema operativo Windows®. Este producto se puede descargar o instalarlo junto con COMSOL Server™. COMSOL Client corre en Windows® y proporciona un rendimiento gráfico superior y la capacidad de utilizar los productos LiveLink™. Tenga en cuenta que este método sólo puede ser utilizado en Windows®.
Para correr una aplicación utilizando este método, abra COMSOL Server&trade, y entre su información de usuario.
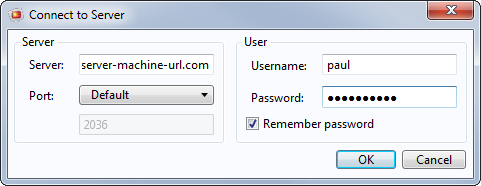
Esto le llevará a la misma página de Librería de Aplicaciones, como se vió en la opción del navegador web. La única diferencia es que este método hará que cualquier app que se corra se vea como un programa Windows. Ahora tendrá acceso completo a su Librería de Aplicaciones y simplemente tendrá que seleccionar la app que desea utilizar.
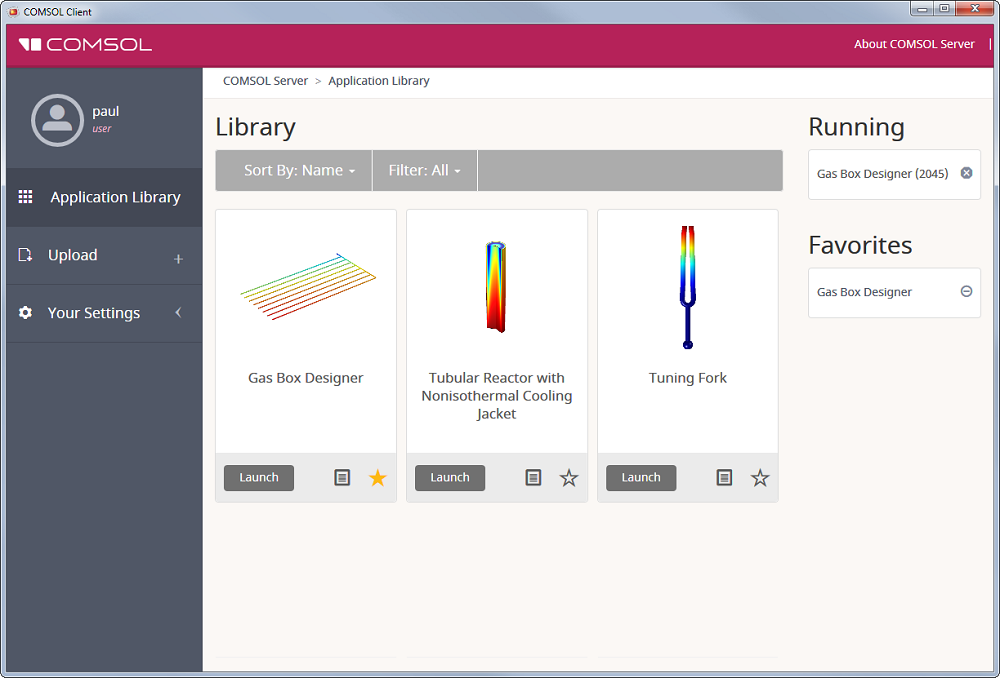
Siguentes pasos
Una vez que se identifica y entra en su cuenta de COMSOL Server™, puede filtrar sus aplicaciones para encontrar lo que esté buscando. Si una app es particularmente importante para su trabajo, puede hacerla favorita. Como administrador, puede monitorizar su licencia y controlar quién puede acceder a sus aplicaciones.
Hay un montón de cosas que puede hacer con COMSOL Server™.