
ChemOffice Professional

Soluciones innovadoras para el laboratorio electrónico de químicos y biólogos.
Witness

Simulación de procesos logísticos y de fabricación.
Maple

Herramienta matemática estándar para el cálculo analítico que permite realizar álgebra simbólica, cálculo numérico, resolver ecuaciones diferenciales, gráficos y animaciones.
COMSOL Multiphysics
Herramienta de modelado y análisis para prototipaje virtual de fenómenos físicos.

SU PROVEEDOR LÍDER DE SOFTWARE CIENTÍFICO Y TÉCNICO
Soluciones Minitab

Herramientas de análisis de datos y mejora de procesos para la excelencia empresarial.
Biovia

Entorno de colaboración científica para experiencias biológicas, químicas y de materiales avanzados.
NAG

Librerías de algoritmos numéricos de funciones matemáticas y estadísticas para desarrollo de eficientes aplicaciones.
Miércoles, 24 Abril
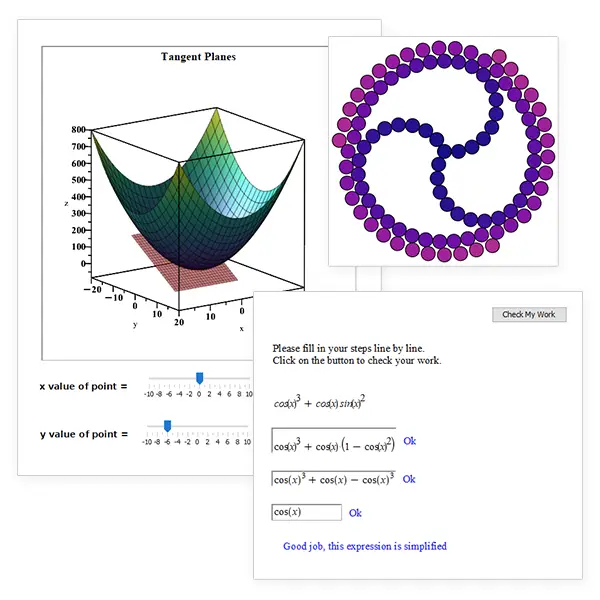
Maple
Maple 2024 incluye muchas mejoras para respaldar la enseñanza y el aprendizaje de las matemáticas, la ingeniería y las ciencias, incluidas herramientas para ayudar a los estudiantes cuando se quedan atascados en un problema. Maple puede proporcionar soluciones paso a paso para resolver ecuaciones, diferenciación, integración, inversión de matrices y más. En Maple 2024, esta colección se ha...
Martes, 23 Abril
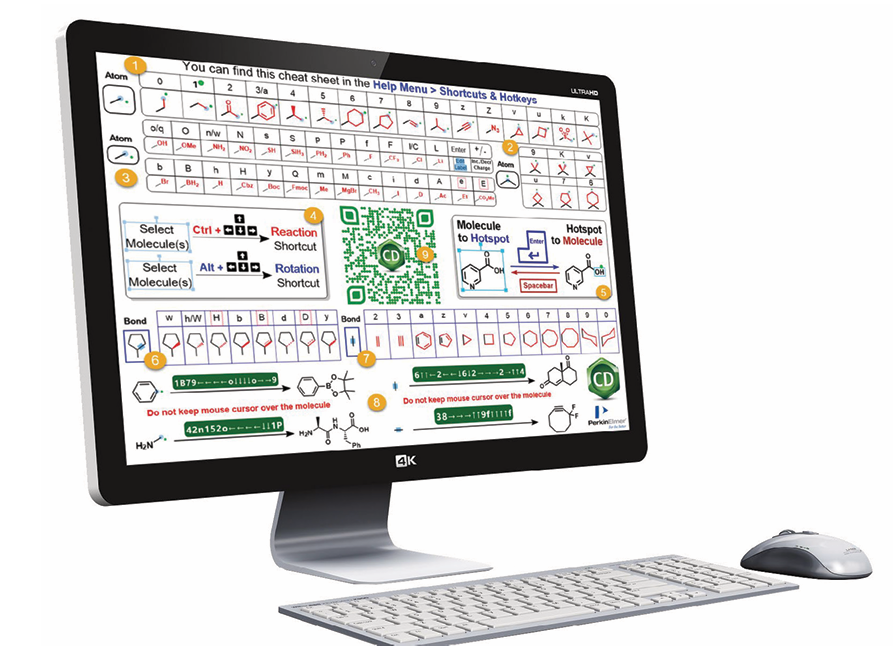
ChemOffice
“¡He estado usando ChemDraw® durante n años! Sé cómo usarlo” "(5 < n < 35)…” … es el comentario más frecuente que se escucha cuando hablamos con los usuarios de ChemDraw en reuniones de grupos de usuarios o visitas a empresas o universidades. Esto es ANTES de que un mago (también conocido como experto) dé una demostración real de lo que ChemDraw REALMENTE puede hacer. ¿Comprobamos cuántos de...

Martes, 23 Abril
Minitab
Minitab, LLC, ha anunciado que ha alcanzado el estatus de socio de SAP en el programa SAP® PartnerEdge®. Esta es una clara indicación del alto nivel de calidad que Minitab, LLC ofrece a las empresas que utilizan soluciones SAP. Jeff Slovin, presidente y director ejecutivo de Minitab, dijo: “Nuestra asociación con SAP® resalta la necesidad de que las soluciones líderes de Minitab ayuden a las...
![Imagen facilitada por Carol Ostojic [https://www.linkedin.com/in/carol-ostojic-18267464/]](/images/productos/comsol/2024/microalgas.png?6627b0bc)
Jueves, 18 Abril
Comsol
El estudio "New mechanistic model to simulate microalgae growth", publicado en Algal Research (ElSevier) [1], presenta un innovador enfoque para simular el crecimiento de microalgas , desarrollado por Alessandro Solimeno y colaboradores. El objetivo principal del estudio fue desarrollar un modelo mecanicista que pueda predecir con precisión el crecimiento de microalgas en diferentes condiciones...
Empresa | Aviso Legal | Política de Privacidad | Política de Cookies
© Copyright 1994 - 2023. Addlink Software Científico, S.L.